7.1 マーシャリング
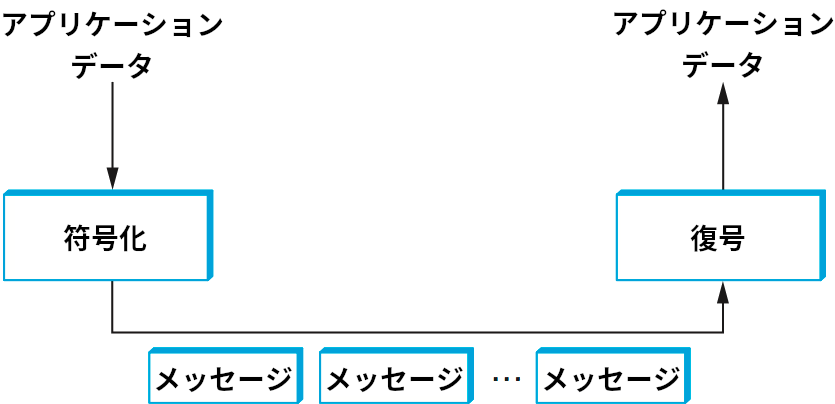
ネットワークデータに対して最も頻繁に施される変形の一つは、アプリケーションが使う表現からネットワークを通じた転送に適した表現への変形である。この変形はよくプレゼンテーションフォーマット化 (presentation formatting) と呼ばれる。図 179 に示すように、送信側のアプリケーションは転送したいデータを自身が内部で使う表現からネットワークを通じて送信できる表現に変換する。つまり、送信側でデータはメッセージに符号化 (encode) される。受信側では、アプリケーションが受け取ったメッセージを自身が処理できる表現に変換する。つまり、受信側でメッセージはデータに復号 (decode) される。この一連の処理をマーシャリング (marshalling) またはシリアライゼーション (serialization)と呼ぶことがある。これらは遠隔手続き呼び出し (RPC) の用語である。RPC でクライアントは引数を付けて手続きを起動するので、そのときネットワークメッセージを作るために引数を「適切な形に素早くまとめる」必要がある。
こういった処理の何が難しいのかと疑問に思うかもしれない。マーシャリングを難しくする要因の一つとして、コンピューターがデータを表す表現が決まっていない事実がある。例えば、IEEE 754 規格のフォーマットで浮動小数点数を表すコンピューターもあれば、非標準のフォーマットを使うコンピューターもある。整数という非常に単純なデータでさえ、アーキテクチャによってサイズ (16 ビット、32 ビット、64 ビット) が異なる。さらに、整数の表現には上位バイトを上位アドレスから順に配置するビッグエンディアン (big endian) と、上位バイトを下位アドレスから順に配置するリトルエンディアン (little endian) の二つがある。例えば PowerPC はビッグエンディアンのプロセッサであり、Intel x86 ファミリーはリトルエンディアンのアーキテクチャである。現代のアーキテクチャには両方のエンディアンをサポートするバイエンディアン (biendian) であるものも多いが、今の議論で重要なのは通信相手のホストが整数を格納するときに使う表現を確信できない事実である。ビッグエンディアンとリトルエンディアンで表した整数 34,677,374 を図 180 に示す。

マーシャリングが難しい別の理由として、アプリケーションが異なる言語で書かれる可能性があること、そして単一の言語で書かれたとしてもコンパイラが異なる可能性があることがある。例えば、構造体 (レコード) をメモリに並べるときコンパイラにはそれなりの自由があり、例えばフィールド間のパディングなどを自由に決められる。そのため、同じ言語で書かれたプログラムを実行する同じアーキテクチャのマシンであっても構造体のフィールドのアライメントが異なる可能性があり、構造体をそのまま転送することはできない。
7.1.1 分類
マーシャリングはそれほど難しい問題ではない ── 突き詰めればビットを組み替えているだけである ── ものの、下さなければならない設計判断は驚くほど多く存在する。最初にマーシャリングシステムの分類を示す。以下に示す分類だけが正しいというわけではないが、興味深い選択肢の多くをカバーするには十分である。
データ型
最初に、マーシャリングシステムはサポートするデータ型の種類で分類できる。一般に、マーシャリングシステムがサポートするデータ型には三つのレベルが存在する。それぞれのレベルは異なる形でマーシャリングシステムを複雑にする。
最も下のレベルには、マーシャリングシステムの基礎となるデータ型が存在する。典型的には整数、浮動小数点数、文字列がこの基礎的なデータ型に含まれる。これ以外にも真偽値型などがサポートされる場合もある。上述したように、これらのデータ型の値を異なる表現間で変換する符号化処理をシステムは行える必要がある。例えば整数をビッグエンディアンからリトルエンディアンに変換できなければならない。
次のレベルには「平坦な」データ型 ── 構造体 (レコード) と配列がある。一見すると平坦なデータ型のマーシャリングは簡単に思えるかもしれないが、実際はそれほど単純ではない。アプリケーションをコンパイルするのに使われるコンパイラが構造体のフィールドの位置をワード境界に揃えるためにフィールドの間にパディングを挿入できることが問題になる。通常マーシャリングシステムはパディングを作らずに詰めた (packed) 状態で構造体を扱う。
