6.4 高度な輻輳制御
本節では輻輳制御をさらに細かく見ていく。前節で見た標準 TCP (standard TCP) の戦略は「輻輳が発生したら輻輳ウィンドウの制御を行う」というものであり、輻輳を一度も起こらないようにするものではない。標準 TCP は輻輳が起こるまでネットワークにかける負荷を増加させ、輻輳が起こると負荷を大きく下げる動作を周期的に繰り返す。言い換えれば、標準 TCP は接続で利用可能な帯域を推定するためにパケットロスを必要とする。これとは異なる魅力的な選択肢として、どの程度の負荷で輻輳が起こるかを予測し、輻輳が起きてパケットが破棄され始める直前に送信ペースを落とす戦略が考えられる。このような戦略を輻輳回避 (congestion avoidance) と呼んで輻輳制御 (congestion control) と区別するが、「回避」は「制御」の一種だと考えた方が正確だろう。
これから輻輳回避のアプローチを二つ紹介する。一つ目のアプローチは輻輳が発生したときにエンドノードを補助する小さな機能をルーターに追加するものであり、しばしば AQM (active queue management, アクティブキュー管理) と呼ばれる。二つ目のアプローチはエンドホストだけで輻輳回避を行う。この二つ目のアプローチは TCP で実装されているので、前節で見た輻輳制御の仕組みの一種と言える。
6.4.1 AQM (DECbit, RED, ECN)
一つ目のアプローチではルーターに変更が必要になる。これは新機能を追加する方法としてインターネットに好まれるものでは決してないにもかかわらず、このアプローチは過去二十年に渡って驚くような結果を何度も生んでいる。問題は、輻輳が始まりそうかどうかを観測する理想的な位置にいるのはルーターであることには一般に合意がある ── ルーターは自分のキューの長さを見ればいい ── のに対して、ルーターで実行すべきアルゴリズムについてはコンセンサスが存在しないことである。これから二つの古典的な仕組みを紹介し、最後に現在使われている仕組みを簡単に議論する。
DECbit
一つ目の仕組みは DNA (Digital Network Architecture) での利用のために考案された。DNA はコネクション指向のトランスポートプロトコルを持ったコネクションレスネットワークなので、この仕組みは TCP と IP にも適用できる。先述したように、輻輳制御の責任をルーターとエンドノードで分割することがこのアプローチの基本的な考え方となる。各ルーターは自身の負荷を監視し、輻輳が起こりそうになった場合はエンドノードにそれを通知する。この通知はルーターを通るパケット内の特定のビットを設定することで行われ、この輻輳の有無を示すビットを DECbit と呼ぶ。DECbit が設定されたパケットを受け取った宛先ホストは DECbit を設定した ACK を送信元に送り返し、最終的に送信元は輻輳を回避するために送信レートを調整する。以降ではアルゴリズムの詳細を説明する。まずルーターで何が起こるかを説明しよう。
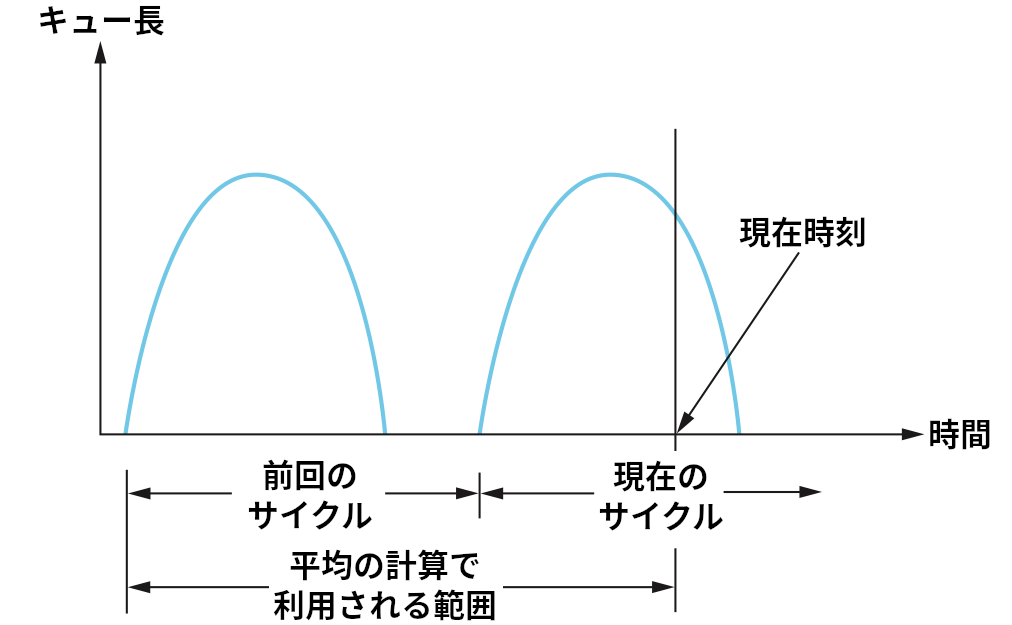
パケットのヘッダーに輻輳を表す 1 ビットのフラグ (輻輳ビット) が追加され、ルーターはパケットが到着したときに平均キュー長が 1 より長い場合に輻輳ビットを設定する。平均キュー長は現在のビジーサイクルと前回のビジー/アイドルサイクルにおける平均として計算される (ビジーとは転送を行っていることを言い、アイドルとはビジーでないことを言う)。図 166 に時刻とキュー長の関係の一例を示す。ルーターは曲線と時刻軸で囲まれる領域の面積を計算し、それを一つ前のビジー/アイドルサイクルの始まりから現在までの経過時間で割ることで平均キュー長を計算する。輻輳ビットの設定で用いられる平均キュー長の閾値 1 は、キューに収まるパケットの増加 (スループットの向上) とアイドル時間の増加 (遅延の悪化) のトレードオフを考慮して決定されている。つまり、キュー長が 1 のときパワー関数が最大になるという仮定が裏にある。
続いてホストに視点を移すと、送信側は道中のルーターによって輻輳ビットが設定されたパケットの個数を記録する。具体的には、送信側は TCP と同様に輻輳ウィンドウを管理し、直近の輻輳ウィンドウ一つ分のパケットの中で ACK の輻輳ビットが設定されたものの割合を計算する。その割合が 50% 以下なら、送信側は輻輳ウィンドウをパケット一つ分だけ大きくする。そうではなく 50% 以上の ACK に輻輳ビットが設定されていたなら、送信側は輻輳ウィンドウを 0.875 倍に縮める。50% という値が選ばれたのは、この値がパワー曲線の頂点に対応することが解析によって示されたためである。また「1 増加、0.875 倍減少」のルールは加算的増加/乗算的減少によってシステムが安定になるために選択された。
