2.3 フレーム化
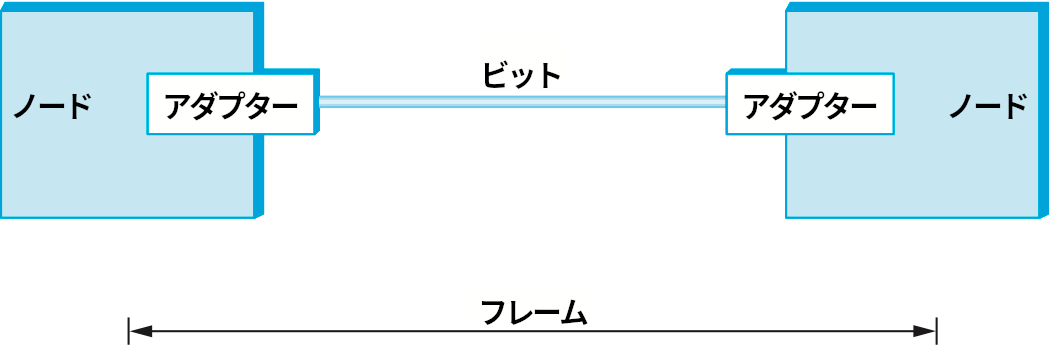
前節ではビット列をポイントツーポイントリンク越しに ── アダプターからアダプターへと ── 転送する方法を見た。続いて図 26 のようなシナリオを考えよう。第 1 章で説明したように、本書では議論をパケット交換ネットワークに集中させる。パケット交換ネットワークでノード同士が交換するのは単なるビット列ではなくデータのブロックである。このブロックは今考えているレベルではフレーム (frame) と呼ばれ、ノード同士でフレームをやり取りできるようにしているのはネットワークアダプターである。ノード A がノード B にフレームを転送したいと思ったとき、ノード A はメモリ上に存在するフレームの転送を自身のネットワークアダプターに要求する。この要求の結果としてフレームを表すビット列がリンク越しに送信される。その後ノード B のネットワークアダプターはリンクから到着したビット列を収集して B のメモリに格納する。フレームが正確にどのビットから構成されるか ── つまり、フレームがどこで始まってどこで終わるのか ── を認識することがネットワークアダプターにおける主要な課題となる。
フレーム化の問題を解決する方法はいくつかある。本節では設計空間の様々な点を説明するために三つの異なるプロトコルを示す。なお、これからポイントツーポイントリンクの文脈でフレーム化を議論するものの、フレーム化はイーサネットや Wi-Fi などの多元接続ネットワークでも解決しなければならない基礎的な問題であることに注意してほしい。
2.3.1 バイト指向プロトコル (PPP)
フレーム化の問題に対する最も古いアプローチの一つ ── 端末をメインフレームに接続するプロトコルにルーツを持つ ── は、フレームをビットの集合ではなくバイト (文字) の集合として扱う。こういったバイト指向プロトコル (byte-oriented protocol) の例として、1960 年代後半に IBM が開発した BISYNC (Binary Synchronous Communication) プロトコル、そして 1975 年に DEC (Digital Equipment Corporation) が開発した DECnet で使われた DDCMP (Digital Data Communication Message Protocol) がある (大昔には、IBM や DEC のような大企業は顧客向けにプライベートネットワークを構築していた)。広く使われる PPP (Point-to-Point Protocol) もバイト指向プロトコルの例である。
大まかに言うと、バイト指向のフレーム化には二つのアプローチがある。第一に、フレームの始まりと終わりを番兵 (sentinel) の役割を果たす特殊文字で表すアプローチがある。フレームの始まりは特殊文字 SYN (synchronization) で表され、フレームの本体は二つの特殊文字 STX (start of text) と ETX (end of text) で囲まれる。この番兵を使ったアプローチでは、当然ではあるが、特殊文字がフレームの本体に出現する可能性がある事実が問題となる。この問題に対する標準的な対処として、フレームの本体で制御文字が出現するたびに DLE (data-link-escape) 文字を前に付けて「エスケープ」する手法がある。DLE 文字自身も (DLE 文字を前に付けることで) エスケープされる (C プログラマーは、この仕組みが文字列リテラルの中でクエスチョンマークなどをエスケープする方法に似ていることに気付くだろう)。このアプローチはフレームの本体に本来存在しない文字を挿入するので、文字詰め (character stuffing) と呼ばれる。
