7.2 マルチメディアデータの圧縮
音声、画像、映像といったマルチメディアデータはインターネットトラフィックの大部分を占める。ネットワークを通じたマルチメディアの大規模な転送を可能にした要因の一つにデータ圧縮技術の進化がある。ほとんどのマルチメディアは人間の感覚器官 ── 視覚器官あるいは聴覚器官 ── によって捉えられ人間の脳によって知覚されるので、その圧縮では特殊な課題が生じる: 人間にとって最も重要な情報を保持しつつ、人間による音声あるいは映像の知覚に影響を及ぼさない情報を全て捨てなければならない。このため、マルチメディアデータの圧縮には計算機科学と人体感覚研究の両方の分野が関係する。本節ではマルチメディアデータの表現と圧縮に関する主な成果を紹介する。
もちろん圧縮はマルチメディア以外のデータに対しても利用される ── 例えば、読者はネットワーク越しにファイルを転送する前に zip あるいは compress を使ってファイルを圧縮したり、ネットワークからダウンロードした圧縮ファイルを解凍したりしたことがあるだろう。こういった通常の (マルチメディアでない) データの圧縮は元のデータを元通りに復元できるので可逆圧縮 (lossless compression) と呼ばれ、マルチメディアデータの圧縮でもツールとして利用される。しかしマルチメディアデータの圧縮では、元のデータが完全には復元できない不可逆圧縮 (lossy compression) が通常用いられる。上述したように人間の感覚器官の感度と脳の知覚には限界があり、マルチメディアを知覚する人間にとってほとんど意味のない情報が元のデータに含まれている場合が多いためである。また、人間は見ている映像や聞いている音声に欠けている部分を補完すること、さらには含まれる誤りを訂正することに非常に長けている。加えて、不可逆圧縮のアルゴリズムを使うと可逆圧縮のアルゴリズムより各段に (一桁以上) 高い圧縮率を達成できる。
ネットワークを通じたマルチメディアの配信に圧縮技術がどれだけ重要かを理解するために、具体的な数字を使った例を考えてみよう。現在たいていのテレビの解像度は 1920×1080 ピクセルであり、各ピクセルは 24 ビットの色情報を持つ。このとき 1 フレームに含まれる情報は次のように計算できる:
よって 1 秒間に 24 フレームを転送するには 1 Gbps 以上の帯域が必要となり、典型的なインターネットユーザーが持つ回線の帯域を超えてしまう。しかし、現代的な圧縮技術を使うと十分高画質な HDTV 信号を 10 Mbps 程度の帯域で配信できる。圧縮前と比べて必要な帯域は二桁小さくなり、多くのブロードバンドユーザーの手に届く帯域となる。同様の圧縮は YouTube の動画をはじめとした低画質映像に対しても適用できる ── どれだけ動画が面白くても、それを現代のネットワークに収めるだけの圧縮技術が存在しなければ、ウェブで動画がこれほど広まることはなかっただろう。
マルチメディアデータに対する圧縮技術の分野では様々な革新が生まれてきた。その筆頭は不可逆圧縮であるものの、可逆圧縮も重要な役割を果たす。実際、多くの不可逆圧縮には可逆圧縮を行うステップが含まれる。そこで、可逆圧縮を概観するところから議論を始める。
7.2.1 可逆圧縮
様々な点で、圧縮はデータの符号化と切っても切れない関係にある。何らかのデータをビットの並びに符号化することを考えるとき、普通はそのビットの並びをなるべく短くしようとする。例えば符号化対象のデータが A から Z までの 26 個のシンボルから構成され、全てのシンボルが同じ回数だけ現れるなら、各シンボルに \(\lceil \log_2 26 \rceil = 5\) ビットを割り当てる以上のことはできない。しかし、もしデータの半分が R なら、R に対応する符号を短くすることでデータ全体の符号を短くできる。一般に、データにおける各シンボルの相対出現確率が分かるなら、シンボルに異なるビットを割り当てることで符号化後のデータを短くできる。これはデータ圧縮分野における初期の重要な成果の一つハフマン符号 (Huffman code) の基本的なアイデアである。
連長符号化
RLE (run length encoding, 連長符号化) は総当たり的な単純さを持った圧縮アルゴリズムである。RLE のアイデアは「同じシンボルの連続する並びをシンボルと長さ ("連長") で置き換える」というものであり、例えば文字列 AAABBCDDDD は 3A2B1C4D と符号化される。
RLE は一部の画像のクラスに対して優れた圧縮アルゴリズムとなる。画像に対して RLE を適用するときは、隣接するピクセルの値を比較して変化を符号化する手法が使われる。広い単色領域を持つ画像に対しては、RLE を使うと非常に優れた圧縮を行える。例えば、スキャンされたテキスト画像に対して RLE を用いると圧縮比率が 8 分の 1 程度になることも珍しくない。こういった画像は大きな空白領域を持つので、RLE が上手く動作する。あの技術を覚えている年配の読者に言っておくと、RLE はファックスを効率良く転送する上で鍵となった技術である。しかし一方で、RLE では孤立した一つのシンボルを表すのに 2 バイトが必要になるので、局所的な値の変化が多い画像を RLE で「圧縮」するとサイズが増加する可能性がある。
差分パルス符号変調 (DPCM)
もう一つの単純な可逆圧縮アルゴリズムとして DPCM (Differential Pulse Code Modulation, 差分パルス符号変調) がある。DPCM のアイデアは「最初に基準となるシンボルを出力し、以降はデータに含まれるシンボルごとに基準のシンボルとの差分を出力する」というものである。例えば基準を A として AAABBCDDDD を DPCM で符号化すると A0001123333 となる。基準が A なので A は 0 となり、A から 1 だけ離れた B は 1 などとなる。なお、この例は DPCM の本当の利点を示せていないことに注意してほしい。DPCM の利点はシンボルをシンボル自身より短いビット列で表せることにある。この例で出力される数値 0 から 3 は 2 ビットで表されるので、完全な文字を表すのに 7 ビットあるいは 8 ビット必要だとすればそれより短くなる。出力する差分が大きくなりすぎた場合、DPCM は新しい基準のシンボルを選択する。
DPCM は多くのデジタル画像で RLE より優れた圧縮効率を達成する。デジタル画像では多くのピクセルの値が隣接ピクセルと大きく変わらない事実を利用できるためである。この相関関係が存在するために、隣接するピクセルの値の範囲は元の画像に含まれるピクセルの値の範囲より格段に小さく、差分は少ないビットで表現できる。著者らが計測したところ、DPCM を用いるとデジタル画像を 3 分の 2 のサイズに圧縮できた。また、隣り合う音声サンプルも似た値を持つ可能性が高いので、DPCM は音声に対しても適用できる。