最も高いレベルには「複雑な」データ型 ── 他の値へのポインタを含む型 ── が存在する。この種のデータ型の典型的な例として木がある。明らかに、データの符号化処理はメモリアドレスを使って実装されるポインタを転送しても意味の変わらない表現に変換しなければならない。言い換えれば、マーシャリングシステムは複雑なデータ型を直列化する必要がある。
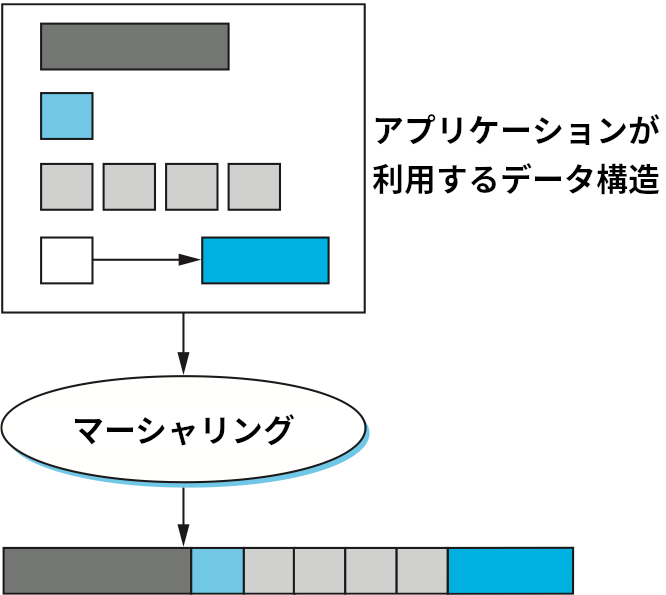
まとめると、サポートされる型の複雑さに応じて、マーシャリングは基礎となる型の変換、構造体からのパディングの削除 (パッキング)、そして複雑なデータ型の線形化を行ってネットワークを通じて転送できる連続なメッセージを作成する。この処理を図 181 に示す。
データの変換
データ型が定まると、続いて変換をどのように行うかという問題がある。ここでは主に二つの解決策がある: 「正準 (canonical) な中間表現を用意する」と「受信者が帳尻を合わせる」である。順に説明しよう。
「正準な中間表現を用意する」とは、あらかじめデータ型のそれぞれに対してマーシャリングで利用する表現を決めておくことを意味する。その上で送信側のホストは送信するデータを自身が利用する内部表現から中間表現に変換してから送信し、受信側は受け取ったデータを中間表現から自身が利用する内部表現に変換する。例として整数を考えよう (他のデータ型でも同様となる)。あるマーシャリングシステムが整数の中間表現として (例えば) ビッグエンディアンを使うと決めたとする。このとき送信側のホストは整数を必ずビッグエンディアンに変換してから送信し、受信側は受け取ったビッグエンディアンの整数を自身が内部で利用する表現に変換する (この方式はインターネットのプロトコルヘッダーで使われている)。もちろん、ホストが元々ビッグエンディアンを使っている場合もある。そのときは表現の変換が必要にならない。
もう一つの選択肢「受信者が帳尻を合わせる」では、送信側は自身の内部表現のままデータを送信する。ただし構造体のパッキングと複雑なデータ型の線形化は送信側で行うことが多い。そのデータを受け取った受信側は送信側の内部表現を自身が利用する表現に変換する責務を負う。この方式では、全てのホストが他の全てのマシンのアーキテクチャによって利用される表現からの変換を行える必要があることが問題となる。ネットワークの分野では、こういった問題を抱えた解決法を N×N 解決法 (N-by-N solution) と呼ぶ: N 台のマシン全てが N 個のアーキテクチャ全てを処理できなければならない。これに対して、正準な中間表現を利用するシステムでは各ホストが自身の利用する表現と中間表現を相互に変換する方法だけを知っていれば十分となる。
この議論からは、正準な中間表現を利用する方法が明らかに優れているように思える。これは間違いなく三十年以上に渡ってネットワーク分野で一般的な考え方だった。しかし、絶対にそうだと断言できるわけではない。というのも、基礎的なデータ型の表現はそれほど多くない、つまり N はそれほど大きくない。加えて、最もよくあるシナリオは同じタイプのマシンがお互いに通信するというものであり、このシナリオでは直接送信すれば済むデータをわざわざ中間表現に変換する意味はない。
三つ目の選択肢として「受信側が送信側と同じアーキテクチャならそのまま転送し、そうでないなら中間表現に変換してから転送する」という方式がある (ただ、この方式を採用するシステムを著者らは見たことがない)。送信側は受信側のアーキテクチャをどのように学習するのだろうか? ネームサーバーを用意する、あるいは簡単なテストケースを送信して期待通りの結果が得られるかどうかを確認する方法が考えられる。
タグ
マーシャリングにおける三つ目の問題として「メッセージに含まれるデータの種類をどうやって受信側に伝えるのか?」という問題がある。この問題に対しては「タグ付きデータ (tagged data)」を使う方法と「タグ無しデータ (untagged data)」を使う方法がよく使われる。タグ付きデータの方が分かりやすいので、そちらを先に説明しよう。