ランダム早期検出
ルーターに変更が必要になる輻輳回避の仕組みの二つ目は RED (random early detection, ランダム早期検出) と呼ばれるものであり、Sally Floyd と Van Jacobson によって 1990 年代初頭に考案された。各ルーターが自身のキュー長を監視し、輻輳が起こりそうになったら送信側に輻輳ウィンドウを狭めるよう通知するという点で RED は DECbit と似ている。しかし RED は主に二つの点で DECbit と異なる。
まず、輻輳の通知を明示的に送信側に送信する DECbit と異なり、多くの場合 RED はパケットを意図的に破棄することで暗黙に輻輳を通知する。このとき送信側はタイムアウトまたは重複 ACK によって「通知」を受けることになる。気付いていない読者のために言っておくと、RED はタイムアウト (もしくは重複 ACK のようなパケットロス検出の仕組み) によって輻輳を検出する TCP と共に使われるものとして設計されている。RED (random early detection, ランダム早期検出) の「early (早期)」が示唆するように、ルーターはパケットを破棄する必要のないときに破棄を行うことで送信側に輻輳ウィンドウを狭めるよう通常よりも早期に通知する。言い換えれば、ルーターはバッファの空間が使い果たされる前にパケットをいくつか破棄することで送信側に速度を落とすよう伝え、将来パケットを大量に破棄する事態を回避しようとする。
RED と DECbit の二つ目の違いは RED がパケットの破棄を決定したときに破棄するパケットを選ぶ方法にある。基本的なアイデアを理解するために、単純な FIFO キューを考えよう。キューが完全に満杯になるまで何もせず、満杯になったら到着するパケットを全て破棄する (以前に説明したテールドロップ) ではなく、RED ではキューの長さが特定の破棄レベル (drop level) を超えたときに到着した各パケットを特定の破棄確率 (drop probability) で破棄する。このアイデアを早期ランダムドロップ (early random drop) と呼ぶ。RED のアルゴリズムはキューの長さの監視とパケットの破棄の判断に関する詳細を定義する。
Floyd と Jacobson によって提案されたオリジナルの RED のアルゴリズムをこれから説明する。なお、考案者らおよび他の研究者から提案された改善案も存在することに言及しておく。しかし鍵となるアイデアはここで説明される通りであり、多くの現在の実装はここで説明されるアルゴリズムに近いものを実装している。
まず、RED は平均キュー長を計算する。オリジナルの TCP におけるタイムアウト計算と同様に、RED でも重み付き移動平均が使われる。具体的には、平均キュー長 AvgLen は次のように計算される:
AvgLen = (1 - Weight) x AvgLen + Weight x SampleLen
ここで 0 < Weight < 1 であり、SampleLen は平均キュー長の計算が行われるときのキューの長さを表す。多くのソフトウェア実装では新しいパケットが到着するたびに平均キュー長が計測される。ハードウェア実装では固定されたインターバルごとに計算される場合もある。
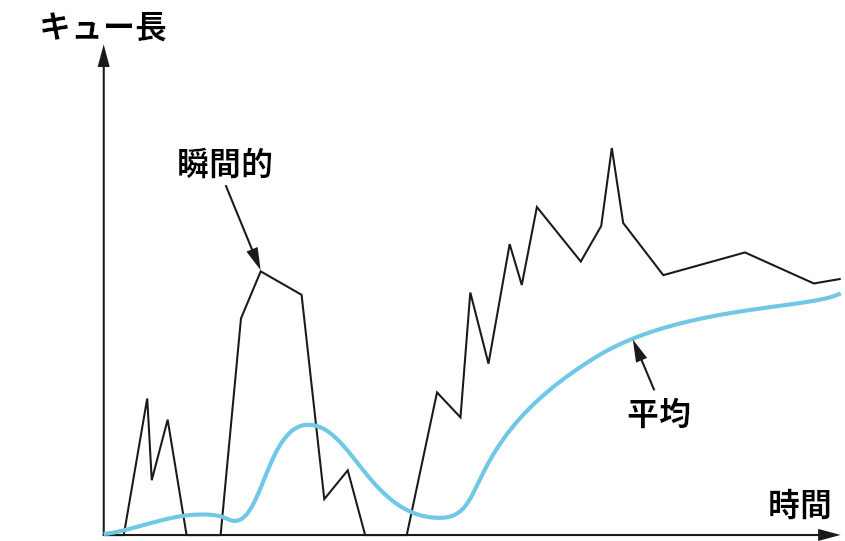
現在のキュー長ではなく平均キュー長を使うのはなぜかと言えば、輻輳の特徴を考慮すると平均キュー長の方が輻輳の状況を正確に捉えられるためである。インターネットのトラフィックにはバースト (パケットが一気に送られること) が多いので、キューが一瞬で満杯になってしばらくすると空になる状況がよく発生する。ある瞬間に多くのパケットがキューにあったとしても、他の多くの時間でキューが空なら、ルーターが輻輳していると判断してホストに減速を求めるべきではない。重み付き移動平均は短い時間におけるキューの長さの変動を排除することで長い時間にわたって解決されない輻輳を検出する。この様子は図 167 の右側に見ることができる。重み付き移動平均をローパスフィルタと考えることもでき、そのとき Weight は時定数となる。正しい時定数の値を選択する問題については後述する。
次に、RED はキュー長に関する二つの閾値 MinThreshold と MaxThreshold を持つ。パケットがルーターに到着すると、RED はこの二つの閾値と現在の AvgLen を比較し、次の処理を行う:
if AvgLen <= MinThreshold
パケットをキューに入れる
if MinThreshold < AvgLen < MaxThreshold
破棄確率 P を計算する
確率 P でパケットを破棄する
if MaxThreshold <= AvgLen
パケットを破棄する
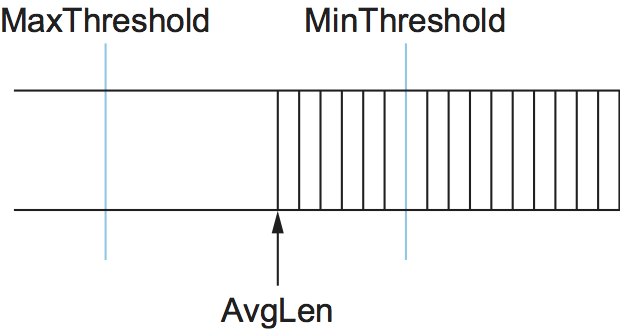
もし平均キュー長が MinThreshold より小さいなら、特別な処理は起こらずにパケットはキューに入れられる。もし平均キュー長が MaxThreshold より大きいなら、パケットは必ず破棄される。もし平均キュー長が二つの閾値の間なら、新しく到着したパケットは特定の確率 P で破棄される。この状況を図 168 に示す。P と AvgLen の大まかな関係を図 169 に示す。破棄確率は AvgLen が二つの閾値の間にあるときゆっくりとしか増加せず、AvgLen が MaxThreshold に達すると 1 まで一気に増加することに注目してほしい。この背後には、AvgLen が MaxThreshold に達したときはパケットをいくつか破棄する控えめなアプローチでは追い付かないので、到着するパケットを全て破棄する大胆な対処が必要になる、という考えがある。なお、ランダムな破棄から決め打ちの破棄までの遷移を (図 168 のように不連続にするのではなく) 連続にした方が適切であると示唆する研究がいくつかある。
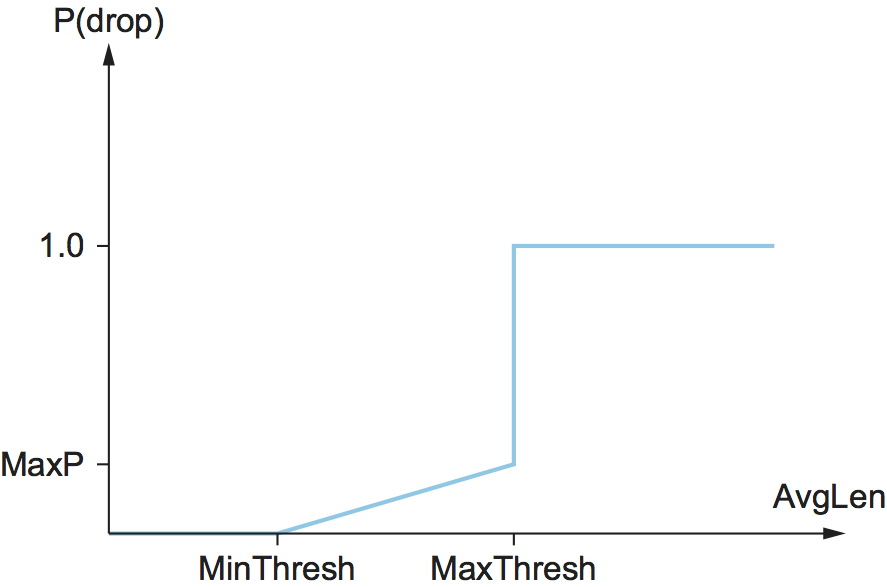
図 169 は破棄確率を AvgLen だけの関数として表しているものの、実際の破棄確率の計算はもう少し込み入っている。実際に使われる P は AvgLen だけではなく最後にパケットが破棄されてからの経過時間を使って次のように計算される:
TempP = MaxP x (AvgLen - MinThreshold) / (MaxThreshold - MinThreshold)
P = TempP/(1 - count x TempP)
ここで count は最後に破棄されたパケットから数えた破棄されていないパケット数を表し、AvgLen は二つの閾値の間にあると仮定されている。この式の TempP は図 169 の y 軸にプロットされた値である。count が大きくなると P は少しずつ大きくなるので、破棄が短い間隔で起こることは稀になる。P の計算に count が使われるようになったのは、count を使わないとパケットの破棄が均等に分散せず固まって発生してしまうことに RED の考案者が気付いたためだった。同じ接続からのパケットはバーストで届くので、固まって発生する破棄は単一の接続から届いたパケットに対するものになる可能性が高い。これは望ましい状況とは言えない: 輻輳ウィンドウを狭めるにはラウンドトリップごとに一つのパケットを破棄すれば十分であり、複数のパケットを破棄すると接続はスロースタートを始めてしまうかもしれない。
例として MaxP = 0.02 の状況を考えよう。最初 count = 0 で、平均キュー長が二つの閾値のちょうど中間だとする。このとき TempP は MaxP の半分 0.01 となる。よって到着するパケット 100 個あたり 99 個はキューに収まる。パケットが破棄されない状況が続くと count が大きくなり、P も少しずつ大きくなる。パケットが一つも破棄されずに 50 個のパケットがキューに収まると、P は二倍の 0.02 となる1。可能性は低いものの、仮に 99 個のパケットが連続で破棄されなかったとすれば、P は 1 となり、次のパケットは必ず破棄されることが保証される。時間に関してほぼ均等なパケットの破棄がこのアルゴリズムによって保証されることが重要な点である。
まとめると、RED は AvgLen が MinThreshold より大きくなったときにパケットのごく一部を破棄することで、TCP 接続の輻輳ウィンドウを狭め、結果としてルーターにパケットが届く速度が落ちることを期待している。全てが上手く行けば、AvgLen が低下して輻輳は回避される。キューの長さは短く保たれ、破棄されるパケットも少数で済むのでスループットも高いままとなる。
なお、RED は時間に関して平均を取ったキュー長を使って処理を行うので、瞬間的なキュー長が AvgLen よりはるかに長くなる可能性はある。キューが満杯になれば、到着したパケットは破棄するしかなくなる。この場合 RED はテールドロップでパケットを破棄する。このテールドロップの振る舞いを可能な限り回避することは RED の目標の一つである。
