6.2 キューイング
リソース割り当ての仕組みがどれだけ単純または複雑であろうと、各ルーターでは転送待ちのパケットをバッファするためのキューを管理するキューイング (queuing) と呼ばれる処理が必要になる。キューイングに使われるアルゴリズムは帯域 (どのパケットが転送されるか) とバッファ空間 (どのパケットが破棄されるか) の両方をパケットに割り当てると考えることができる。このアルゴリズムはパケットが転送されるまでの待機時間を決定するので、パケットが経験する遅延に直接影響する。この節では FIFO (first-in, first-out, 先入れ先出し) と FQ (fair queuing, 公平キューイング) というキューイングでよく使われる二つのアルゴリズムを説明する。加えて提案されているそれらの変種もいくつか紹介する。
6.2.1 FIFO
FIFO (first-in, first-out) は FCFS (first-come, first-serve, 先入れ先処理) と呼ばれることもある。そのアイデアは「ルーターに最初に到着したパケットを最初に転送する」という簡単なものである。この処理の様子を図 156 (a) に示す。
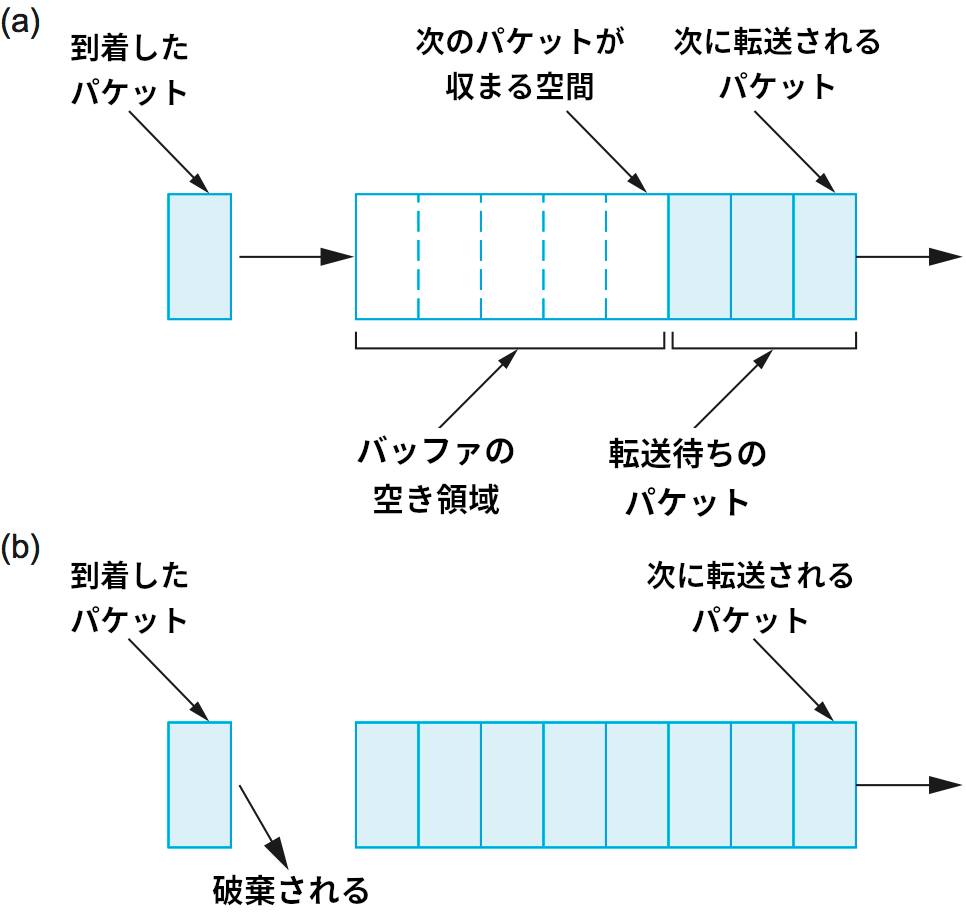
各ルーターのバッファ空間は有限なので、キュー (バッファ空間) が満杯のときに到着したパケットは破棄される。図 156 (b) では、この破棄がパケットの属するフローやパケットの重要性と無関係に行われている。この振る舞いはテールドロップ (tail drop) と呼ばれる。
テールドロップと FIFO は二つの個別のアイデアであることに注意してほしい。FIFO はパケットを転送する順序を管理するのに対して、テールドロップはパケットを破棄する順序を管理する。FIFO とテールドロップはパケットの転送および破棄の順序を決定するポリシーとしてそれぞれ最も簡単なものなので、この二つはセットで ── キューイングの「バニラ」実装として ── 考えられることが多い。しかし紛らわしいことに、この組み合わせを指して「FIFO」という言葉が使われることがしばしばある。正確には「テールドロップの FIFO (FIFO with tail drop)」と呼ぶべきである。以降で議論する異なる破棄ポリシーは「バッファに空きはあるか?」より複雑なアルゴリズムを用いて破棄するパケットを判断し、そういった破棄ポリシーは FIFO と FIFO より複雑な転送ポリシーの両方で利用できる。
キューイングのアルゴリズムとして最も簡単なテールドロップの FIFO は、執筆時点においてインターネットルーターで最もよく使われるアルゴリズムでもある。この単純なアプローチを使うとき、輻輳制御とリソース割り当ての責務は全てネットワークのエッジに押し付けられる: TCP が輻輳の検出と対応の責任を負うことになる。TCP による輻輳制御の仕組みは次節で見る。
FIFO キューイングの簡単な変種として優先度付きキューイング (priotiry queuing) がある。そのアイデアは各パケットに優先度を付けるというものである: 優先度を表す印は例えば IP ヘッダーを通して伝達できる (後述)。ルーターは優先度ごとに一つの FIFO キューを実装し、最も高い優先度を持つ空でないキューからパケットを転送する。優先度が同じパケットは FIFO で管理される。このアイデアはベストエフォート型サービスモデルから小さな一歩を踏み出しているものの、高優先度のパケットが行列の先頭に割り込めるというだけで、特定の優先度クラスに対して何らかの保証を提供するまでには至っていない。