マーシャリングの文脈でタグ (tag) とは、受信側がメッセージを復号できるようにメッセージに追加される情報を言う。タグにはいくつか種類がある。例えば、それぞれのデータアイテムに「型」タグを付けることができる。この型タグは自身の後ろに続くデータの種類 (整数、浮動小数点数など) を表す。これとは異なるタグとして「長さ」タグがある。このタグは配列の長さや整数の長さを指定するために用いられる。三つ目の例として「アーキテクチャ」タグがある。これは「受信側が帳尻を合わせる」方式と一緒に用いられ、メッセージに含まれるデータを生成したマシンのアーキテクチャを伝えるのに使われる。タグ付きメッセージで符号化した 32 ビット整数の例を図 182 に示す。

もう一つの選択肢として、当然、タグを用いない方式がある。このとき受信者はデータの復号方法をどのように知るのだろうか? 受信者はプログラムから知る。例えば、ある遠隔手続きが二つの整数と一つの浮動小数点数を受け取ると決まっているなら、その遠隔手続きが受け取ったデータのタグを調べる理由はない: メッセージには二つの整数と一つの浮動小数点数が含まれていると決め込んでそのように復号するだけである。この方式は多くのケースで上手く行くものの、可変長配列を送信するときには上手く行かないことに注意してほしい。そういった場合には長さタグを使って配列の長さを伝える方法が一般に利用される。
また、タグを使わないアプローチではマーシャリングが完全にエンドツーエンドで行われる事実も強調に値する。つまり、タグが無いとき第三者はメッセージを解読できなくなる。第三者がメッセージを解読することなどあり得るのだろうか? 実は、システムが通常の処理では解決できない予想外の問題に対するアドホックな解決策として、メッセージの内容を無理やり解読して行う奇妙な処理が用いられることがある。そういった雑なネットワークの設計は本書の範囲を超える。
スタブ
スタブ (stub) とはマーシャリングを実装するコードを言う。スタブという言葉は RPC の文脈で用いられることが多い。クライアントサイドではスタブが遠隔手続きの引数をマーシャリングし、RPC プロトコルで転送できるメッセージに変換する。サーバーサイドではスタブがメッセージを遠隔手続きの引数として使える形に変換する。スタブはインタープリタで実行されることもあればコンパイルされて実行されることもある。
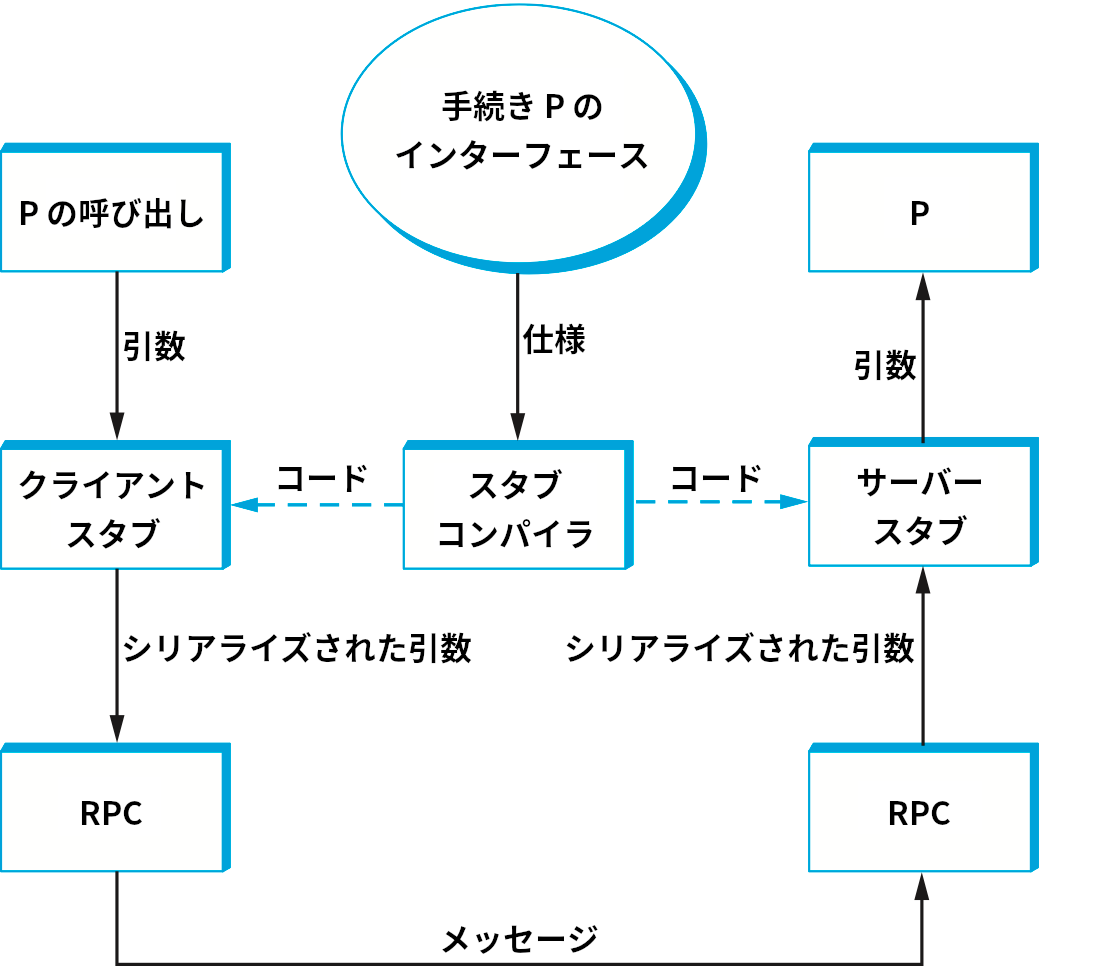
コンパイルベースのアプローチでは、それぞれの手続きがカスタマイズされたクライアントスタブとサーバースタブを持つ。スタブを手で書くこともできるものの、普通は手続きのインターフェースを記述した仕様からスタブコンパイラ (stub compiler) を使ってスタブを生成する。スタブコンパイラとスタブの関係を図 183 に示す。このアプローチではスタブがコンパイルされるので、実行速度は非常に速い。インタープリタベースのアプローチでは、システムが一般的なクライアントスタブとサーバースタブを持ち、そのパラメータが手続きのインターフェースの仕様によって設定される。仕様は簡単に変更できるので、このアプローチにはスタブが柔軟になる利点がある。実際によく使われるのはコンパイルベースのスタブである。
7.1.2 マーシャリングの例
以上の分類を使って、ネットワーク分野で用いられる四つの有名なマーシャリングシステム (XDR, ASN.1 BER, NDR, protobuf) を簡単に紹介する。これからそれぞれのシステムが整数をどのように表すかを示していく。
XDR
XDR (External Data Representation) は SunRPC で利用されるマーシャリングシステムである。XDR は次の特徴を持つ:
-
関数ポインタを除いて C の型システムを完全にサポートする。
-
正準な中間表現を定義する。
-
配列の長さを除いてタグを使わない。
-
コンパイルされるスタブを利用する。
XDR の整数は 32 ビットのデータアイテムであり、C の整数を符号化する。整数は 2 の補数で表され、C 整数の最上位バイトは XDR 整数の第一バイト、C 整数の最下位バイトバイトは XDR 整数の第四バイトとなる。つまり、XDR は整数の表現にビッグエンディアンを利用する。XDR は C と同様に符号付き整数と符号無し整数の両方をサポートする。
XDR は可変長配列を符号化するとき、要素数を表す 4 バイトの符号無し整数の後にそれだけの要素を続けて配置する。また、構造体の要素は宣言された順番で符号化される。配列と構造体の両方で、各要素のサイズは 4 バイトの倍数に切り上げられる。4 バイトより小さいデータ型は 4 バイトまで 0 で埋められる。ただし文字列はこの規則の例外で、文字列はバイトごとに符号化される。