もう一つのアプローチとして、フレームの先頭に付くヘッダーにフレームの長さを含めることでフレームの終端を伝えるアプローチがある。DDCMP はこのアプローチを利用した。このアプローチには、フレームの長さを表すフィールドが転送中のエラーで破損するとフレームの終端が正しく認識されない危険性がある (同様の問題は終端を番兵で表すアプローチで ETX フィールドが破損したときにも発生する)。万一これが起こると、受信側は誤ったフィールドが表すだけのバイトを読み、その後の誤り検出フィールドによる判定でフレームの破損を検出することになる。これはフレーム化誤り (framing error) と呼ばれる。フレーム化誤りを検出すると、受信側は次のフレームの開始を示す SYN 文字が来るまで何もせずに待機する。そのため、あるフレームで起こったフレーム化誤りによってそれ以降のフレームがいくつか正しく受信されなくなることがあり得る。
PPP (Point-to-Point Protocol) は様々なポイントツーポイントリンクでインターネットプロトコルのパケットを伝達するのに広く使われるプロトコルであり、番兵と文字詰めを利用する。PPP のフレームフォーマットを図 27 に示す。

こういったフレームやパケットのフォーマットを示す図は本書で何度も登場するので、初登場となるここで少し説明をしておいた方がいいだろう。こういった図でパケットやフレームはラベルの付いたフィールドの並びとして表され、各フィールドの上には長さ (ビット数) を示す数字が付く。また、パケットは最も左にあるフィールドから送信される。
では 図 28 を説明しよう。Flag フィールドはフレームの区切りを示す特殊文字 01111110 である。Address フィールドと Control フィールドは多くの場合デフォルト値なので説明は必要ない。Protocol フィールドは逆多重化に利用され、IP といった上位プロトコルを特定する。ペイロードのサイズは交渉可能であり、デフォルトでは 1500 バイトとなる。CheckSum フィールドは 2 バイト (デフォルト) または 4 バイトの長さを持つ。なお、その名前と異なり、実際に CheckSum フィールドに含まれるのはチェックサムではなく CRC である (次節で詳しく説明される)。
PPP のフレームフォーマットはサイズが固定されておらず交渉で変更可能なフィールドが存在する点が変わっている。この交渉は LCP (Link Control Protocol) と呼ばれるプロトコルで行われる。PPP と LCP は連携して動作する: LCP は制御メッセージを PPP フレームにカプセル化して ── Protocol フィールドが LCP の識別子になった PPP フレームとして ── 送信し、その制御メッセージに含まれる情報に基づいて PPP のフレームフォーマットが変更される。両端のピアがリンクを通じた通信が行える (例えば受光器が光ファイバーを通してもう一方からの信号を受け取れる) ことを検出した後の接続確立にも LCP は使われる。
2.3.2 ビット指向プロトコル (HDLC)
バイト指向プロトコルと異なり、ビット指向プロトコル (bit-oriented protocol) はバイトの区切りを気にかけない ── フレームは単なるビットの並びとみなされる。ビットは ASCII のような文字集合に含まれる文字を表しているかもしれないし、画像のピクセル値、あるいは実行ファイルに含まれる命令とオペランドかもしれない。IBM が開発した SDLC (Synchronous Data Link Control) プロトコルはビット指向プロトコルの例である。SDLC は後に ISO によって標準化され、HDLC (High-Level Data Link Control) プロトコルとなった。本項では HDLC を例として用いる。図 28 に HDLC のフレームフォーマットを示す。