DPCM と少し異なるアルゴリズムとしてデルタ符号 (delta encoding) がある。デルタ符号は直前のシンボルとの差を符号とする。例えば AAABBCDDDD は A001011000 と符号される。デルタ符号は隣接するピクセルが似ている画像を上手く符号化できる。さらに、デルタ符号化は同じシンボルが続くと 0 を連続して出力するので、デルタ符号化の後に RLE を使うこともできる。
辞書ベースの圧縮アルゴリズム
最後に紹介する不可逆圧縮アルゴリズムは辞書ベースのアプローチを採用する。このようなアルゴリズムの中で最も有名なのは LZ 圧縮 (Lempel-Ziv compression) であり、Unix の compress や gzip は LZ 圧縮の変種を使っている。
辞書ベースの圧縮アルゴリズムのアイデアは「可変長の文字列を要素とする辞書 (テーブル) を作成し、シンボルの並びを辞書へのインデックスの並びに置き換える」というものである。辞書には圧縮対象データに頻繁に表れるシンボルの並びが含まれる。例えば、英語の文章データの圧縮するときは個別の文字ではなく英単語が辞書に加えられる。例えば compression が辞書の 4978 番目だったとすれば、圧縮対象の文章に含まれる全ての compression は 4978 で置き換えられる。英単語の辞書として /usr/share/dict/words を使ったとしよう。著者らの PC ではこのファイルに 25,000 個以上の単語が載っており、そのインデックスは 15 ビットで符号化できる。このとき 7 ビット ASCII で表せば 77 ビットとなる文字列 "compression" は 15 ビットで表現できる。つまり 5 分の 1 のサイズに圧縮が可能になる! もう一つデータを示しておくと、本書で紹介されるとあるプロトコルのソースコードに対して compress コマンドを実行したところ、2 分の 1 のサイズに圧縮できた。
もちろん、辞書はどこから来るのかという問題が残る。一つの選択肢として、静的な辞書を定義する方法が考えられる。この辞書は圧縮されるデータに頻出するシンボルの並びを多く含むことが望ましい。LZ 圧縮によって用いられるさらに一般的な解決法は、圧縮対象のデータの内容に応じて辞書を動的に定義するというものである。しかしこうすると、圧縮処理で構築された辞書を符号化されたデータとは別に受信側に送る必要が生じる。動的に辞書を構築する方法に関しては幅広い研究が行われている。
7.2.2 画像の表現と圧縮 (GIF, JPEG)
デジタル画像の利用が (高速ネットワークではなくグラフィックディスプレイのおかげで) ユビキタスになると、デジタル画像のための標準的なフォーマットと圧縮アルゴリズムが非常に強く求められるようになった。この要望に応える形で、ISO は JPEG と呼ばれるフォーマットを策定した。この名前はフォーマットを設計したチーム Joint Photographic Experts Group の名前から来ている (「Join (共同)」 は JPEG が ISO と ITU-T の共同開発であることを意味する)。現在 JPEG は最も広く用いられる静止画用フォーマットである。JPEG というフォーマットの定義の中心部には以降で説明される圧縮アルゴリズムがある。JPEG で用いられる技法の多くは MPEG でも用いられる。MPEG は Moving Picture Experts Group が策定した映像の圧縮と転送に関する規格の集合である。
JPEG の詳細に立ち入る前に、デジタル画像が圧縮されてから送信され、それを受け取った受信側が解凍して画像として表示するまでにいくつかステップがあることを確認しておく。デジタル画像がピクセル (pixel) と呼ばれる小さな点から構成されることを読者は知っているはずである (スマートフォンに搭載されるカメラの宣伝で「メガピクセル」という言葉を聞いたことがあるだろう)。それぞれのピクセルは画像を表す二次元格子における一点の色を表す。色を表す方法は色空間 (color space) と呼ばれ、様々な選択肢がある。多くの人が慣れ親しんでいる色空間として RGB (red, green, blue) がある。三次元空間の任意の点を表す方法が (例えば直交座標と極座標など) 多く存在するのと同じように、三つの量を使って色を表す方法は RGB の他にも存在する。RGB と異なる最も有名な色空間として YUV がある。ここで Y は 輝度 (luminance) であり、(大まかに言って) ピクセルの全体的な明るさを表す。U と V は色度 (chrominance) すなわち色の情報を表す。紛らわしいことに、YUV 色空間にもいくつか種類がある (後述)。
こういった議論がなぜ重要かといえば、カラーの画像 (あるいは映像) を符号化して転送するには送信側と受信側が色空間に関して合意していなければならないためである。そうでなければ当然、送信側が送った画像と異なる色が受信側で表示されてしまう。よって画像および映像のフォーマットの定義には色空間の定義 (そしておそらくは利用する色空間を伝える手段) が含まれる。
GIF
例として GIF (Graphical Interchange Format) を見てみよう。GIF は RGB 色空間を採用し、各成分を 8 ビットで表す。よって 1 ピクセルは 24 ビットで表される。しかしピクセルごとに 24 ビットをそのまま送ることはせず、GIF は最初に 24 ビットのカラー画像を 8 ビットのカラー画像に変換する。この変換は画像で使われている色を特定し、最もよく使われる 256 色を選択することで行われる (常識的な画像で使われる色の数は 224 よりはるかに小さい)。使われている色の数が 256 色より多い場合は、大きく色が変化するピクセルを可能な限り減らすように 256 色が選択される。
こうして選ばれた 256 色はテーブルに保存され、このテーブルに対する 8 ビットの添え字で画像の各ピクセルの色が表される。以上の変換は画像で使われている色の数が 256 色より多いとき不可逆圧縮になる事実に注目してほしい。こうして変換された画像は最後に LZ 圧縮の一種で (可逆) 圧縮される。
以上のアプローチを用いる GIF は 10 分 1 もの圧縮率を達成できることがある。ただし、そういった優れた圧縮が行えるのは画像で使われている色の数が比較的少ない場合に限られる。例えばグラフィックロゴは GIF が得意とする種類の画像である。これに対して、例えば自然風景の画像は色の連続的な移り変わりを多く持つので、GIF では上手く圧縮できない。そういった画像では、GIF が行う不可逆な色の削減によって生じる不自然な模様を容易に見つけることができる。