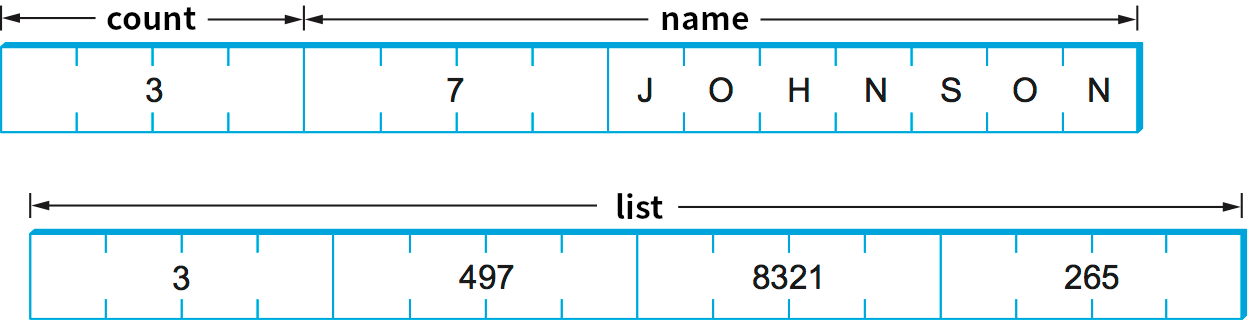
C の構造体を XDR ルーチンで符号化/復号する C コードの例を次に示す。このコードで item を符号化したときに XDR が作成する表現を 図 184 に示す。ここでは name が 7 文字の文字列で、list は 3 要素の配列だとしている。
#define MAXNAME 256;
#define MAXLIST 100;
struct item {
int count;
char name[MAXNAME];
int list[MAXLIST];
};
bool_t xdr_item(XDR *xdrs, struct item *ptr) {
return(xdr_int(xdrs, &ptr->count) &&
xdr_string(xdrs, &ptr->name, MAXNAME) &&
xdr_array(xdrs, &ptr->list, &ptr->count, MAXLIST, sizeof(int), xdr_int));
}
このコードに含まれる xdr_array, xdr_int, xdr_string は XDR が提供するプリミティブ関数であり、それぞれ配列、整数、文字列の符号化または復号を行う。引数の xdrs は XDR が処理中のメッセージに関する情報を記録するのに使うコンテキストを表す変数であり、上述のプリミティブ関数が符号化と復号のどちらを行うのかといった情報を保持する。このため、xdr_item のようなルーチンはクライアントとサーバーの両方が利用できる。アプリケーションプログラムは xdr_item のようなルーチンを手で書くこともできるが、rpcgen と呼ばれるスタブコンパイラを使って自動的に生成することもできる。後者の方法を使うとき、rpcgen は RPC 言語と呼ばれる言語で書かれた item 構造体の定義を入力として受け取り、対応するスタブを出力する。
XDR が実際に行う処理は当然データの複雑性によって異なる。例えば整数の配列という単純なケースでは、各整数を正しいバイトオーダーに変換してからコピーするだけとなる。これは 1 バイトにつき平均 3 命令なので、配列全体の変換はマシンのメモリ帯域に支配される可能性が高いことを意味する。データ型がこれより複雑になればバイトごとに必要な変換処理が増えて変換が CPU の処理速度に支配されるようになり、メモリ帯域よりも遅い速度でしか実行できなくなるだろう。
ASN.1 BER
ASN.1 (Abstract Syntax Notation One) はデータをネットワーク越しに転送するときの表現などを定義する ISO 規格である。ASN.1 のデータ表現に関する部分は BER (Basic Encoding Rules) と呼ばれる。ASN.1 BER は関数ポインタを除く C の型システムをサポートし、正準な中間表現を定義し、型タグを利用する。スタブはインタープリタで実行することもコンパイルして実行することもできる。ASN.1 BER は SNMP (Simple Network Management Protocol) と呼ばれるインターネット規格で使われたことで名前が知られている。
ASN.1 BER は各データアイテムを次の形をした三つ組で表現する:
(tag, length, value)
tag は通常 8 ビットであるものの、複数バイトのタグも定義できる。length は value の長さを表す (後述)。構造体などの複合データ型はプリミティブ型を入れ子にすることで表現される (図 185)。

value が 127 より小さければ、length は 1 バイトで表される。そのため、例えば 32 ビット整数を符号化すると type の 1 バイトと length の 1 バイト、そして整数を符号化した 4 バイトとなる 図 186。XDR と同様、ASN.1 は整数を符号化するときビッグエンディアンの 2 の補数表現を利用する。整数の表現は XDR と ASN.1 BER で全く同じであるものの、XDR では整数に type と length が関連付かないことに注目してほしい。二つのタグはメッセージの空間を占有し、さらに重要なこととして、マーシャリングの処理を必要とする。この事実は ASN.1 BER が XDR より性能に劣る理由の一つである。別の理由としては、全てのデータアイテムの前に tag フィールドと length フィールドがあるために自然なバイト境界にデータアイテムが収まらない (例えば整数がワード境界から始まらない) ことがある。この事実によって符号化と復号の処理が複雑になる。