HDLC はフレームの先端と終端の両方を区切り用のビット列 01111110 で表す。このビット列は送信側と受信側のクロックを同期させるためにリンクが待機状態のときいつでも送信できる。ある意味では、PPP と DHLC の両方が番兵のアプローチを利用すると言える。番兵のビット列はフレーム本体の任意の位置に現れる可能性がある ── バイト境界をまたいで現れる可能性もある ── ので、ビット指向プロトコルにも特殊文字 DLE を挿入する文字詰めのような処理が存在する。この処理はビット詰め (bit stuffing) と呼ばれる。
ビット詰めは次のように動作する。まず送信側は、フレームを区切るビット列 01111110 以外のメッセージの本体で 1 が五つ連続するとき次のビットを送る前に 0 を挿入する。受信側は、1 を連続で五つ受け取ったときに次のビット (五つの 1 に続くビット) に応じて処理を切り替える: 次のビットが 0 なら、そのビットは挿入されたものなので受信側はそれを無視する。次のビットが 1 なら、考えられる状況は二つある:
- 現在フレームの終端を読んでいる。
- 受け取っているビット列に誤りが含まれる。
この場合さらに次のビットを見ることで、この二つのケースを判別できる。もし次のビットが 0 (つまり直近 8 ビットが 01111110) なら、フレームの終端だと分かる。そうではなく次のビットが 1 (つまり直近 8 ビットが 01111111) なら、どこかに誤りがあったことが確実なのでそのフレームは全て破棄しなければならない。後者のケースでは、受信側は次の 01111110 まで読み飛ばしてから受信を再開する必要がある。そのためビット誤りが起こると受信側は二つの連続したフレームを受信し損ねる可能性がある。なお、この手法でフレーム化誤りを検出できない可能性はもちろんある (例えばビット誤りによってフレームの終端が生成されたときなど)。誤りを検出するロバストな手法については以降の節で見る。
文字詰めおよびビット詰めの興味深い特徴として、フレームのサイズが送ろうとしているペイロードの内容によって変化することが挙げられる。全てのフレームのサイズを強制的に同じにすることはできるものの、そのときはフレームごとに送られるデータのサイズが一定でなくなる (もし納得できないなら、ペイロードの最終バイトが ETX 文字である場合に何が起こるかを考えてみてほしい)。全てのフレームが同じサイズとなるフレーム化手法は次項で説明される。
2.3.3 クロックベースのフレーム化 (SONET)
フレーム化の三つ目のアプローチとして、SONET (Synchronous Optical Network, 同期光ネットワーク) に代表されるアプローチがある。このアプローチを指す広く知られた一般的な用語が無いので、本書ではクロックベースのフレーム化 (clock-based framing) と呼ぶ。SONET は光ファイバーを通じたデジタル通信のためにベル通信研究所 (Bellcore) で最初に提案され、ANSI (American National Standards Institute, 米国国家規格協会) で策定された。また、ITU-T (国際電気通信連合電気通信標準化部門) は SONET をベースに SDH (Synchronous Digital Hierarchy) と呼ばれる仕様を策定している。SONET は長年にわたり光ファイバーを通じた長距離データ転送における支配的な規格であり続けている。