優先度付きキューイングの明らかな問題点として、高優先度のキューがそれより低い優先度のキューを飢餓 (starve) 状態にすることがある。つまり、あるキューより優先度の高いキューにパケットが一つでも存在する限り、そのキューのパケットが転送されることはない。よって優先度キューをまともに実行するには、高優先度のトラフィックがキューに注ぎ込めるパケットの量にハードリミットが必要になる。また、ユーザーにパケットの優先度を勝手に設定させてはいけないこともすぐに分かる。ユーザーがこの処理を全くできないようにするか、ユーザーに対する「プッシュバック (負のモチベーション)」が必要になる。プッシュバックを与える明らかな方法の一つに課金がある ── 高優先度のパケットを送信したら料金が高くなるようにすればいい。ただし、インターネットのような分散された環境でそういった方式を実装するには大きな課題が存在する。
インターネットにおける優先度付きキューイングの用途の一つとして、最も重要なパケットの保護がある ── 典型的には、ネットワークのトポロジーが変化した後にルーティングテーブルを安定化させるために必要なルーティングの更新情報で使われる。そういったパケットは IP ヘッダーの DSCP (Differentiated Services Code Point) フィールド (TOS フィールドを再利用したフィールド) を確認することで検出でき、これらのパケットに対する特別なキューが存在することがしばしばある。実は、これは DiffServ (Differentiated Services) の簡単なケースと言える。
6.2.2 公平キューイング
FIFO を使ったキュー管理の大きな問題点は、異なるトラフィック送信元を区別しないこと、前節で紹介した用語を使えば、異なるフローに属するパケットを区別しないことである。これは二つのレベルで問題となる。まず、輻輳制御がルーターからの助けがほとんどない状態で完全にエッジで実装されたときに、本当に適切な輻輳制御を行えるのかという問題がある。この問題は次節で TCP の輻輳制御を議論するまで差し置いておく。もう一つ、FIFO キューイングでは輻輳制御が完全にエッジで実装され、送信元が輻輳制御の仕組みに忠実に従っているかどうかを監視する手段が提供されないために、正常でない振る舞いをする送信元 (フロー) がネットワーク容量の任意に大きな割合を奪うことが可能になるという問題がある。インターネットをもう一度考えると、アプリケーションが TCP を使わなければ明らかにエンドツーエンドの輻輳制御の仕組みを迂回できる (現在のインターネット電話はこれを行っている) ので、そういったアプリケーションはインターネット中のルーターを自身のパケットで満たすことができ、そのとき他のアプリケーションのパケットは破棄されてしまう。
FQ (fair queuing, 公平キューイング) はこういった問題を解決するために設計された。FQ のアイデアはルーターが現在処理している各フローに対して個別のキューを用意し、それらのキューに対する処理をラウンドロビン方式で行うというものである (図 157)。特定のフローがパケットを速く送りすぎると、そのフローに対応するキューが溜まっていき、満杯になればパケットが破棄される。こうしておけば、特定のフローが他のフローを押しのけてネットワーク容量の任意に大きな割合を奪うことはなくなる。
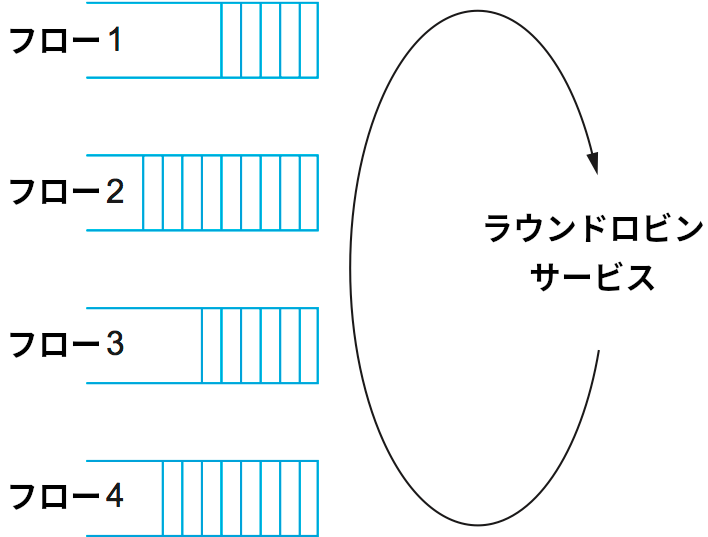