value の長さが 128 バイト以上のとき、length は複数のバイトで表される。単一バイトで表せるのが 255 バイトではなく 127 バイトまでなのはどうしてだろうと思ったかもしれない。この理由は、length フィールドの 1 ビットが length フィールド自身の長さを示すのに使われるためである。length フィールドの最上位ビットが 0 のとき、length フィールドの長さは 1 バイトとなる。そして最上位ビットが 1 のとき、length フィールドの最初のバイトの下位 7 ビットは以降に続く length フィールドの長さを表す。1 バイトの length と複数バイトの length の例を図 187 に示す。
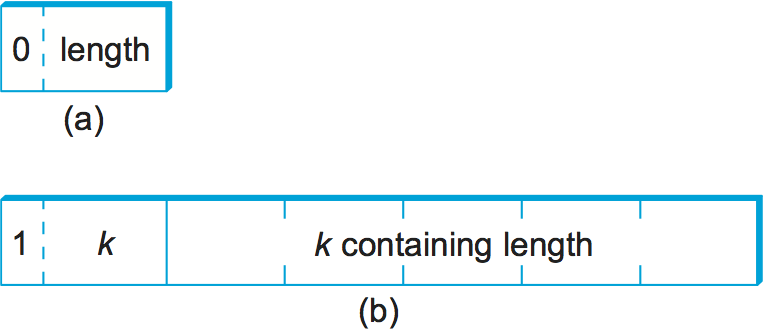
length フィールドの表現 (a) 1 バイト; (2) 複数バイト
NDR
NDR (Network Data Representation) は DCE (Distributed Computing Environment) で使われるデータ符号化規格である。XDR や ANS.1 BER と異なり、NDR は「受信者が帳尻を合わせる」方式を採用する。この方式を達成するために、NDR はメッセージの先頭にアーキテクチャを表すタグを挿入する。NDR はスタブの生成にスタブコンパイラを利用し、このスタブコンパイラに入力する仕様は IDL (Interface Definition Language) と呼ばれる言語で書かれる。IDL は C に非常に似ており、そのため基本的に C の型システムをサポートする。

アーキテクチャの定義で使われるタグを図 188 に示す。このタグは 4 バイトであり、全ての NDR メッセージの先頭に含まれる。先頭のバイトには 4 ビットのフィールドが二つ含まれる。一つ目のフィールド IngegrRep はメッセージに含まれる整数の表現を定義する: 0 はビッグエンディアンを表し、1 はリトルエンディアンを表す。二つ目の CharRep フィールドはメッセージに含まれる文字の表現を定義する: 0 は ASCII を表し、1 は EBCDIC と呼ばれる IBM が策定した ASCII の代替テクノロジを表す。続く FloatRep フィールドはメッセージに含まれる浮動小数点数の表現を定義する: 0 は IEEE 754、1 は VAX、2 は Cray、3 は IBM を表す。最後の 2 バイトは将来のために予約されている。なお、整数の配列といった単純なケースで NDR は XDR と同程度の処理を行うので、同程度のパフォーマンスを達成する。
protobuf
protobuf (Protocol Buffers) は言語とプラットフォームに依存しない形で構造化データをシリアライズする手段を提供し、多くの場合 gRPC と共に利用される。protobuf はタグと正準な中間表現を利用するアプローチを採用し、共通の .proto ファイルからクライアント用とサーバー用のスタブが両方とも生成できるようになっている。.proto ファイルは C 風の単純な構文を使って次のように書かれる:
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
required PhoneNumber phone = 4;
}
ここで message は C における typedef struct にほぼ対応する。他の部分は見れば分かると思うが、各フィールドに整数が割り当てられている点には説明が必要だろう。これは仕様が将来変化した場合でもフィールドを識別できるようにするために存在する。また、各フィールドは必須かどうかに応じて required または optional が付いている。
protobuf は varints (variable length integers, 可変長整数) と呼ばれる新しいテクニックを使って整数を符号化する。varints において整数を符号化する各バイトの最上位 1 ビットは常に「この整数を表すバイトが自分の後ろに続くかどうか」を表し、下位 7 ビットが 2 の補数表現で整数を符号化する。最初にシリアライズされるバイトは整数の最下位 7 ビットを符号化する。