RED が持つランダム性という性質はそのアルゴリズムに興味深い特徴を与える。RED はパケットをランダムに破棄するので、RED が特定のフローに属するパケットを破棄する確率は、ルーターでそのフローが占める帯域の割合にほぼ比例することになる: 送信するパケットが多いフローは破棄するパケットの候補を多く送っているとも言える。このため、RED には公平なリソース割り当ての一種が (もちろん正確に公平ではないものの) 組み込まれている。ただ、RED は低帯域のフローより広帯域のフローに対して頻繁に罰を与えるので、広帯域のフローでスロースタートが発生する確率が大きくなる。これが起きてしまうと、広帯域のフローには二重の罰が与えられることになる。
教訓
RED が持つ様々なパラメータ ── MaxThreshold, MinThreshold, MaxP, Weight など ── に対してはパワー関数 (スループットを遅延で割った値) を最適化するための解析が大量に行われている。そのパラメータを使ったときのパフォーマンスはシミュレーションでも確認されており、アルゴリズムがパラメータの変化に敏感すぎることはないと示されている。しかし一方で、こういった解析やシミュレーションが特定の特徴を持ったネットワーク負荷を仮定している事実は念頭に置いておく必要がある。RED の真の貢献は、ルーターがより正確にキューの長さを管理する方法を提供したことにある。最適なキュー長の決め方はトラフィック組成 (traffic mix) に依存し、現在でも研究が行われている。その研究ではインターネットで運用された RED から収集された実際の情報が使われる。
二つの閾値 MinThreshold, MaxThreshold の決め方を考えよう。もしトラフィックにバーストが多いなら、MinThreshold を大きくしてリンクの利用率を高く保つべきである。また、二つの閾値の差は RTT における平均キュー長の典型的な増加より大きいことが望ましい。現在のインターネットのトラフィック組成を考慮すると、MaxThreshold を MinThreshold の二倍とするのが適切なことが経験則として知られている。加えて、高負荷の状況で平均キュー長は二つの閾値の間を行ったり来たりすることが予想されるので、MaxThreshold の上にも十分な空間を確保することでインターネットのトラフィックで自然に発生するバーストを吸収できるようにしておく必要がある。そうしなければ、ルーターがテールドロップモードに移行せざるを得なくなる可能性が生じる。
Weight は移動平均を使ったローパスフィルタの時定数だと以前に説明した。この事実は適切な Weight の値を考える上でのヒントを与える。RED は輻輳が起こりそうになるとパケットを破棄することでエンドホストに通知を送ろうとすることを思い出してほしい。ルーターが特定の TCP フローのパケットを破棄し、その直後にそのフローから送られてきた別のパケットをいくつか転送したとしよう。これらの転送されたパケットが受信側に到着すると、受信側は重複 ACK を送信側に送り返す。そして送信側は重複 ACK をいくつか確認すると輻輳ウィンドウを小さくする。このため、ルーターが特定のフローのパケットを破棄した瞬間から実際にそのフローが消費する帯域が減少し始めるまでの時間は少なくともフローのラウンドトリップタイム (RTT) より長くなる。そのため、ルーターが自身を通り抜けるフローの RTT よりずっと小さいタイムスケールで発生する輻輳に対応する意味はおそらくあまりない。以前にも触れた通り、100 ms はインターネットにおける平均的な RTT として悪くない値である。そのため、Weight の値は 100 ms よりずっと小さい期間に起こるキュー長の変化が滑らかになるように選択すべきだと分かる。
「輻輳が近づくと RED は TCP フローに速度を落とすよう伝える通知を送信する」という説明を聞いて、その通知が無視されたらどうするのだろうと疑問に思ったかもしれない。これは無反応フロー問題 (unresponsive flow problem) と呼ばれることがある。無反応フローは公平な量より多くのネットワークリソースを利用し、無反応フローの数が多いと (TCP に輻輳制御が導入されるより前の時代のように) 輻輳崩壊が引き起こされる可能性さえある。次節で解説するテクニックの一部は特定のトラフィックのクラスを他のトラフィックから隔離することで無反応フロー問題を解決する。また、初回のヒントに無反応だったフローのパケットを多く破棄する RED の変種も考えられる。
明示的輻輳通知 (ECN)