JPEG
JPEG を作った団体 (Joint Photographic Experts Group) の名前からも期待できるように、写真画像に対しては GIF よりも JPEG の方が圧倒的に優れる。GIF と異なり、JPEG は色の削減を行わない。JPEG が行う処理は次の通りである。まず、RGB 空間の色 (デジタルカメラで写真を撮ったときに得られることが多い色) は YUV 空間の色に変換される。この変換を行う理由は人間が目を通して画像を知覚する仕組みに関係している。目には明るさを感じる受容体と色を感じる受容体が分かれて存在しており、人間は明るさの変化を非常に細かく知覚できる。よって明るさに関する情報に多くにビットを費やすのが理にかなっている。YUV の Y 成分は (大まかに言って) ピクセルの明るさを表すので、JPEG は Y 成分を圧縮せず、他の二つの (色度) 成分を積極的に圧縮する。
上述したように、YUV と RGB はいわば三次元空間内の点を記述する異なる方式であり、一つの色空間から別の色空間への相互変換は線形方程式で行える。デジタル画像を表すのに広く使われる YUV 空間に RGB 空間の色を移す変換は次の式で行える:
Y = 0.299R + 0.587G + 0.114B
U = (B-Y) x 0.565
V = (R-Y) x 0.713
圧縮を全く行わないなら、定数の正確な値は重要ではない。符号化側と復号側が同じ式を使いさえすれば任意の値を使うことができる (復号側は逆の変換を行って RGB 成分を復元し、画面に表示する)。しかし、ここに示した値は人間の視覚の特徴を元に注意深く選ばれた値である。式を見ると、Y 成分 (輝度) は R, G, B の重み付き和であるのに対して、U 成分と V 成分はそれぞれ異なる成分を使って計算されているのが分かる。U 成分は輝度と B の差を、V 成分は輝度と R の差に定数を乗じた値となっている。また、R, G, B を全て最大値 (各成分が 8 ビットなら 255) に設定すると Y は 255 となり、U と V は 0 になることが分かる。つまり、RGB 空間の点 (255, 255, 255) は YUV 空間の点 (255, 0, 0) に対応する。
画像が YUV 空間に変換されれば、各成分の圧縮を別々に考えられるようになる。U 成分と V 成分に対しては積極的な圧縮を行いたいのだった。この二つの成分を圧縮する方法の一つとして、成分のサブサンプリング (subsampling) がある。サブサンプリングの基本的なアイデアは「隣接するいくつかのピクセルにおける成分の平均値を計算し、その計算結果だけを送信する」というものである。このとき各ピクセルの値は送信されない。
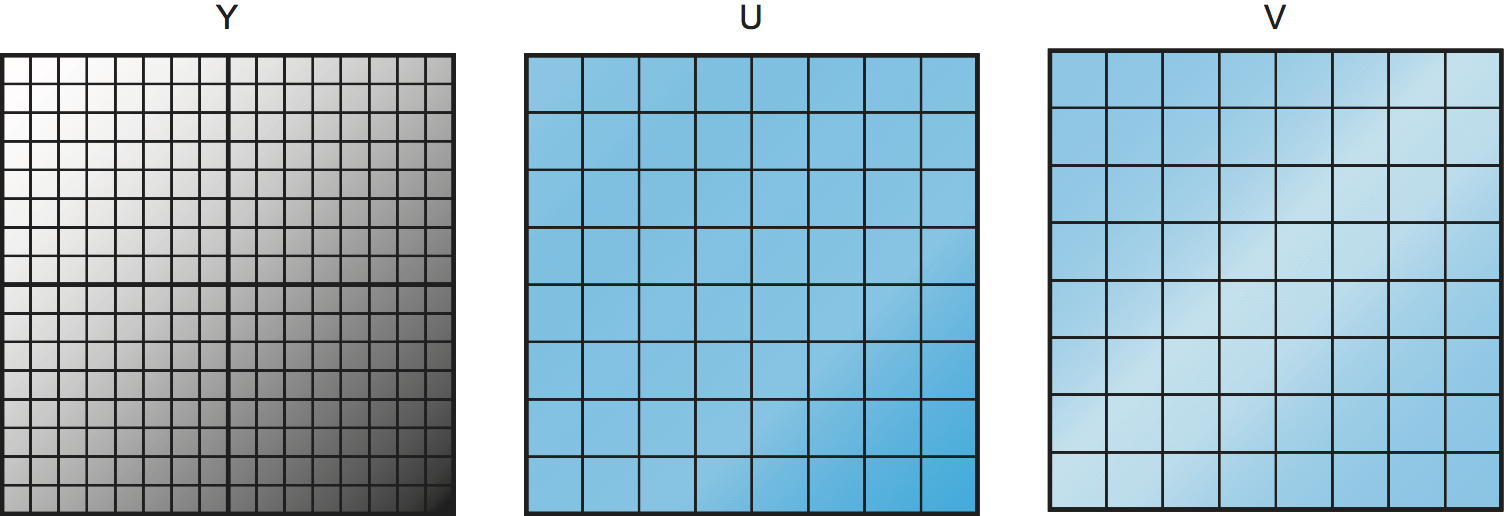
図 189 に U 成分と V 成分に対するサブサンプリングの様子を示す。Y (輝度) 成分はサブサンプリングされておらず、全て (16×16 個) のピクセルが転送される。これに対して U 成分と V 成分ではサブサンプリングによって 4 つのピクセルがまとめられており、計算された 8×8 個の値しか転送されない。つまりこの例では、4 ピクセルごとに 6 個 (Y に 4 個、U, V に 1 個ずつ) の値が転送される。これは無圧縮の場合の 12 個 (各成分に 4 個) と比べて 50% の圧縮となる。
このサブサンプリングの度合いを調整できる事実は強調に値する。これは圧縮の質を調整できることを意味する。ここに示したサブサンプリングは色度成分の縦方向と横方向のピクセル数を両方とも半分にするものであり、JPEG と MPEG の両方で最も一般的なアプローチである。U 成分と V 成分に対してサブサンプリングを施して縦方向と横方向のピクセル数を半分にしたフォーマットを 4:2:0 と呼び、サブサンプリングを行わない各成分が同じだけの解像度を持つフォーマットを 4:4:4 と呼ぶ。

サブサンプリングの後、三つの成分は別々に圧縮される。図 190 に示すように、各成分に対する JPEG 圧縮は 3 つのフェーズからなる。圧縮は 8×8 ピクセルのブロックを一単位としてブロックごとに行われる。最初のフェーズは DCT (discrete cosine transform, 離散コサイン変換) であり、元の画像に含まれる空間領域の信号が空間周波数領域の等価な信号に変換される。二つ目のフェーズでは DCT が出力する信号が量子化 (quantize) され、信号に含まれる最も重要性の低い情報が捨てられる。DCT は可逆であるのに対して、この量子化は不可逆である。三つ目のフェーズでは最終的な結果が符号化される。このフェーズでは、ここまでの不可逆圧縮とは別にさらに可逆圧縮が行われる。圧縮された画像の解凍では同じフェーズが逆順に行われる。
DCT フェーズ
DCT は FFT (Fast Fourier Transform, 高速フーリエ変換) と密接な関係を持つ。JPEG における DCT はピクセルの値からなる 8×8 の行列を入力として受け取り、周波数の係数からなる 8×8 の行列を出力する。入力の行列を空間領域の 64 点で定義された信号と考えれば、DCT はこれらを 64 個の値を空間周波数に分解する。空間周波数を理解するために、画像を \(x\) 方向に横切る様子を想像してほしい。このとき、ピクセルの値を記録していくと何らかの \(x\) の関数が手に入る。この関数がゆっくりとしか変化しないとき (この方向に関する) 空間周波数は低く、逆に急な変化を繰り返すなら空間周波数は高い。つまり低い周波数は画像全体の大まかな特徴に対応し、高い周波数は細かい特徴に対応する。空間周波数空間への変換によって画像に含まれる大まかな特徴と細かい特徴を分けるというのが DCT のアイデアである。大まかな特徴は画像の見た目に重要であるのに対して、細かい特徴はそれほど重要ではなく、場合によっては削除しても見た目はほとんど変わらない。
DCT と逆 DCT (解凍で元のピクセルの値を計算するときに使われる) は次の式で表せる:
ここで \(N = 8\) であり、\(pixel(x,y)\) は圧縮しようとしている 8×8 ブロック内の位置 \((x, y)\) にあるピクセルの値を表す。また \(C(x)\) は次のように定義される:
出力行列の位置 \((0, 0)\) にある最初の周波数係数をDC 係数 (DC coefficient) と呼ぶ。上述の定義からは、DC 係数が入力の 64 ピクセルの平均であることが分かる。出力行列の他の 63 要素は AC 係数 (AC coefficient) と呼ばれる。ピクセルの値は各周波数係数に対応する基底を乗じた値の和として得られる。この計算で周波数係数と基底の積は周波数が高くなればなるほど画像の見た目に重要でない値となっていく。JPEG 圧縮の二つ目のフェーズ (量子化) では、どの係数を捨てるかが判断される。