この規則は小さい (127 以下の) 整数は 1 バイトで符号化され、128 より大きい整数は複数のバイトで符号化されることを意味する。例えば 2 は 0000 0010 と符号化され、265 は次のように符号化される:
1110 1101 0000 0010
先頭のバイトの最上位ビット 1 は、この整数の符号が次のバイトに続くことを表す。反対に、第 2 バイトの先頭ビット 0 は整数の符号がこのバイトで終わることを表す。このビット列を復号するには、まず整数の末尾かどうかを表す各バイトの最上位 1 ビットを捨てる:
1110 1101 0000 0010
→ 110 1101 000 0010
符号は最下位の 7 ビットから順に並んでいるので、このビット列を 7 ビットのグループの列として反転させ、その結果を 2 の補数表現として解釈すれば復号が完了する:
→ 000 0010 110 1101
→ 00000101101101
→ 256 + 64 + 32 + 8 + 4 + 1 = 365
より複雑なメッセージの符号化では、シリアライズされたバイトストリームをキーバリューペアの集まりと考えることができる。ここでキー (今までの議論で「タグ」と呼んできた部分) は二つの小部分からなる: フィールドの一意識別子 (.proto ファイルの例で各フィールドに割り当てられていた整数) と、値のワイヤタイプ (wire type) である。ここまでの例で登場した varint はワイヤタイプであり、他のワイヤタイプとしては固定長整数のための 32-bit と 64-bit や、埋め込まれたメッセージと文字列のための length-delimited がある。length-delimited が埋め込まれたメッセージを表す場合、その値から分かるのはメッセージ (構造体) の長さと内容だけであり、その解釈方法は同じ .proto ファイルに含まれる他のメッセージ仕様によって指定される。
7.1.3 マークアップ言語 (XML)
本節ではプレゼンテーションフォーマットの問題を RPC の視点から議論してきた ── クライアントプログラムとサーバープログラムがデータをやり取りするときにプリミティブなデータ型と複合型を符号化する方法を考えてきた。しかし、この問題は他の場面でも生じる。例えばウェブサーバーがウェブページを記述するとき、何を画面に表示すべきかを任意のブラウザに正確に伝えるにはどうするべきだろうか? この特定の問題に対しては、HTML (Hypertext Markup Language) という解答が存在する。HTML は表示すべき文字列は何か、太字あるいは斜体で表示すべき文字はどれか、使うべきフォントおよびサイズは何か、画像をどこに表示すべきかといった情報をブラウザに伝える。
数え切れないほど多様なウェブアプリケーションが生まれた結果として、異なるウェブアプリケーションがお互いにデータを理解できるようにしたいという要望が生まれることになった。例えば、電子通販サイトが運送会社のウェブサイトから商品の配送状況に関するデータを取得できれば、ユーザーは電子通販サイトを離れることなく配送状況を確認できる。これは RPC とよく似たシナリオであり、現在のウェブでウェブサーバー同士の通信は主に XML (Extensible Markup Language) という言語で行われる。XML はウェブアプリケーション同士がやり取りするデータを記述するのに使われる。
HTML や XML といったマークアップ言語 (markup language) はタグ付きデータのアプローチを極限まで突き詰めたものと言える。データはテキストで表され、データに関する情報はテキストの間に挿入されるマークアップと呼ばれるテキストのタグで表される。HTML ではマークアップが内側のテキストをどのように表示すべきかを示し、XML といった他のマークアップ言語ではマークアップがデータの型と構造を表現する。
正確に言うと、XML は様々なマークアップ言語を定義するためのフレームワークである。例えば、XML を使って定義された XHTML (Extensible Hypertext Markup Language) と呼ばれる HTML とほぼ同じマークアップ言語が存在する。XML はデータテキストとマークアップを書くための基礎的な構文を提供するだけであり、実際のマークアップの命名と定義は言語設計者に任せられる。XML ベースの言語が「XML」と呼ばれることも多いものの、入門書である本書では違いを強調する。