RED は最も詳細に研究された AQM の仕組みであるものの、理想的な振る舞いが得られない状況が存在することもあって、広くデプロイされたことはない。しかし、RED は AQM の振る舞いを理解する上での一つの基準となる。RED の研究の成果の一つとして、ルーターがさらに明示的な輻輳シグナルを送信できれば TCP はより優れた輻輳制御を行える可能性を示したことがある。
つまり、RED (あるいは任意の AQM アルゴリズム) がパケットを破棄して送信元の TCP がいずれ (タイムアウトもしくは重複 ACK を通じて) それに気付くのを待つのではなく、パケットに印を付けた上で宛先に向けて通常通り転送すれば効率良く輻輳制御を行えるのではないかというアイデアが生まれた。このアイデアは ECN (Explicit Congestion Notification, 明示的輻輳通知) と呼ばれる IP ヘッダーと TCP ヘッダーに対する変更として実現した。
具体的には、このフィードバックは IP ヘッダーの TOS フィールド内の 2 ビットを ECN ビットとして利用することで実装される。1 ビットは送信側が ECS 可能である (ECS-capable, 輻輳通知に対応できる) ことを示すために使われ、ECT ビット (ECS-Capable Transport, ECS 対応通信ビット) と呼ばれる。もう 1 ビットはエンドツーエンドの経路上のルーターで実行される任意の AQM アルゴリズムが輻輳を検出したときに設定される。このビットは CE ビット (Congestion Encountered bit, 輻輳検出ビット) と呼ばれる。
IP ヘッダーに追加されるこれらの (トランスポート層に依存しない) 2 ビットに加えて、ECN は TCP ヘッダーに対する 2 つの省略可能なフラグビットも定義する。一つ目の ECE ビット (ECN-Echo bit, ECN エコービット) は CE ビットが設定されたパケットを受け取ったことを伝えるために送信側に伝えるために受信側によって利用される。二つ目の CWR ビット (Congestion Window Reduced, 輻輳ウィンドウ縮小ビット) は送信側が輻輳ウィンドウを狭めたことを受信側に伝えるために利用される。
ECN は 8 ビットある TOS フィールドの 2 ビットを解釈する標準的な方法であり、ECN のサポートは強く推奨されているものの、必須ではない。加えて、単一の AQM アルゴリズムが推奨されているわけでもなく、優れた AQM が満たすべき要件のリストが存在するだけに過ぎない。TCP の輻輳制御アルゴリズムと同様に全ての AQM アルゴリズムにはそれぞれ利点と欠点があるため、様々な AQM アルゴリズムが必要になる。一方で、TCP の輻輳制御アルゴリズムと AQM アルゴリズムが協調して動作できるシナリオが一つ存在する: データセンターである。データセンターにおける輻輳制御については本節の最後で議論する。
6.4.2 送信元ベースのアプローチ (Vegas, BBR, DCTCP)
本節でここまでに説明した輻輳回避の仕組みはルーターからの補助を必要とするのに対して、これから説明する戦略は輻輳の兆候を ── パケットロスが起こる前に ── エンドホストから検出する。本項では、輻輳の兆候を異なる情報を用いて検出する三つのアルゴリズムをまず簡単に説明し、それから二つの具体的な仕組みを詳しく見ていく。
こういった仕組みの一般的なアイデアは、ネットワーク内のいずれかのルーターが「キューが長くなってきており、何もしないと輻輳が起こる」と伝えるサインを発していないかどうかを監視するというものである。例えば、送信元は「ネットワーク内のルーターでキューが長くなっているなら、自分が送信したパケットの RTT (ラウンドトリップタイム) が計測可能な形で長くなるはずだ」といった観察を利用する。この観察から次のアルゴリズムが生まれる: RTT の二倍が経過するごとに現在の RTT がこれまでの最大値と最小値の平均より大きくなっていないかどうかを確認し、もし大きくなっていたら輻輳ウィンドウを 0.875 倍に縮小する。
二つ目のアルゴリズムも似た処理を行う。このアルゴリズムでは、現在の輻輳ウィンドウを変更すべきかどうかの判断に RTT と輻輳ウィンドウサイズの両方が利用される。RTT の二倍が経過するごとに、輻輳ウィンドウは次の式の値に応じて変更される:
(CurrentWindow - OldWindow) x (CurrentRTT - OldRTT)
この値が正なら、送信元は輻輳ウィンドウを 0.875 倍に縮小する。この値が負または 0 なら、送信元は輻輳ウィンドウを最大パケットサイズ分だけ大きくする。ウィンドウサイズは調整のたびに変化することに注目してほしい: つまり、ウィンドウサイズは最適な値の周りを振動する。