量子化フェーズ
JPEG 圧縮はこの二つ目のフェーズで不可逆になる。DCT は取り除くべき情報が分かりやすくなるように画像を変形するだけであり、DCT 自体が情報を取り除くわけではない (ただし理論上は可逆であっても、固定小数点算術が原因となって DCT フェーズで精度が落ちる可能性は当然ある)。量子化フェーズで行われる処理は難しくない ── 周波数係数の重要でないビットを消すだけである。
量子化フェーズを理解するために、まず 100 未満の数字の列を圧縮する状況を考えよう。例えば 45, 98, 23, 66, 7 を圧縮したいとする。 圧縮によって数字が 10 の倍数に切り捨てられても問題は起こらないと分かっているなら、整数算術で全ての数字を 10 で割ることで列を 4, 9, 2, 6, 0 に圧縮できる。圧縮前の数字は符号化するのにそれぞれ 7 ビット必要なのに対して、圧縮後の数字はそれぞれ 4 ビットで符号化できる。この例で用いた 10 のような数字を量子化基準 (quantum) と呼ぶ。JPEG 圧縮でも同様の処理が行われる。
| 3 | 5 | 7 | 9 | 11 | 13 | 15 | 17 |
| 5 | 7 | 9 | 11 | 13 | 15 | 17 | 19 |
| 7 | 9 | 11 | 13 | 15 | 17 | 19 | 21 |
| 9 | 11 | 13 | 15 | 17 | 19 | 21 | 23 |
| 11 | 13 | 15 | 17 | 19 | 21 | 23 | 25 |
| 13 | 15 | 17 | 19 | 21 | 23 | 25 | 27 |
| 15 | 17 | 19 | 21 | 23 | 25 | 27 | 29 |
| 17 | 19 | 21 | 23 | 25 | 27 | 29 | 31 |
JPEG では 64 個の周波数係数に対して異なる量子化基準が利用される。これをまとめたのが表 24 に示すような量子化テーブル (quantization table)であり、圧縮によって情報がどれだけ失われるか、そして圧縮の効率はどの程度かを定める。なお、JPEG 規格ではデジタル画像の圧縮に効果的であると示された量子化テーブルがいくつか定義されており、表 24 に示したのはその一つである。いずれの量子化テーブルも低い周波数には 1 に近い量子化基準を割り当て、高い周波数には大きな量子化基準を割り当てる。これは低い周波数の情報はほとんど失われず、高い周波数の情報は大きく失われることを意味する。この量子化によって高周波数の係数の多くが 0 になれば、三つ目のフェーズでその部分を効率良く圧縮できることにも注目してほしい。
基本的な量子化は次の等式で行われる:
ここで \(DCT(i,j)\) はブロックにおけるピクセル \((i,j)\) の周波数係数、\(Quantum(i,j)\) は量子化テーブルの \((i,j)\) エントリーを表す。また IntergerRound は次のように定義される:
解凍は簡単に定義できる:
例えば、あるブロックの DC 係数が 25 (つまり \(DCT(0,0) = 25\)) で、量子化テーブルとして表 24 を使うとすれば、量子化後の値は次のように計算できる:
解凍では、この周波数係数は \(8 \times 3 = 24\) と復元される。量子化によって情報が失われるので、この復元された値は元の値 \(25\) と一致していない。
符号化フェーズ
JPEG 圧縮の最終フェーズでは、量子化された周波数係数がコンパクトな形式に符号化される。この符号化によってさらなる圧縮が行われるものの、この圧縮は可逆である。符号化を行うには、まず二次元の構造を持つ周波数係数を一列に並べなければならない。JPEG 圧縮の符号化フェーズでは、位置 \((0,0)\) の DC 係数から始まり、図 191 に示すようにジグザクに進むことで周波数係数を一列に並べる。こうして一列に並べられた周波数係数には連長符号化 (RLE) の一種が適用される ── RLE は 0 に対してのみ行われる。高い周波数の係数は 0 であることが多いので、この符号化はとても重要となる。それ以外の 0 でない周波数係数はハフマン符号で符号化される。なお、JPEG 規格はこのステップでハフマン符号以外にも算術符号 (arithmetic coding) を使うことを許している。

加えて、圧縮元の 8×8 ブロック画像に関する情報の多くは DC 係数が持つので、そしてブロック単位で見たとき典型的な画像はゆっくりとしか変化しないので、各 DC 係数は一つ前の DC 係数からの差分として符号化される。これは本節の前半で触れたデルタ符号と同じアイデアである。
JPEG には圧縮の効率と圧縮後の画像の画質に関するトレードオフを調節するための変種がいくつか存在する。この調節は例えば異なる量子化テーブルを使うことで行える。こういった変種の存在、および異なる画像が異なる特徴を持つ事実があるために、「JPEG の圧縮率」を一つの数字で正確に表すことはできない。30 分の 1 程度の圧縮率が典型的ではあるものの、さらに優れた圧縮率も不可能ではない。ただし圧縮を強めると、アーティファクト (artifact, 画像の歪み) もそれだけ大きくなる。
7.2.3 映像の圧縮 (MPEG)
続いて MPEG フォーマットを見ていく。MPEG という名前は MPEG を策定した団体 Moving Picture Experts Group の名前から取られた。非常に簡単に考えると、映像とは静止画 (フレームまたはピクチャと呼ばれる) を一定のレートで表示するものと言えるから、フレームを全て JPEG と同じ DCT ベースのテクニックで圧縮することもできる。しかし、この考え方で圧縮を行っても上手く行かない。なぜなら、映像におけるフレーム間の冗長性を取り除けていないからである。例えば、画面の中で動いているものがないとき二つの連続するフレームはほとんど同じ情報を持つので、そのような同じ情報を別々に二度送信する必要はない。たとえ何かが動いている場合でも、その動いている物体自体は変化しておらず、位置だけが変わっているだけなら大きな冗長性がある。MPEG はこういったフレーム間の冗長性を利用して圧縮を行う。MPEG は音声信号を映像と共に符号化する仕組みも定義するものの、ここでは MPEG の映像圧縮に関する話題だけを扱う。
フレームの種類
MPEG は映像フレームの列を入力として受け取り、三つの種類のフレームの列としてそれらを圧縮する。MPEG が利用する三種類のフレームを次に示す:
- I フレーム (intrapicture, イントラピクチャ)