XML の構文は HTML の構文とよく似ている。従業員レコードを記述する XML ベースの言語の例を次に示す。XML は employee.xml といった名前のファイルに保存される。最初の行は XML のバージョンを表し、以降の行が 4 つのフィールドからなる従業員レコードを表す。最後の hiredate フィールドは 3 つのサブフィールドを持つ。ここから分かるように、XML は入れ子になったタグとバリューの組を表現するための構文を提供する。これはデータを木構造で表すのに等しい (この例では employee が根となる)。この木構造の表現は XDR, ASN.1 BER, NDR における複合型の表現と似ているものの、XML はプログラムと人間の両方が理解できる。さらに重要な事実として、XML ベースの言語の定義はプログラムから解釈可能なフォーマットで書かれるので、パーサーといったプログラムを異なる XML ベースの言語に対して使い回すことができる。
<?xml version="1.0"?>
<employee>
<name>John Doe</name>
<title>Head Bottle Washer</title>
<id>123456789</id>
<hiredate>
<day>5</day>
<month>June</month>
<year>1986</year>
</hiredate>
</employee>
この例ではテキストとして書かれたマークアップとデータを見ればそれぞれが何を意味するかを人間は大まかに理解できるものの、正当なタグ、タグの意味、タグに対応するデータ型を実際に定義するのはこの従業員レコード言語の定義である。タグの形式的な定義がなければ、人間もプログラムもその意味を正確には理解できない。例えば year フィールドの 1986 が文字列なのか、符号付き整数なのか、符号無し整数なのか、浮動小数点数なのかは定義が無ければ分からない。
XML ベースの言語はスキーマ (schema) で定義される。「スキーマ」はデータの集合を解釈するための仕様を指すデータベース用語である。XML 用のスキーマ言語はいくつか存在するが、ここでは最も一般的な XML Schema を紹介する。全く平凡な名前が付けられたこの規格で定義されたスキーマは XSD (XML Schema Document) と呼ばれる。上で示した従業員レコードに対応する XSD 仕様を次に示す。言い換えれば、次のテキストは上で示したドキュメントが準拠する言語を定義する。XSD は employee.xsd といった名前のファイルに保存される。
<?xml version="1.0"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<element name="employee">
<complexType>
<sequence>
<element name="name" type="string"/>
<element name="title" type="string"/>
<element name="id" type="string"/>
<element name="hiredate">
<complexType>
<sequence>
<element name="day" type="integer"/>
<element name="month" type="string"/>
<element name="year" type="integer"/>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
XSD の見た目が XML と似ていることに気が付いたかもしれない。これは偶然ではない: XML Schema 自身も XML ベースの言語である。この XSD と上述の XML には明らかな関連が存在する。例えば 7 行目の
<element name="title" type="string"/>
は、マークアップ title で囲まれる値は文字列として解釈すべきであることを表す。この行の位置からは、title フィールドは従業員レコードの二つ目の要素として現れなければならないことが分かる。