ネットワークが輻輳に近づくときの RTT の増加は「送信レートを上げてもスループットが上がりにくくなる」と捉えることもできる。三つ目のアルゴリズムはこの考え方を利用する。このアルゴリズムは RTT ごとに輻輳ウィンドウをパケット一つ分拡大し、その上で現在のスループットを輻輳ウィンドウがパケット一つ分だけ小さかったときのスループットと比較する。二つのスループットの差がパケットを一つだけ送ったときのスループット (接続開始時に測定できる) の半分より小さい場合、アルゴリズムは輻輳ウィンドウをパケット一つ分だけ小さくする。スループットはネットワークに存在するパケットのバイト数を RTT で割ることで計算される。
TCP Vegas
これから詳しく説明する仕組みはスループットの変化 (正確には送信レートの変化) に注目する点で三つ目のアルゴリズムに似ている。しかしスループットの計算方法は違っており、スループットの変化ではなく測定されたスループットと期待されるスループットを比較する。この TCP Vegas と呼ばれるアルゴリズムは現在のインターネットでは広くデプロイされていないものの、TCP Vegas が利用する戦略は最近になってデプロイされ始めた他の実装で使われている。
Vegas のアルゴリズムの背後にある考え方は、図 170 に示す標準 TCP のトレースを見ると理解できる。図 170 の上部は接続の輻輳ウィンドウの変化をトレースしたものであり、その解釈は図 162 と同様である。図の中央と下部には新しい情報が示されている: 中央のグラフは送信側における平均送信レート (実測スループット)、下部のグラフはボトルネックのルーターにおける平均キュー長をそれぞれ表す。三つのグラフの時間軸は同一の時刻を表す。 4.5 秒地点から 6.0 秒地点の間 (青い影がかかった部分) に注目すると、輻輳ウィンドウは大きくなっている (上部)。このとき送信レートも向上すると期待されるものの、中央のグラフを見ると送信レートは変化していないのが分かる。これは利用可能な帯域が存在しないためである。このような状況で輻輳ウィンドウを大きくしてもパケットはボトルネックルーターのバッファ空間に積まれるだけ (下部) で、スループットは向上しない。
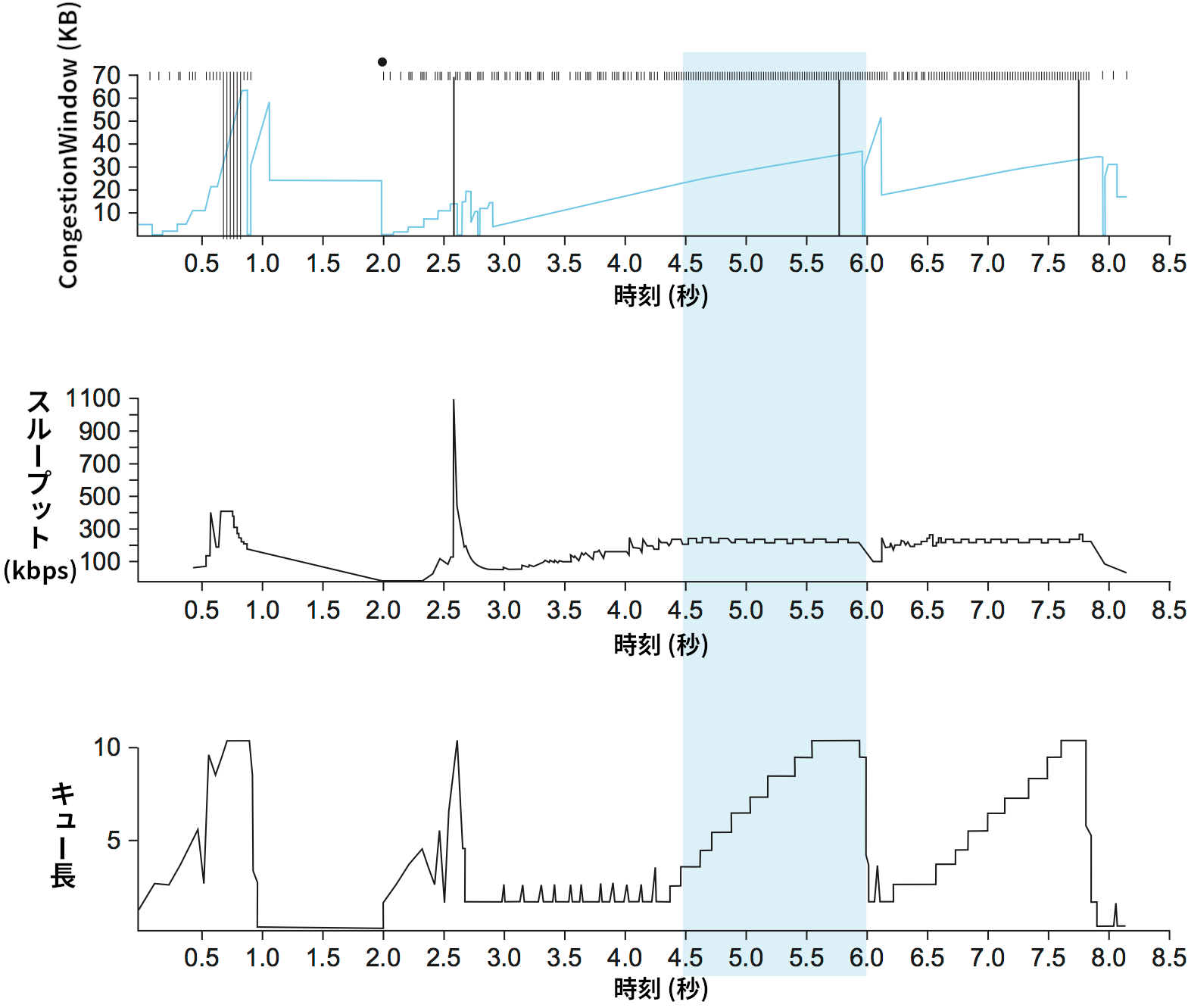
図 170 の現象は氷の上を走る車の比喩を使うと理解しやすいだろう。速度計 (輻輳ウィンドウサイズ) は時速 50 キロで走っていると主張しているものの、窓の外を流れる実際の景色 (測定された送信レート) を見れば時速 10 キロも出ていないことが分かる。何が起きているかと言えば、余分なエネルギーは車のタイヤ (ルーターのバッファ) に吸収されているのである。
TCP Vegas はホストが送信した余分なデータを測定して制御するというアイデアを利用する。「余分なデータ」とは、送信側がネットワークで利用可能な帯域だけのデータを送っていたとしたら送られないはずのデータを言う。図 170 で言えば、青い影がかかった領域で送られているデータが余分なデータである。ネットワークにとって「ちょうどいい」量の余分なデータを送信し続けることが TCP Vegas の目標となる。明らかに、余分なデータを多く送りすぎると遅延が長くなり、最終的には輻輳が起きてしまう。しかしそれより明らかでないこととして、送信する余分なデータが少なすぎても、利用可能なネットワーク帯域の増加に気付くのが遅れてしまう。TCP Vegas が輻輳回避を行う上で利用するのはネットワーク内に存在する余分なデータの推定量であり、純粋に破棄されたパケットの個数だけではない。そのアルゴリズムをこれから詳しく説明する。
第一に、考えているフローの BaseRTT をフローが輻輳していないときのパケットの RTT と定める。実際の実装では、BaseRTT は測定された RTT の最小値に設定される。BaseRTT は接続によって最初に送信されたパケットの RTT となる場合が多い (以降のパケットだとフローが送ったトラフィックによりルーターのキューが空でなくなるため)。このとき、接続がオーバーフローしていないときに期待されるスループット ExpectedRate は次のように計算できる:
ExpectedRate = CongestionWindow / BaseRTT
ここで CongestionWindow は TCP の輻輳ウィンドウサイズを表す。議論を簡単にするため、転送中のデータのバイト数と CongestionWindow が等しいと仮定している。