- P フレーム (predicted picture, 予測されたピクチャ)
- B フレーム (bidirectional predicted picture, 双方向から予測されたピクチャ)
入力の各フレームはそれぞれ三つのフレームのいずれかに圧縮される。I フレームは「参照フレーム」と考えることができる: I フレームは自己充足的であり、以前のフレームにも以降のフレームにも依存しない。I フレームは映像のフレームを単に JPEG 圧縮したものだと考えればそれほど間違ってはいない。P フレームと B フレームは自己充足的ではない: これらのフレームには何らかの参照フレームからの差異が記述される。より詳しく言うと、P フレームには最後の I フレームからの差異が記述され、B フレームには最後の I フレームと次の I フレームまたは P フレームを補間する方法が記述される。
図 192 に MPEG による圧縮の様子を示す。7 個のフレームの列が圧縮され、三種類のフレームの列が生成されている。この中で二つの I フレームだけが自立する: 受信側は I フレームを他のフレームとは独立に解凍できる。P フレームは最後の I フレームに依存するので、最後の I フレームが届いた後にしか解凍できない。B フレームは最後の I フレームと次の I フレームまたは P フレームに依存するので、両方のフレームが受信側に届かないと MPEG はオリジナルの映像のフレームを復元できない。
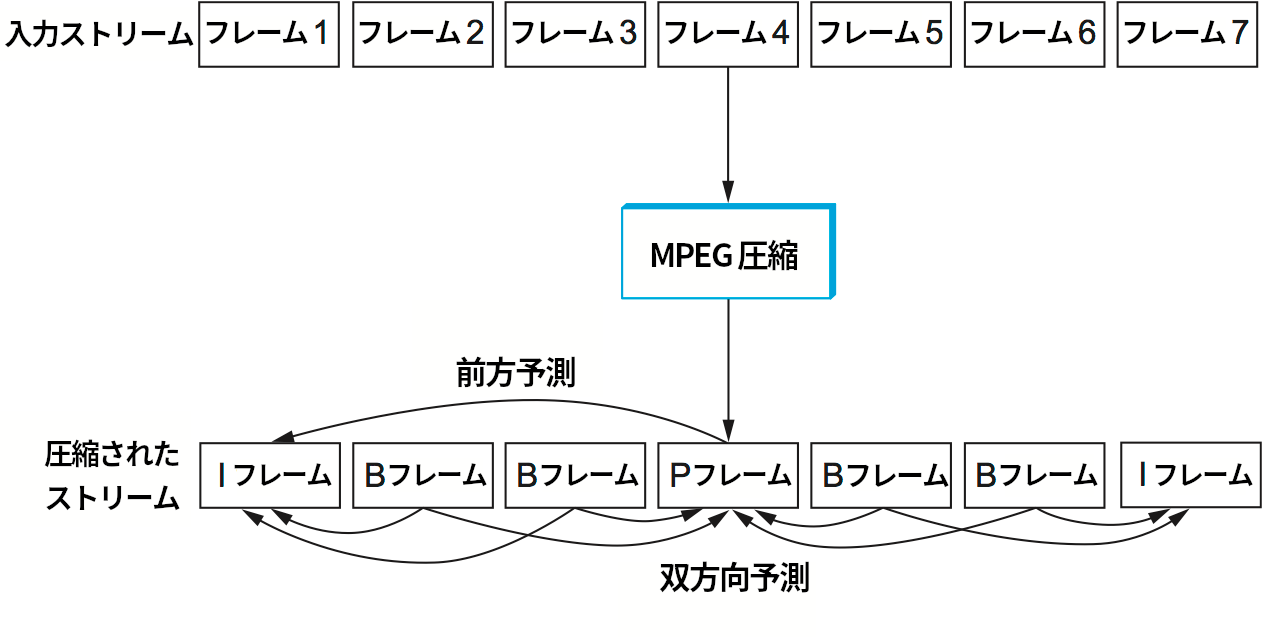
なお、B フレームは時間的に最後のフレームと後のフレームの両方に依存するので、圧縮されたフレームは順番通りに送信されない。例えば図 192 に示した I B B P B B I という圧縮されたフレームの並びは I P B B I B B の順番で送信される。また、MPEG は I フレームと P フレームの比、あるいは I フレームと B フレームの比を定めていない: これらの比は要求される圧縮率や画質によって変化する。例えば I フレームだけを送信することも許される。その場合は映像の各フレームを JPEG で別々に圧縮するのと同じような処理が行われる。
本節で前に議論した JPEG とは対照的に、ここからは MPEG ストリームの復号に焦点を当てる。復号の方が簡単に説明でき、現代のネットワークシステムで実装される可能性も高い: MPEG の符号化には非常に長い時間がかかるので、通常はオフラインで (非リアルタイムで) 行われる。例えばビデオ・オン・デマンドシステムでは、映像は事前に符号化されてディスクに保存される。視聴者が映像をリクエストすると MPEG ストリームが視聴者のマシンに送信され、そのマシンがリアルタイムに復号を行って映像を表示する。
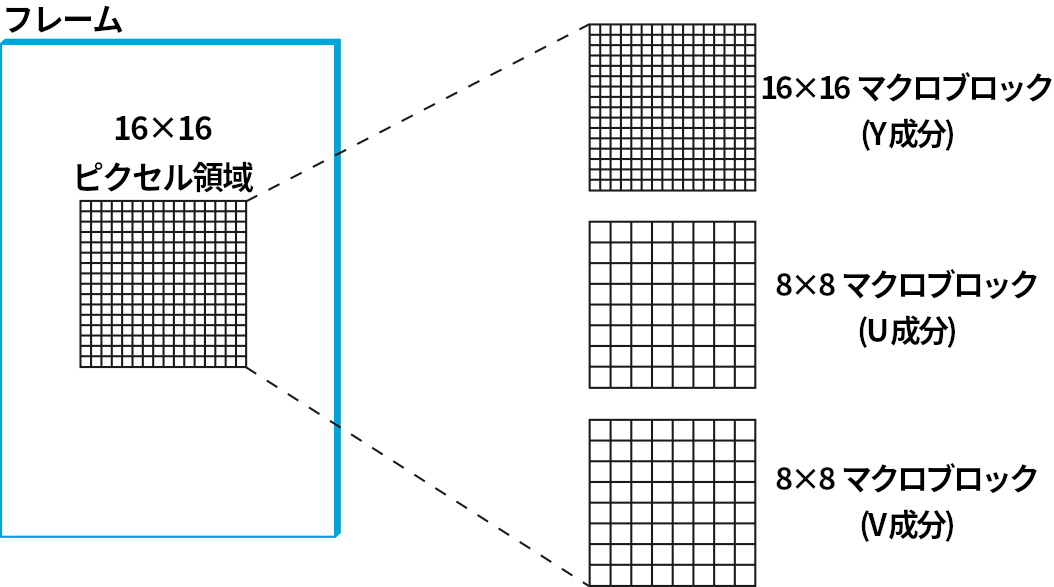
三種類のフレームを詳しく見よう。上述したように、I フレームは圧縮対象のフレームを JPEG 圧縮したものと考えて差し支えない。JPEG 圧縮との主な違いは、マクロブロック (macroblock) と呼ばれる 16×16 の大きなブロックで圧縮が行われる点にある。YUV 空間に変換されたカラー映像に対して、各マクロブロックの U 成分と V 成分に対しては JPEG 圧縮と同様にサブサンプリングが行われる。このサブサンプリングは 2×2 のブロックを 1 単位とみなすことで行われ、U 成分と V 成分のマクロブロックは 8×8 となる。I フレームとマクロブロックの関係を図 193 に示す。
P フレームと B フレームもマクロブロックごとに処理される。ごく簡単に言うと、P フレームと B フレームは各マクロブロックにおける映像の動きに関する情報を伝達する。つまり、そのマクロブロックが参照フレームからどの方向にどれだけ移動したかを伝える。これから MPEG ストリームの解凍で B フレームがどのように復号されるかを説明する。P フレームの復号も参照フレームが一つになるだけで同様に行われる。
B フレームの復号を詳しく説明する前に、B フレームのマクロブロックに含まれる値は最後のフレームと次のフレームを参照する相対的な値でなくても構わないことを指摘しておく。ここまでは必ず両方のフレームを利用するかのように説明してきたものの、片方だけを使うことも、どちらも使わずに I フレームと同様の自己充足的な符号化を使うこともできる。映像が非常に速く変化する場合には最後の (あるいは次の) フレームから予測されるものとして符号化するよりも独立して符号化した方が理にかなっているケースがあるために、この柔軟性は存在している。そのため、B フレームの各マクロブロックの符号には自身に対して使われた符号化を示すフィールドが含まれる。ただしここからの議論では、マクロブロックが双方向予測による符号化を利用する最も一般的なケースを考える。
このケースでは、B フレームのマクロブロックは次の 4 要素で表される:
- フレームにおけるマクロブロックの座標
- 最後の参照フレームを基準としたモーションベクトル
- 次の参照フレームを基準としたモーションベクトル
-
マクロブロック内の各ピクセルに対して、二つの参照フレームからどれだけ変化したかを表すデルタ (差分)
マクロブロック内の各ピクセルに対して、二つの参照フレームにおける対応するピクセルの計算が最初に行われる。これはマクロブロックに関連付いた二つのモーションベクトルを使って行われる。続いて、こうして見つかった二つのピクセルの平均値にピクセルのデルタが加算される。数式を使って説明しよう。最後の参照フレームおよび次の参照フレームで位置 \((x, y)\) にあるピクセルの値をそれぞれ \(F_p (x, y)\), \(F_q (x, y)\) と表し、最後のフレームを基準としたモーションベクトルと次のフレームを基準にしたモーションベクトルをそれぞれ \((x_p, y_p)\), \((x_f, y_f)\) と表す。このとき現在のフレームで位置 \((x, y)\) にあるピクセルの値 \(F_c(x, y)\) は次のように計算される:
ここで \(\delta(x, y)\) はピクセルに対するデルタであり、B フレームに含まれる。このデルタは I フレームのピクセルと同じ形で符号化される: つまり DCT と量子化が行われる。通常デルタの値は小さいので、量子化の後 DCT の周波数係数は大部分が 0 になる。そのためデルタは効率良く圧縮できる。