なお、FQ ではルーターがトラフィックの送信元にルーターの状態を伝えたり、パケットの送信速度を何らかの形で制限したりすることはない。言い換えれば、FQ は輻輳制御がエンドツーエンドで行われるものとして設計されており、正しくない振る舞いをするトラフィック送信元がエンドツーエンドの輻輳制御アルゴリズムを正しく実装する他の送信元に干渉できなくするために各トラフィックを分離するだけである。さらに、FQ は正しく振る舞う輻輳制御アルゴリズムによって制御されるフローの間で公平性の保証も行う。
FQ の基本的なアイデアは簡単なものの、正しく FQ を実装する上で注意を必要とする詳細がいくつかある。最も厄介な事実はルーターで処理を受けるパケットの長さが同じではないことで、外向きリンクの帯域を真に公平に割り当てるには、パケットの個数だけではなく長さも考慮しなければならない。例えば、ルーターが 1000 バイトのパケットが流れるフローと 500 バイトのパケットが流れるフロー (上流でフラグメント化が起こっているのかもしれない) を管理しているなら、単純なラウンドロビン方式で各フローのパケットを処理すると帯域の三分の二が一つ目のフローに、三分の一が二つ目のフローに割り当てられることになる。
本当に必要なのはビット単位のラウンドロビンであり、あるフローから 1 ビット転送し、次の瞬間に別のフローから 1 ビットを転送するといった処理が行えれば帯域の利用は公平になる。もちろん異なるパケットに属するビットを混ぜ合わせることはできないので、FQ ではビット単位のラウンドロビン方式で転送を行った場合にそれぞれのパケットの転送がいつ終わるかを最初に計算し、その終了時刻を利用して転送するパケットを選択することで理想的な振る舞いをシミュレートする。
ビット単位のラウンドロビンを近似するこのアルゴリズムを理解するために、まずはルーターが処理するフローが一つだけの状況を考えよう。\(P_{i}\) をそのフローにおけるパケット \(i\) の長さ、\(S_{i}\) をルーターがパケット \(i\) の転送を始める時刻、\(F_{i}\) をルーターがパケット \(i\) の転送を終える時刻とする。ここで全てのアクティブなフローから 1 ビットが転送されるたびに音を立てるクロックを想像してほしい (アクティブなフローとはキューに送信するデータが存在するフローを言う)。パケット \(i\) を転送する間にこのクロックが音を立てる回数を \(P_{i}\) と表すとすれば、アクティブな各フローはクロックが音を立てるたびにデータを 1 ビット転送できることから、\(F_i = S_i + P_i\) が分かる。
フローが一つだけのとき、パケット \(i\) の転送はいつ始まるだろうか? この質問への答えはパケット \(i\) の到着が同じフローからのパケット \(i-1\) の転送完了より早かったかどうかで異なる。もしパケット \(i\) の到着の方が早かったなら、パケット \(i\) の最初のビットはパケット \(i-1\) の直後に転送される。一方で、パケット \(i\) が到着するより早くルーターがパケット \(i-1\) の転送を完了していたなら、このフローに対するキューが空だった瞬間が存在することになり、その間このフローからはパケットを転送できない。\(A_{i}\) をパケット \(i\) がルーターに到着する時刻とすれば、\(S_{i} = \max (F_{i-1},\,A_i)\) が成り立つ。よって次の関係が分かる:
続いて複数のフローが存在する状況を考えよう。このとき \(A_{i}\) の計算で注意が必要になる。\(A_{i}\) をパケットが到着した時刻とすることはできない。上述したように、今考えている「時刻」はビット単位のラウンドロビン方式で全てのフローが 1 ビットの転送を終えてクロックが音を立てたときに進むので、フローが複数あると時間の進みが遅くなる。具体的には、\(n\) 個のアクティブなフローがあるときは \(n\) ビットが転送されるたびに時間が進む。\(A_{i}\) はこのクロックを使って計算しなければならない。
フローが複数ある場合には、それぞれのフローが転送する各パケットに対して \(F_{i}\) を上述の式で計算する。その後 \(F_{i}\) をタイムスタンプとして扱い、このタイムスタンプが最も小さいパケットが次に転送するパケットとする ── 先述した理由により、このパケットは最初に転送を終えるべきパケットである。
この方式では、あるフローから新しく到着したパケットが短い場合、他のフローに対するキューで転送を待っているパケットが存在する場合でも、次に転送されるパケットが新しく届いた短いパケットとなることがあり得る。ただし、これは新しく到着したパケットの転送が現在転送中のパケットに割り込んで開始されることを意味しない。この割り込みが許されていないために、ここまでに説明した FQ の実装は近づけようとしているビット単位のラウンドロビン方式の完全なシミュレートにはならない。
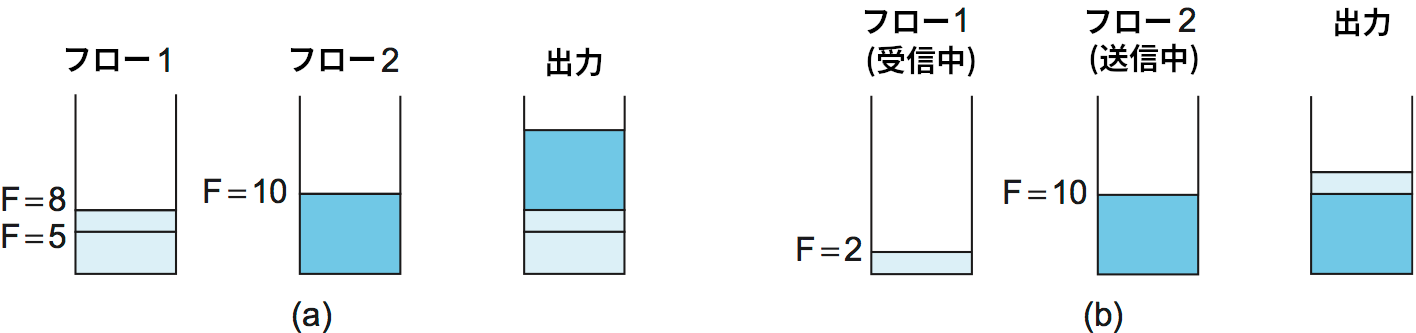
この公平キューイングの実装がどのように動作するかをさらに理解するために、図 158 の例を考えよう。(a) には二つのフローに対するキューが示されている: アルゴリズムは必ず転送完了時刻が早いパケットを選択するので、フロー 1 にある二つの短いパケットが転送されてからフロー 2 の長いパケットが転送される。一方 (b) では、フロー 1 に短いパケットが到着した時点でルーターは既にフロー 2 のパケットを転送しているので、仮にビット単位の公平キューイングを使っていたならフロー 1 のパケットの方が早く終わるにもかかわらず、フロー 2 のパケット転送に対する割り込みは起こらない。
公平キューイングに関して気付くことが二つある。第一に、いずれかのキューに一つでもパケットが存在する間はリンクがアイドルにならない。この特徴を持つキューイング方式は作業節約 (work conserving) と呼ばれる。作業節約のキューイングが使われると、仮に自分が送信するパケットの通過するルーターが大量のフローの通り道だったとしても、どの他のフローもデータを送っていないなら、自分が送るパケットが完全なリンク帯域を利用できる。しかし他のフローが一つでもパケットの送信を始めれば、そのフローに帯域の一部が割り当てられ、自分のフローが使える帯域は減少する。
第二に、リンク帯域が \(n\) 個のフローによって完全に使用されている場合、各フローはリンク帯域の \(1/n\) より多い割合を使うことはできない。いずれかのフローがそれを上回る量のパケットを送ったとしても、それらのパケットには大きなタイムスタンプが割り当てられるので、パケットがキューで転送を待つ時間が長くなるだけで利用できる帯域は増加しない。ルーターが処理できる量より多いパケットを送信し続けると、いずれキューはオーバーフローを起こす ── ただし、破棄されるのが大量のパケットを送信しているフローのパケットなのか、それとも別のフローのパケットなのかは公平キューイングを使っている事実とは関係がない: 破棄するパケットの選択は破棄ポリシーによって行われる。FQ は FIFO と同じくスケジューリングアルゴリズムであり、様々な破棄ポリシーと組み合わせることができる。