第二に、TCP Vegas は現在の送信レート ActualRate を計算する。ActualRate の計算は特定のパケットの送信時間を記録し、そのパケットに対する ACK が返ってくるまでの間に送信されたデータ量を経過時間 (サンプルされた RTT) で割ることで行われる。この計算は RTT につき一度行われる。
第三に、TCP Vegas は ActualRate と ExpectedRate を比較して輻輳ウィンドウを適切に調整する。Diff = ExpectedRate - ActualRate とする。このとき定義より Diff は 0 以上である: もし ActualRate > ExpectedRate なら、BaseRTT をサンプルされた最新の RTT ActualRate に更新しなければならない。続いて、二つの閾値 α, β を定義する (α < β)。α はネットワーク内のデータが少なすぎることを検出するのに使われ、β はネットワーク内のデータが多すぎることを検出するのに使われる。もし Diff < α なら TCP Vegas は次の RTT で輻輳ウィンドウを線形に大きくし、Diff > β なら TCP Vegas は次の RTT で輻輳ウィンドウを線形に小さくする。いずれでもなく α < Diff < β なら、TCP Vegas は輻輳ウィンドウをそのままとする。
簡単に説明すれば、実際のスループットが期待されるスループットから離れれば離れるほど、ネットワークには多くの輻輳が存在する。よって送信レートを下げる必要がある。閾値 β による判定がこの処理を行う。逆に実際のスループットが期待されるスループットに非常に近い場合は、利用可能な帯域を効率的に利用できていない危険がある。閾値 α による判定がこの状態を検出する。ネットワーク内に実際の帯域を上回って存在するデータの量を α と β が表す量の間に保つことが全体としての目標となる。
輻輳回避メカニズム TCP Vegas を実行したときのトレースを 図 171 に示す。上にあるのは輻輳ウィンドウサイズのトレースであり、本章で示してきた図と同じだけの情報が示されている。下にあるのは期待されたスループットと実際のスループットのトレースであり、輻輳ウィンドウの値はこの二つの値から設定される。アルゴリズムを最もよく説明するには下のスループットのトレースである。青い線は ExpectedRate のトレース、黒い線は ActualRate のトレースを表す。薄い青の太線は二つの閾値 α と β を表しており、上端が ExpectedRate から α だけ離れた値を、下端が ExpectedRate から β だけ離れた値を表す。TCP Vegas の目標は黒い線で表される ActualRate を薄い青の太線で表される二つの閾値の間の領域に収めることである。もし ActualRate が薄い青の太線より下にあるなら、TCP Vegas はネットワーク内にバッファされるパケットが多すぎると判断して輻輳ウィンドウを狭める。同様に ActualRate が青い太線より上にある (ExpectedRate に近づきすぎている) なら、TCP Vegas はネットワークを効率的に利用できていない可能性を考慮して輻輳ウィンドウを広げる。
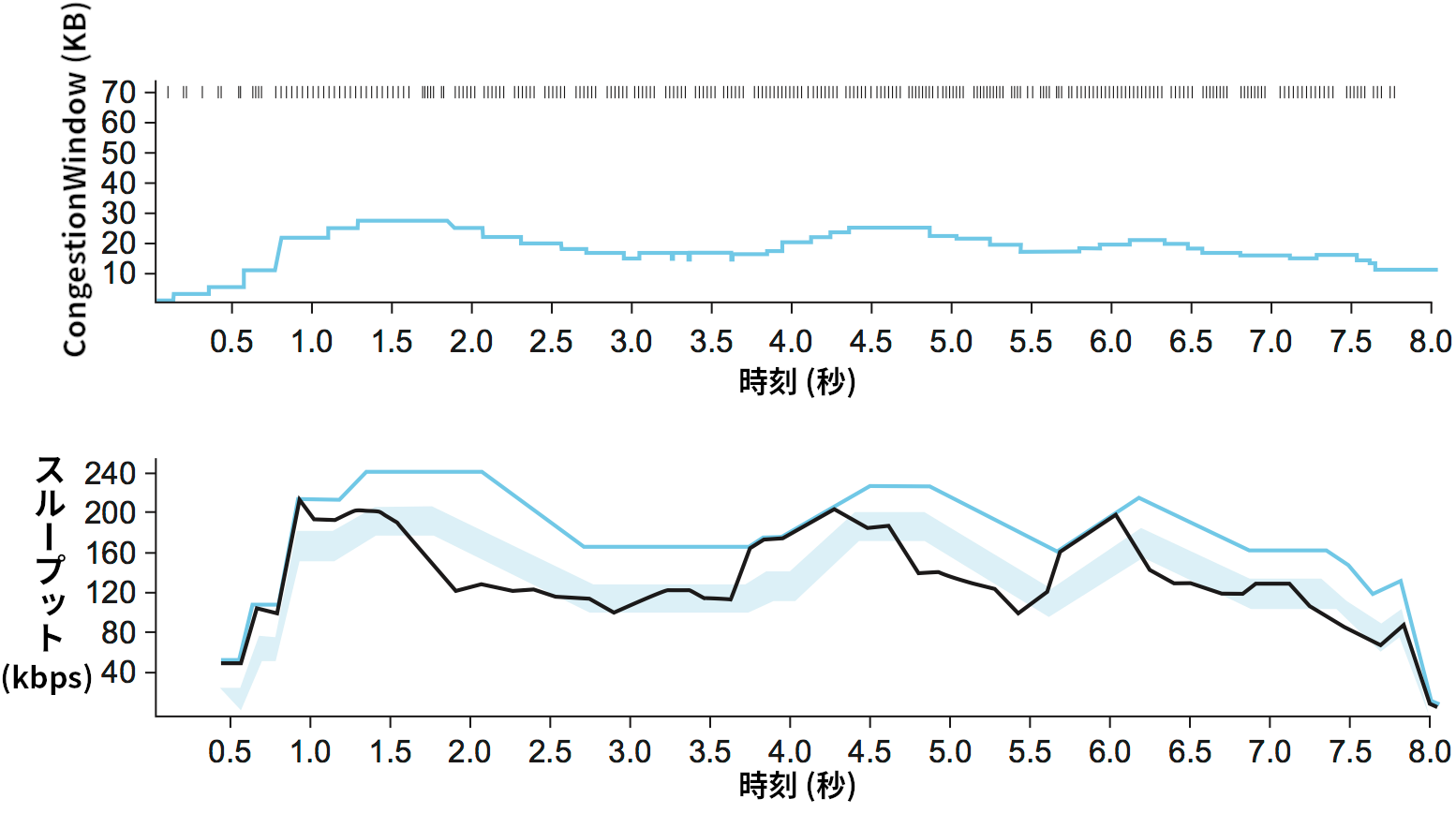
α と β に囲まれる領域 (薄い青の太線)
このアルゴリズムは実際のスループットと期待されるスループットの差を二つの閾値 α, β と比較するので、α, β の単位は bps となる。しかし、この二つの値はネットワーク内に接続が占有すべきバッファの容量だと考えたほうが正確かもしれない。例えば BaseRTT が 100 ms でパケットサイズが 1 KB の接続があり、α は 30 Kbps、β は 60 Kbps だとしよう。このとき α の値は接続がネットワーク内に少なくともパケット 3 つ分のバッファを占有しなければならないと言っているのに等しく、β の値は接続がネットワーク内にパケット 6 つ分以上のバッファを占有してはいけないと言っているのに等しい。実際に TCP Vegas を使うときは、α はパケット 1 つ分のバッファ、β はパケット 3 つ分のバッファに対応する値に設定すると上手く動作する。
最後に、TCP Vegas が輻輳ウィンドウを線形にしか縮小しないことに気が付いたかもしれない。これは安定性の保証に乗算的減少が必要な事実と矛盾するように思える。実は、TCP Vegas はタイムアウトが起こったときには乗算的減少を利用する。ここまでに説明したのは線形の縮小は輻輳ウィンドウを早期に縮小させる処理であり、輻輳が発生してパケットの破棄が起こる前に行われる。
TCP BBR