ここまでの議論から MPEG の符号化方式が大まかに分かってきたかもしれないが、まだ説明が必要な事項が一点ある: 圧縮中に B フレームまたは P フレームを生成するとき、マクロブロックをどこに配置するかを決めなければならない。例えば P フレームでは各マクロブロックは最後の I フレームを基準として定義されるものの、P フレームに対応する I フレームのマクロブロックと P フレームのマクロブロックが同じである必要はないことを思い出してほしい ── 両者の違いはモーションベクトルによって与えられる。モーションベクトルを選ぶときは、P フレームのマクロブロックと対応する I フレームのマクロブロックが可能な限り似るように選ぶ (そうしてデルタを可能な限り小さくする) 必要がある。これは二つのフレーム間で動いた物体を見つけなければならないことを意味する。これは動き推定 (motion estimation) の問題であり、いくつかの解決法 (ヒューリスティック) が知られている。動き推定の問題は難易度が高く、MPEG の符号化に復号より長い時間がかかる一因となっている。MPEG は特定のテクニックを使うよう規定していない: MPEG はモーションベクトルを B フレームと P フレームとして符号化するためのフォーマット、そして解凍時にピクセルを復元するためのアルゴリズムだけを上述のように規定する。
効率とパフォーマンス
MPEG は典型的には 90 分の 1 程度の圧縮率を達成する。圧縮率が 150 分の 1 に達することもある。フレームの種類ごとに見ると、I フレームでは 30 分の 1 程度の圧縮率となる (これは 24 ビット色を 12 ビット色に削減するときの JPEG の圧縮率と同程度である)。P フレームと B フレームの圧縮率は I フレームのさらに 3 分の 1 から 5 分の 1 となる場合が多い。最初に 24 ビット色を 12 ビット色に削減する処理を行わないと、MPEG の圧縮率は 30 分の 1 から 50 分の 1 程度となる。
MPEG の圧縮には多くの計算が絡むので、オフラインで行われる場合が多い。映画やビデオ・オン・デマンドサービスのために映像を準備するときは圧縮がオフラインで行われても問題はない。映像のリアルタイム MPEG 圧縮は現在のハードウェアを用いれば可能であり、ソフトウェア実装もギャップを素早く埋めつつある。解凍の計算では低コストの MPEG ビデオボードが利用できる。解凍で最も時間のかかる処理は幸いにも YUV カラーのルックアップであり、他に複雑な処理はほとんどない。MPEG の復号処理は実際にはソフトウェアで行われる。現在のプロセッサは非常に高速なので、秒間 30 フレームの映像であれば完全にソフトウェアで行ったとしても遅れることなく MPEG ストリームを復号できる ── 最新のプロセッサであれば、HDTV (High Definition Video, 高精細度ビデオ) の MPEG ストリームをリアルタイムに復号することさえできる。
映像の符号化規格
最後に、MPEG は今でも進化が続いている非常に複雑な規格である事実を指摘しておく。この複雑さの一因として、符号化アルゴリズムに可能な限りの自由度を与えるために様々な異なる映像転送レートが規定されたことがある。さらに規格が時間と共に進化した (MPEG-1, MPEG-2, MPEG-4 などが生まれた) こと、そして Moving Picture Experts Group が後方互換性を保持しようとしたことも複雑さに寄与している。本章で説明したのは MPEG フォーマットで用いられる圧縮アルゴリズムの基本的なアイデアだけであり、国際規格で述べられる細かな事項には決して触れていない。
加えて、MPEG 以外にも映像の符号化規格は存在する。例えば、ITU-T はリアルタイムマルチメディアデータの符号化方式として H シリーズ (H series) と呼ばれる一連の規格を策定している。一般的に言うと、H シリーズには映像、音声、制御、そして多重化 (映像、音声、データを一つのビットストリームに流すこと) に関する規格が含まれる。例えば H.261 と H.263 は H シリーズにおける第一世代および第二世代の映像符号化規格である。H.261 と H.263 はどちらも本質的に MPEG によく似ている: どちらも DCT と量子化、そしてフレーム間圧縮を利用する。H.261/H.263 と MPEG の違いは細部にある。
最近になって、ITU-T と Moving Picture Experts Group は共同で H.264 (MPEG-4 AVC) と呼ばれる規格を策定した。これは Blu-ray ディスクや多くの有名なストリーミングサービス (YouTube, Vimeo) で利用されている。
7.2.4 ネットワークを通じた MPEG の転送
上述したように、MPEG と JPEG は単なる圧縮アルゴリズムの規格ではなく、それぞれ映像と画像のフォーマットを定義する。MPEG に関して言うと、まず意識する必要があるのは MPEG 規格が映像のストリームのフォーマットを定義する事実である。このストリームをネットワークパケットに分解する方法は何も規定されない。そのため、MPEG は映像をディスクに保存するときに利用できるのに加えて、ストリーム指向のネットワーク接続 (例えば TCP が提供する接続) を通じて転送される映像に対しても利用できる。
これからメインプロファイル (main profile) と呼ばれる種類の MPEG 映像ストリームをネットワーク越しに転送するときに送られるデータを説明する。MPEG のプロファイルは「バージョン」と同じものと考えて構わない。ただしプロファイルは MPEG ヘッダーで明示的に示されることはなく、受信側がヘッダーフィールドから推測する。
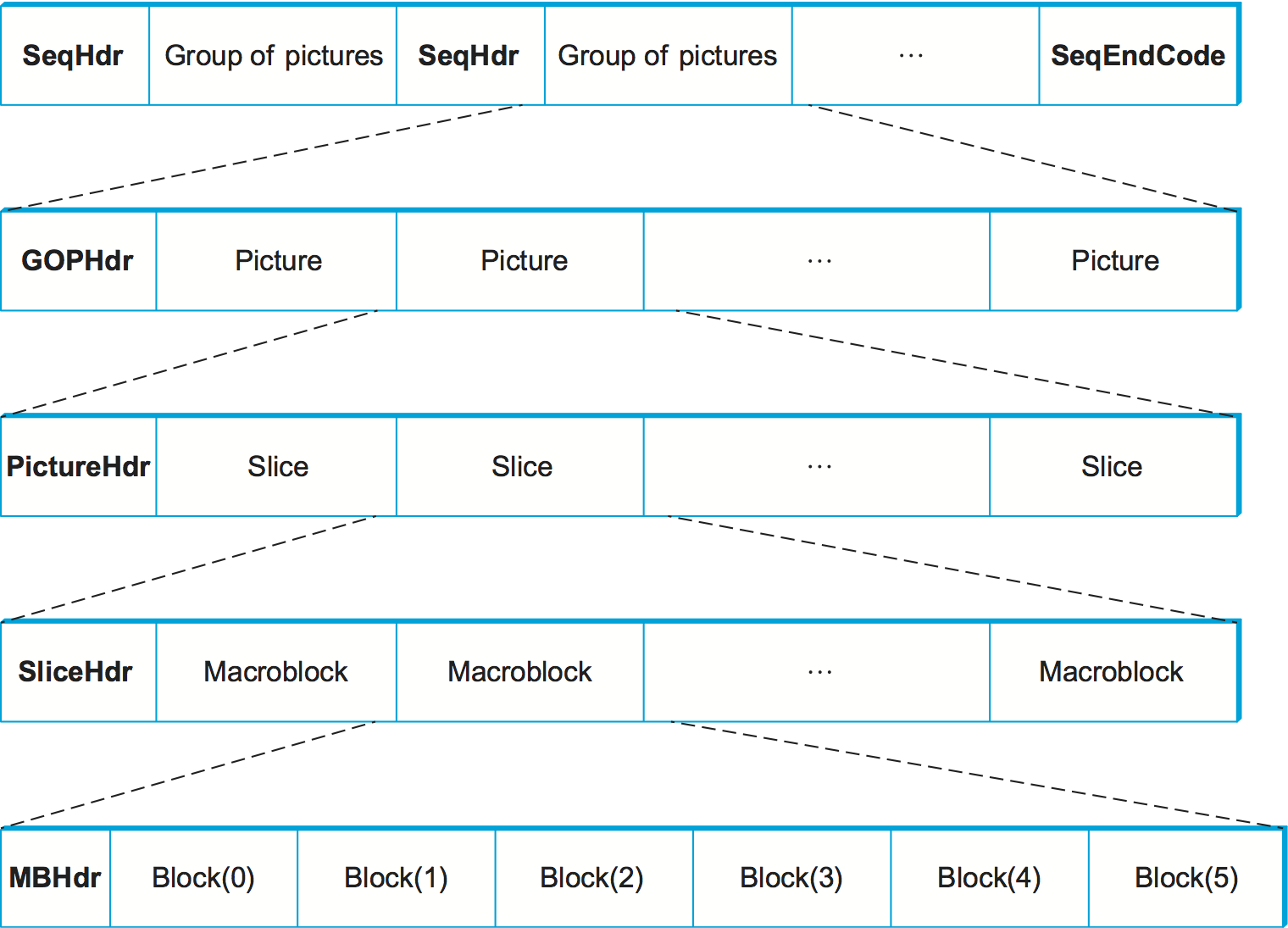
メインプロファイルの MPEG ストリームは図 194 に示すような入れ子構造を持つ (この図で省略されている詳細が大量にある点には注意してほしい)。もっとも外側のレベルでは、映像全体が GOP (group of pictures, ピクチャのグループ) の列として表される。各 GOP の先頭にはヘッダー SeqHdr が付いており、GOP の列の終端は SeqEndCode (0xb7) で表される。SeqHdr は自身の後に続く GOP に含まれるピクチャのサイズ (ピクセル単位およびマクロブロック単位の両方)、イントラピクチャの周期 (単位はマイクロ秒)、この GOP に含まれるマクロブロックに対する二つの量子化行列 ── 片方は自己充足的に符号化されるマクロブロック (I ブロック) に、もう一方は他のマクロブロックを参照するマクロブロック (B ブロックと P ブロック) に使われる ── などの情報が含まれる。こういった情報が GOP ごとに伝達される (ストリームの先頭で一度だけ伝達されるのではない) ために、映像の途中であっても量子化テーブルやフレームレートを GOP 境界で切り替えることができる。この機能は映像ストリームをネットワーク環境の変化に適応させるために利用される (後述)。