一部のスキーマ言語と異なり、XML Schema は文字列、整数、十進整数、真偽値といったデータ型を提供する。また、employee.xsd の例からも分かるように、データ型を並べたり入れ子にしたりすることで複合データ型を作成できる。そのため XSD が定義するのは構文だけではない: XSD は独自の抽象データモデルを定義する。特定の XSD に準拠するドキュメントはその XSD によって定義されるデータモデルに準拠するデータの集合を表現する。XSD が構文だけではなく抽象データモデルを定義することがなぜ重要かと言えば、そのモデルに準拠するデータの表現を XML 以外の方法でも記述できるようになるためである。
低レベルな表現として見たとき、XML に欠点があることは否定できない: 他のデータ表現ほどコンパクトではなく、パースにも時間がかかる。バイナリで記述される代替表現がいくつも使われている。ISO (International Standards Organization, 国際標準化機構) は Fast Infoset を策定しており、W3C (World Wide Web Consortium) は EXI (Efficient XML Interchange) を提案している。こういったバイナリ表現は人間にとっての読みやすさを犠牲にすることで容量とパース速度を向上させる。
XML 名前空間
XML は名前の衝突という一般的な問題を解決する必要がある。この問題は XML Schema といったスキーマ言語が特定のスキーマを別のスキーマの一部として再利用する機能をサポートするために生じる。独立して定義された二つの XSD が idNumber という同じ名前のマークアップを使っていたとしよう。一つの XSD は企業の従業員を idNumber で識別し、もう一つの XSD は企業が保有するノート PC を idNumber で識別するのかもしれない。このとき、従業員に割り当てられた備品を管理する三つ目の XSD が二つの XSD を両方取り込む場合、二つの idNumber を区別する手段が必要になる。
XML は名前の衝突という問題を XML 名前空間 (XML namespace) で解決する。名前空間は名前の集合を表す。それぞれの XML 名前空間は URI (Uniform Resource Identifier) によって識別される。URI については後述するが、ここでは URI はグローバルに一意な識別子だと考えてほしい (HTTP で使われる URL は URI の一種である)。マークアップに使われる idNumber のような単純名 (simple name) は名前空間の中で一意である限りその名前空間に加えることができる。名前空間はグローバルに一意であり、単純な名前は名前空間の中で一意なので、二つを組み合わせた修飾名 (qualified name) はグローバルに一意で衝突しないことが保証される。
XSD では対象名前空間 (target namespace) を次のように指定する:
targetNamespace="http://www.example.com/employee"
右辺は URI であり、名前空間を識別する。対象名前空間が指定された XSD で定義されるマークアップは全てその名前空間に属する。
他の XSD で定義された名前を参照するときは、名前の先頭に名前空間接頭辞 (namespace prefix) を付けて修飾する。名前空間接頭辞は名前空間を識別する URI に割り当てられる省略された名前であり、異なる名前空間を識別するために利用される。例えば、次の行は名前空間 http://www.example.com/employee に対する名前空間接頭辞として emp を割り当てる:
xmlns:emp="http://www.example.com/employee"
こう書かれていれば、この名前空間に含まれるマークアップはその名前の前に emp: を付けることで参照できる。例えば次の行は名前空間 http://www.example.com/employee に含まれるマークアップ title を参照している:
<emp:title>Head Bottle Washer</emp:title>
emp:title は修飾された名前であり、他の名前空間に含まれる name と衝突することはない。
XML が使われる場面はウェブベースのサービスにおける RPC スタイルの通信から業務効率化ツール、そしてインスタントメッセージングなど驚くほど多岐にわたる。現在のインターネットで上方の層が依存する中心的プロトコルの一つが XML であることに疑いの余地はない。