BBR (Bottleneck Bandwidth and Round-trip propagation time) は新しい TCP 向け輻輳制御アルゴリズムであり、Google の研究者らによって考案された。TCP Vegas と同様に BBR は遅延ベースであり、輻輳とパケットロスを回避するためにネットワーク内のルーターにおけるバッファの増加を検出しようとする。BBR と Vegas はどちらも、何らかの期間における実測値から計算された最小 RTT と最大 RTT を主な制御信号として利用する。
BBR はパケットペーシング、帯域プロービング、RTT プロービングといったパフォーマンス改善のための新しい仕組みを導入する。パケットペーシングは利用可能な帯域の推定値に基づいてパケットの間隔を調整する処理を言う。パケットペーシングによってバーストが減少してキューに格納されるパケットが減り、フィードバック信号が改善される。BBR は定期的にレートを増加させることで利用可能な帯域のプロービング (調査) を行う。また、定期的にレートを減少させることで新しい最小 RTT のプロービングも行う。この RTT プロービングは自己同期的になるように行われる: つまり複数の BBR フローがあるとき、全てのプロービングが可能ならば同時に行われる。こうすることで、輻輳が発生していない経路の実際の RTT により近い値が測定できる。輻輳が発生していない経路の RTT に関する正確な知識の入手という遅延ベースの輻輳制御メカニズムにおける主要な問題の一つがこれで解決される。
BBR に関連する作業は活発に進んでおり、BBR は速いペースで進化している。主な課題の一つが公平性である。例えば、BBR フローと一緒にされた CUBIC フローの帯域が 100 分の 1 に減少することを示した実験や、BBR フロー間でさえ不公平性が発生する可能性があることを示した実験が存在する。高い再送レートを避けることも課題とされており、一部のケースでは 10% ものパケットで再送が起きることが報告されている。
DCTCP
TCP 輻輳制御アルゴリズムの変種が ECN と協調して動作するように設計される状況の例を最後に見て本節を終える。その状況とはデータセンターであり、この輻輳制御アルゴリズムは DCTCP (Data Center TCP) と呼ばれる。データセンターは自己完結的であり、他の TCP フローを公平に扱わない「オーダーメイド」の TCP をデプロイできる点で特殊である。また、データセンターは低コストのホワイトボックススイッチを使って構築され、大陸を横断する長くて太いパイプを気にかける必要がないことから、スイッチに用意されるバッファが最小限であることが多い点でも通常の環境と異なる。
DCTCP のアイデアは難しくない。DCTCP は今にも起こりそうな輻輳を検出するのではなく、どのバイトが輻輳に遭遇するかを推定することで ECN を行う。エンドホストでは、この推定値に基づいて DCTCP が輻輳ウィンドウを調整する。パケットが破棄された場合には標準 TCP のアルゴリズムと同じ処理を行う。このアプローチは高バースト耐性、低レイテンシ、そして高スループットをバッファの短いスイッチで達成するために設計されている。
DCTCP が直面する主要な課題は輻輳に遭遇するバイトの推定である。各スイッチでの処理は単純であり、もしパケットが到着したときにキュー長 (K) が何らかの閾値より高かったら、例えば
K > (RTT × C)/7
が成り立つなら (C はパケット毎秒で表された回線速度)、スイッチは IP ヘッダーの CE ビットを設定する。RED のような複雑な処理は必要にならない。
受信側はフローごとに真偽値変数 SeenCE を管理し、パケットを受け取るごとに次の処理を行う:
-
パケットに CE ビットが設定されていて
SeenCEがFalseなら、SeenCEをTrueにして即時 ACK を送信する。 -
パケットに CE ビットが設定されておらず
SeenCEがTrueなら、SeecCEをFalseにして即時 ACK を送信する。 -
それ以外の場合、CE ビットを無視する。
それほど明らかでないものの、「それ以外の場合」の規則は CE ビットが立っているかどうかに関わらず受信側は一定のパケットごとに遅延 ACK2 を送信することを定めている。これは高パフォーマンスを維持する上で重要なことが判明している。
最後に、送信側は CE フラグが立っている ACK の割合から直近の観測ウィンドウ (RTT の推定値が使われる場合が多い) の間に輻輳を経験したバイトの割合を計算する。DCTCP は輻輳ウィンドウを標準 TCP のアルゴリズムと全く同じように大きくするものの、小さくするときは直近の観測ウィンドウの間に輻輳を経験したバイトの割合に応じて減少幅を調整する。