FQ は作業節約なので、あるフローが利用していない帯域は自動的に他のフローから利用可能になる。例えば、あるルーターを 4 つのフローが通過していて、その全てのフローがパケットを送信しているとしよう。このとき各フローは帯域の \(1/4\) を受け取る。もしフローの一つが十分長い間アイドルとなり、そのフローに対するキューが空になったなら、利用可能な帯域は残りの 3 つのフローによって共有されるので、各フローは帯域の \(1/3\) を受け取れるようになる。つまり、FQ は各フローに対して必ず提供できる帯域の割合を保証しながらも、帯域を使っていないフローが存在するときは他のフローにその保証よりも多くの帯域の割合を提供する。
FQ の変種に WFQ (weighted fair queuing, 重み付き公平キューイング) と呼ばれるものがある。WFQ では各フロー (キュー) に重みを割り当てることができる。キューに割り当てられた重みはルーターがそのキューを処理するときに送信するビット数を表す。ここまでに説明した単純な FQ は全てのフローに 1 の重みを割り当てる WFQ だと考えることができる: 論理的には各フローは自分のターンが回ってくるたびに 1 ビットの送信を許可される。この設定だと、\(n\) 個のフローが存在するとき各フローは帯域の \(1/n\) を受け取る。しかし WFQ では、一つ目のキューは重み 2 を持ち、二つ目のキューは重み 1 を持ち、三つ目のキューは重み 3 を持つといった設定が可能になる。このとき各キューに転送待ちのパケットが常に存在すると仮定すれば、一つ目のフローは帯域の \(1/3\) を受け取り、二つ目のフローは帯域の \(1/6\) を受け取り、三つ目のフローは帯域の \(1/2\) を受け取る。
ここでは WFQ をフローに対して重みを割り当てるものとして説明したものの、トラフィックのクラスに対して重みを割り当てるものとして実装することもできる。ここで「クラス」とは本章の最初で紹介したフローという単純な分類とは異なるパケットの分類方法を言う。例えば IP ヘッダー内のビットをいくつか利用してクラスを識別し、各クラスに対してキューと重みを割り当てるといった実装が考えられる。これは DiffServ (Differentiated Services) の考え方そのものである。
WFQ を実行するルーターは各キューに割り当てる重みをどこからか学習する必要がある。この学習は手動の設定または送信元からのシグナルを通じて行われる。後者の場合には、システムが予約ベースのモデルに近づくことになる: キューに割り当てられる重みは間接的にフローが受け取る帯域を制御するので、キューに対する重みの割り当ては弱い形の予約とみなせる (リンクが受け取る帯域はリンクを共有するフローの個数にも依存する)。WFQ が予約ベースのリソース割り当ての仕組みにおける一要素として使われることを後で見る。
教訓
最後に、こういったキューの管理に関する議論全体がポリシーとメカニズムの分離という重要なシステムの設計原則の例であることを指摘しておく。メカニズムは様々なサービスを提供するブラックボックスであり、ノブを回すことで制御できる。ポリシーはそのノブをどう設定すべきかを示すものであり、メカニズムというブラックボックスがどのように実装されるかを知らない (気にかけない)。ここまでに考えたケースにおけるメカニズムはキューイングの実装詳細であり、ポリシーは各フローがどれだけのレベルのサービス (優先度あるいは重み) を受け取るかである。WFQ というメカニズムで利用できるポリシーについては以降の節でいくつか説明する。