SONET を詳しく説明する前に、SONET の完全な仕様は本書よりはるかに長い事実を指摘しておく。そのため、以降の議論は規格の要点に触れることしかできない。SONET はフレーム化の問題と符号化の問題を両方とも解決し、加えて電話会社にとって非常に重要な、高速回線でいくつかの低速回線を多重化する問題も解決する (実は、電話会社が古くから通話に使ってきた大量の 64 Kbps チャンネルを多重化する必要がある事実は SONET の設計の様々な部分に影響を及ぼしている)。ここでは SONET のフレーム化に対するアプローチを議論し、他の話題は後に回す。
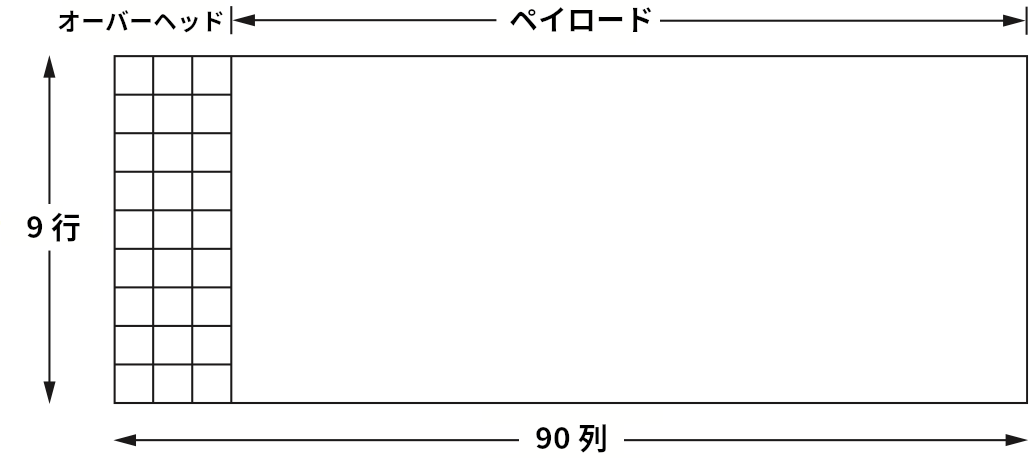
これまでに議論したフレーム化方式と同様に、SONET フレームはフレームの先頭と終端を受信側に伝えるための特別な符号を持つ。しかし、似ている部分といえばそれくらいしかない。特に文字詰めとビット詰めが使われないので、フレームの長さは送信されるデータの中身に依存しない。このとき「フレームがどこで始まってどこで終わるかを受信側はどうやって知るのか?」という疑問が生じる。これから最も低速な SONET リンク (STS-1 と呼ばれる 51.84 Mbps のリンク) を例として用いてこれを説明する。図 29 に STS-1 フレームの構造を示す。90 バイトの行が 9 個並んでおり、各行は先頭 3 バイトがオーバーヘッド1、残りがリンクで転送されるデータのための空間となっている。フレームの先頭 2 バイトは特別なビットパターンであり、受信側はこのパターンを使ってフレームの先頭を検出する。しかし文字詰めとビット詰めが使われないので、フレームの先頭を表す 2 バイトのパターンがペイロードに現れない保証はない。この事実に対処するため、受信側はこのパターンを定期的にチェックする。各フレームは 9 × 90 = 810 バイトなので、このパターンは 810 バイトごとに現れると期待される。受信側は、このパターンを 810 バイトごとに十分多く検出できたときに通信が同期されていると判断し、フレームを (正しく) 解釈する。
その他のオーバーヘッドバイトの使い道については複雑なので省略する。SONET が複雑な原因の一つとして、SONET が単一の回線だけではなくキャリアの光ネットワークでも利用される事実がある (我々は現在キャリアがネットワークを実装する事実を無視しており、キャリアから SONET 回線を借りれば独自のパケット交換ネットワークを構築できる事実に注目している)。また SONET はデータ転送だけではなく非常に幅広いサービスを提供する事実からも SONET は複雑になる。例えば SONET 回線の容量のうち 64 Kbps は管理用の音声チャンネルとして確保される。
SONET フレームのオーバーヘッドバイトは NRZ で符号化される。NRZ は前節で紹介した単純な符号化であり、1 は high 信号に、0 は low 信号に符号化される。ただし、送信側のクロックを受信側で確実に回復できるだけの遷移が信号に含まれることを保証するために、ペイロードバイトに対してはスクランブル (scramble) が加えられる。具体的には、実際のデータと事前に定められたビットパターンの排他的論理和 (XOR) が送信される。このビットパターンは 127 ビットであり、1 から 0 への遷移を十分多く含む。そのパターンとの XOR を取ることで、転送されるデータにはクロック回復を可能にするのに十分な個数の遷移が高い確率で含まれるようになる。