各 GOP は先頭のヘッダー GOPHdr とそれに続くピクチャの列から構成される。GOPHdr は GOP に含まれるピクチャの個数、GOP の同期に関する情報 (映像の先頭を基準として、この GOP をいつ再生すべきか) などが含まれる。各ピクチャは先頭のヘッダー PictureHdr とスライス (slice) の列から構成される。各スライスはピクチャの水平な線状領域を表す。PictureHdr はピクチャの種類 (I, B, P) を指定し、ピクチャ固有の量子化テーブルを定義する。SliceHdr にはスライスの垂直位置などが含まれ、ここで量子化テーブルを変更することもできる ── ただしここでは定数のスケーリング係数を指定できるだけで、テーブル全体を与えることはできない。最後に、各マクロブロックにはピクチャ内における位置などが含まれたヘッダー、そして 6 つのブロックを表すデータが含まれる: U 成分は 1 ブロック、V 成分は 1 ブロック、Y 成分は 4 ブロックで表される (Y 成分は 16×16 ピクセル、U 成分と V 成分は 8×8 ピクセルであることを思い出してほしい )。
ここから分かるように、MPEG フォーマットの強みの一つは符号化方式を映像の途中で変更できることである。フレームレート、解像度、GOP に含まれるフレームの種類の割合、量子化テーブル、個別のマクロブロックで使われる符号化方式はどれもストリームの途中で変えられる。この結果として、ピクチャの質を犠牲にしてネットワーク帯域を削減する、ネットワーク環境に適応する映像転送が可能となる。この適応性をネットワークプロトコルから正確にどのように利用するかについては現在も研究が続いている。
ネットワークを通じた MPEG ストリームの転送に関するもう一つの興味深い話題として、ストリームをパケットに分割する方法がある。もし TCP 接続を通して MPEG ストリームを送信するなら、パケット化は問題にならない: 次の IP データグラムを送れるだけのバイトが貯まったかどうかを TCP が判断する。しかし、TCP は遅延に非常に敏感なアプリケーションに適さない特徴 (例えばパケットロス後の大きなレート変化、あるいは破棄されたパケットの再送) を持つので、MPEG ストリームを TCP で送信することは少ない。映像を (例えば) UDP で送信するときは、ストリームをマクロブロックの境界といった意味のある個所で分割するのが理にかなっている。こうしておけば、パケットが破棄されたときに影響を受けるマクロブロックの個数が減少する。これは第 5.4 節で触れたアプリケーションレベルのフレーム化 (application level framing, ALF) の例といえる。
ストリームのパケット化は MPEG 圧縮された映像ストリームのネットワークを通じた転送における最初の問題でしかない。その次にはパケットロスの対処という問題がある。一方では、B フレームが喪失した場合は最後のフレームを続けて表示しておけば映像の質への影響は少なくて済む: 1 秒間に流れる 30 フレームの中で 1 フレームが「止まって」いたとしても、視聴者はほとんど気が付かないだろう。しかし一方で、I フレームが喪失すると大きな問題となる ── 次の I フレームまで B フレームと P フレーム (つまり全てのフレーム) が表示できなくなる。そのため、I フレームの喪失は映像の複数フレームの喪失を意味する。喪失した I フレームを再送することもできるものの、その結果として生じる遅延はリアルタイムなビデオ会議などでは受け入れられないほど大きくなるだろう。この問題への解決法の一つとして、第 6.3 節で説明した Differentiated Services を利用して I フレームを持つパケットに他のパケットより低い破棄確率を示す印を付ける方法がある。
最後に、映像の符号化方式を選択するときの基準は利用可能なネットワーク帯域だけではないことを確認しておく。アプリケーションの遅延制約も符号化方式の選択に影響を及ぼす。繰り返しになるが、ビデオ会議のような対話的アプリケーションは低い遅延を要求する。MPEG ストリームの遅延を決定付ける非常に重要な要因が GOP における I, P, B フレームの割合である。例えば次の GOP を見てほしい:
I B B B B P B B B B I
B フレームは最後の I フレームと次の P フレームまたは I フレームに依存する。そのため、この GOP をビデオ会議アプリケーションで利用すると、送信側は連続する 4 つの B フレームの送信を次の P フレームまたは I フレームが生成されるまで遅らせなければならない。もしビデオ会議の映像が毎秒 15 フレーム (1 フレーム当たり 67 ms) で再生されるなら、依存フレームを待つことで生じる遅延は 250 ms を超える。この遅延はネットワークが持つ伝播遅延とは別に生じるので、全体の遅延は人間が遅延を感じずに会話できる閾値 100 ms を軽々と超えてしまう。このため、ビデオ会議アプリケーションの多くは映像をモーション JPEG (Motion JPEG) と呼ばれる JPEG を使ったフォーマットで符号化する (モーション JPEG では全てのフレームが自己充足的なので、参照フレームの喪失によって複数のフレームが表示できなくなる問題も解決される)。ただ、遅延を抑えることだけを考えるなら前のフレームだけに依存するフレーム間符号化 (P フレーム) を使うようにすれば問題が解決する点には注目してほしい。例えば次に示す GOP を使えば、対話的なビデオ会議アプリケーションでも遅延の問題は起こらない:
I P P P P I P P P P
適応ストリーミング
MPEG などの符号化方式は消費される帯域と画質のトレードオフを調節できるので、映像ストリームを利用可能なネットワーク帯域に適応させることができる。これは現在 Netflix のようなストリーミングサービスが事実上行っている処理である。この処理について詳しく考えよう。
説明を簡単にするため、データの転送で利用されるネットワーク内の経路が持つ空き容量と輻輳の程度を計測する手段があると仮定する (例えばパケットが問題なく宛先に届くレートなどを通して計測する)。コーデックは利用可能な帯域の変動を感知すると、帯域が減少したときは輻輳を抑えるために画質を落とすようにパラメータを調整し、帯域が増加したときは送るデータを増やして画質を上げるようにパラメータが調整する。これは TCP の振る舞いと似ていると言えるものの、決まった量のデータを送るのにかける時間ではなく根本の送るデータ量を変えている点が異なる。リアルタイムアプリケーションで送信時に遅延を生むことは望ましくない。