SONET は複数の低速回線の多重化を次のようにサポートする。任意の SONET 回線は事前に定められた有限個のレートのいずれかで動作する。このレートには名前が付いており、51.84 Mbps を表す「STS-1」から 39,813,120 Mbps を表す「STS-768」まで存在する2。これらのレートは全て STS-1 の整数倍となっている。フレーム化で重要なのが、あるレートの SONET フレームにそれより低いレートの SONET フレームをいくつか入れられることである。もう一つの重要な特徴として、SONET フレームの長さは 125 μs で統一されている。これは、例えば STS-1 の SONET フレームは 810 バイトであり、STS-3 の SONET フレームは 2430 バイトであることを意味する。二つの特徴の相乗効果に注目してほしい: 3×810 = 2430 だから、STS-3 のフレームには STS-1 のフレームがちょうど 3 つ収まる。
簡単に言うと、STS-N フレームは STS-1 フレームが N 個集まったものとみなせる。ここで各 STS-1 フレームのバイトは交互に並べられる: 最初に一つ目の STS-1 フレームから 1 バイト、次に二つ目の STS-1 フレームから 1 バイト、以下同様となる。STS-1 フレームのバイトが交互に並べられるのは、各フレームを同じペースで転送するためである。つまり、各フレームは受信側にスムーズな 51.84 Mbps で届き、125 μs の 1/N ごとに特定のフレームが一気に届きはしない。
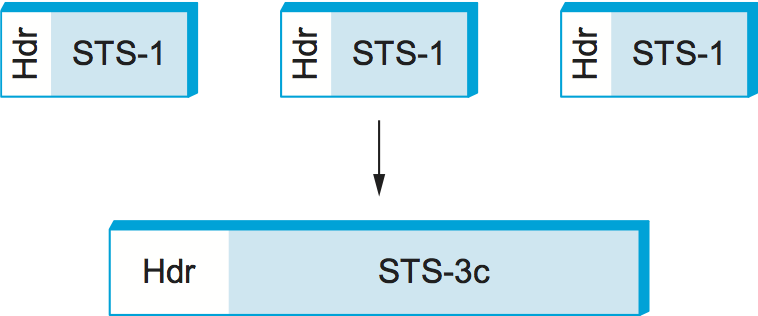
1 つの STS-N フレームが N 個の STS-1 フレームを多重化するのに利用されると考えられるのに加えて、N 個の STS-1 フレームのペイロードをまとめて一つの大きな STS-N ペイロードと考えることもできる。そのようにみなされるリンクを STS-Nc と表記する (c は concatenated の略)。オーバーヘッドの一部はこの用途のために使われる。3 つの STS-1 フレームが連結して 1 つの STS-3c フレームとなる様子を図 30 に示す。SONET 回線を STS-3 だけではなく STS-3c としても扱えることの重要性は、STS-3 は正確に言えばたまたま同じ光ファイバーケーブルを共有する 3 つの 51.84 Mbps 回線であるのに対して、STS-3c は一つの 155.25 Mbps 回線である点にある。
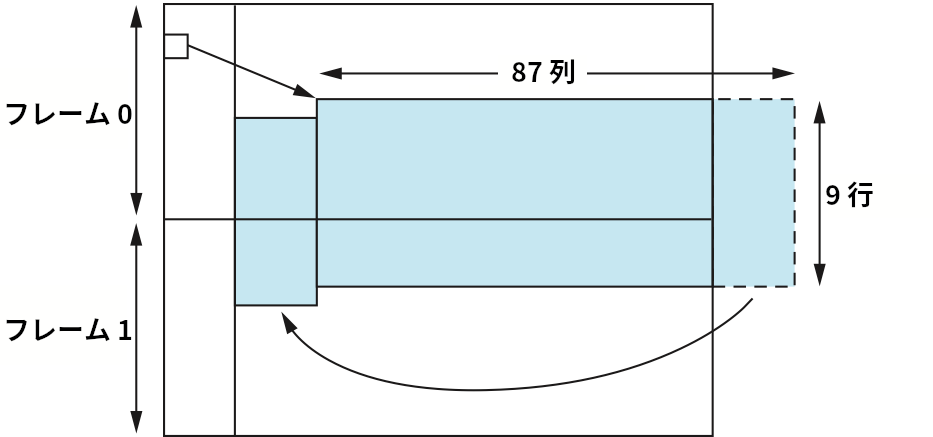
最後に、ここまでの SONET フレームの説明は各フレームのペイロードが一つのフレームに完全に収まると仮定している点で単純化が過ぎる。実は、これまでに説明した STS-1 フレームはフレームのプレースホルダーと考えるべきであり、実際のペイロードはフレームの境界をまたいで移動する。この状況を図 31 に示す。ここでは STS-1 ペイロードが二つの STS-1 フレームをまたいでおり、そのペイロードは右にシフトされて折り返しが起こっている。フレームのオーバーヘッドにはペイロードの先頭を指すフィールドが含まれる。キャリアのネットワーク全体で利用されるクロックを同期するという、キャリアが多くの労力をかけて取り組む問題が単純化される点にこの機能の価値がある。
-
訳注: 送信したいデータとは別に付け足されるヘッダーやトレイラーなどのデータを総称してオーバーヘッドと言う。 ↩︎
-
STS は Synchronous Transport Signal (同期通信信号) を意味する。STS に似た単語として OC (Optical Carrier, 光キャリア) がある。OC は SONET フレームを伝達する下位の光信号について話すときに使われる。STS と OC がなぜ似ていると言えるかといえば、どちらも同じ転送レートを表すため、例えば STS-3 と OC-3 は両方とも 155.25 Mbps の転送レートを表すためである。ここではフレーム化を話題にしているので STS を使うものの、光回線が「OC」の名前で呼ばれることもある。 ↩︎