Netflix のようなビデオ・オン・デマンドサービスの場合は、符号化を「その場」では行わず、事前にいくつかの画質に符号化して別のファイル名で保存しておく方式が取られる。受信側はネットワークの計測結果から転送可能な画質を判断し、それに沿ったファイル名をリクエストする。受信側は再生キューを監視し、キューからフレームが溢れるようなら高い画質に切り替え、キューが空になることが多ければ低い画質に切り替える。
このアプローチでリクエストする画質を変更するとき、受信側は正確にいつ画質を変更するのだろうか? 実は、受信側は動画全体を一つのストリームとしてリクエストすることはなく、短いセグメントごとにリクエストを行う (セグメントは必ず GOP の境界で終わる)。セグメントは典型的には数秒であり、セグメントの終わりが画質を変更する機会となる。言い換えれば、動画は N×M 個のセグメントの集合として保存される。ここで N は受信側が選択できる画質の数を、M は動画のセグメント数を表す。余談: 動画をセグメントで分割しておくと、好きな位置から動画を再生するといったトリックプレイ (trick play) の実装も簡単になる。
最後に、動画のストリーミングに関して細かい点をもう一つ指摘する。受信側は短いセグメントの列をリクエストし、このリクエストは HTTP で発行されることが最も多い。各セグメントが個別の HTTP GET リクエストによって取得され、受信側が次に望むセグメントが URL で指定される。動画のダウンロードを始めるとき、ビデオプレイヤーは動画が持つ N×M 個のセグメントに対する URL だけが記されたマニフェスト (manifest) と呼ばれるファイルを最初にダウンロードする。その後ビデオプレイヤーはマニフェストを使って適切な URL に対してリクエストを発行する。この一般的なアプローチを HTTP 適応ストリーミング (HTTP adaptive streaming) と呼ぶ。ただ、MPEG の DASH (Dynamic Adaptive Streaming over HTTP) や Apple の HLS (HTTP Live Streaming) など、HTTP 適応ストリーミングが標準化されるときは様々な呼称が使われる。
7.2.5 音声の圧縮 (MP3)
MPEG は映像の圧縮に関する規格だけではなく、音声の圧縮に関する規格も策定する。この規格を使えば動画の音声部分を圧縮することも、音声だけを圧縮することもできる (加えて MPEG 規格は圧縮された音声と圧縮された映像を単一の MPEG ストリームに同時に流す方法も定める)。音声圧縮の規格は MPEG が策定したもの以外にも様々な種類が存在するものの、MPEG の MP3 (MPEG Layer III) は最も重要なフォーマットであり、その影響力を考えれば「音声圧縮」は MP3 と同義と言っても過言ではない。
音声圧縮を理解するために、まず音声を表すデータについて考えよう。「高音質」音声の表現としてデファクトスタンダードとなっている CD クオリティの音声は 44.1 KHz のサンプルレートを持つ (つまり、各サンプルは約 23 μs ごとに記録される)。また、CD の各サンプルは 16 ビットの情報を持つ。ここからステレオ (2 チャンネル) の音声ストリームのビットレートを次のように計算できる:
これに対して、伝統的な電話回線の音声は 8 KHz のサンプルレートと 8 ビットのサンプルを利用するので、ビットレートは 64 Kbps となる。
明らかに、限られた帯域しか持たないネットワークを通じて CD クオリティの音声を転送するには何らかの圧縮が必要となる。MP3 を使った音声ストリーミングが誕生したころ、1.5 Mbps のインターネット接続が最先端だった。さらに悪いことに、同期や誤り訂正に関するオーバーヘッドで CD に記録されるビット数は 3 倍程度になるので、仮に CD から読み込んだデータをそのままネットワークに送信するとなれば 4.32 Mbps 程度の回線が必要となる。
音声には映像と同様に多くの冗長性があり、音声の圧縮でも冗長性が利用される。MPEG 規格は三つの圧縮レベルを定めている (表 25)。この中で長年にわたって最も広く使われてきたのが Layer III であり、この圧縮方式が MP3 として知られている。近年では、人々が音楽を聴く手段としてストリーミングが支配的になるにつれ、高帯域のコーデックも急増している。
| 符号化方式 | ビットレート | 圧縮係数 |
|---|---|---|
| Layer I | 384 Kbps | 14 |
| Layer II | 192 Kbps | 18 |
| Layer III | 128 Kbps | 12 |
こういった圧縮レートを達成するために、MPEG が映像の圧縮で利用するのに似たテクニックを MP3 は採用する。まず、音声ストリームをいくつかの周波数サブバンドに分解する。これは MPEG における Y, U, V 成分への変換に対応する。次に、各サブバンドはブロックの列に分解される。これは MPEG におけるマクロブロックに対応するが、MP3 ではブロックの大きさが可変であり、64 サンプルから 1024 サンプルとなる (符号化アルゴリズムは音声に対する影響を考慮してブロックの大きさを変更するが、この処理の詳細は本書の範囲を超える)。最後に、各ブロックは DCT アルゴリズムの一種を使って変換され、その結果が量子化され、最終的にハフマン符号で符号化される。この部分は MPEG とほぼ同一である。
MP3 の賢いトリックはサブバンドの個数と各サブバンドに割り当てるビット数の選択にある。ここでは固定されたビットレートで可能な限り音質を高くすることが目標となる。この選択の正確な方法は心理音響学的モデルが関係するので本書の範囲を超えてしまうものの、例えば「男性の声を圧縮するときは低い周波数のサブバンドに多くのビットを割り当て、女性の声を圧縮するときは高い周波数のサブバンドに多くのビットを割り当てる」といった考え方は納得できるだろう。また、MP3 は各サブバンドに対する量子化テーブルを動的に変更する機能も持つ。
圧縮が終わったサブバンドは固定サイズのフレームに分割され、各フレームにヘッダーが付けられて MP3 ファイルが完成する。このヘッダーには同期に関する情報や、どのサブバンドがどれだけのビットを使っているかをデコーダーに伝えるためのビット割り当てに関する情報が含まれる。上述したように、音声フレームと映像フレームを混ぜて単一の MPEG ストリームとして転送することもできる。一つ興味深いことを記しておくと、ユーザーは画面の乱れより音声の乱れに敏感なので、輻輳が起こって特定のフレームが届かなかった場合に映像を 1 フレーム飛ばしても視聴体験はそれほど影響を受けないのに対して、音声のフレームを 1 フレームでも飛ばすと視聴体験が大きく低下することが知られている。