5.2 確実なバイトストリーム (TCP)
UDP などの単純な逆多重化プロトコルと対照的に、より高度なトランスポートプロトコルはコネクション指向の確実なバイトストリームサービスを提供する。アプリケーションがデータの損失や入れ替わりを気にする必要がなくなるので、こういったサービスは様々な種類のアプリケーションで有用なことが示されている。この種のプロトコルでおそらく最も広く使われているのはインターネットの TCP (Transmission Control Protocol) であり、加えて TCP は最も注意深く調整が加えられているプロトコルでもある。この二つの事実があるので、本節では TCP を詳しく見ていく。ただし節の最後では TCP 以外に考えられる設計の選択肢も議論する。
本章の最初で示したトランスポートプロトコルの特徴で言うと、TCP はバイトストリームの順序を保った確実な転送を保証する。TCP は全二重のプロトコルであり、一つの TCP 接続を使って両方向にバイトストリームを転送できる。さらに TCP はフロー制御の仕組みを持ち、送信側が一定時間ごとに送信するデータの量を受信側から制限できる。最後に、TCP は UDP と同様に逆多重化の仕組みを持ち、一つのホスト上の複数のアプリケーションが同時にそれぞれの相手と通信できる。
これらの機能に加えて、TCP は非常に細かく調整された輻輳制御の仕組みを持つ。輻輳制御とは、ネットワークに負荷がかかり過ぎないように送信側がデータを送る速度を抑えることを言う (受信側がデータを処理しきれなくなるのを避けるためではない)。TCP の輻輳制御は次章でネットワークのリソースを公平に割り当てる仕組みという広い文脈の中で議論する。
輻輳制御とフロー制御は混同されることが多いので、両者の違いを繰り返しておく。フロー制御 (flow control) は受信側の処理能力を超えるデータを送らないように送信側が調整することを言う。これに対して輻輳制御 (congestion control) はネットワーク内のスイッチやリンクの処理能力を超えるデータを送らないように送信側が調整することを言う。つまりフロー制御はエンドツーエンドの対話における問題であり、輻輳制御はホストとネットワークの対話における問題である。
5.2.1 エンドツーエンドの問題
TCP の心臓部にはスライディングウィンドウアルゴリズムがある。これはリンクレベルでよく使われるものと同じ基本的なアルゴリズムではあるものの、TCP は物理的なポイントツーポイントリンクではなくインターネットの上で実行される事情があるので、数多くの重要な相違点がある。本項ではこの相違点を見ていきながら、それがどのように TCP を複雑にしているかを説明する。
第一に、以前に示したリンクレベルのスライディングウィンドウアルゴリズムは常に同じ二つのコンピューターを結ぶ単一の物理リンク上で実行されたのに対して、TCP はインターネット上にある任意の二つのコンピューター上で実行されるプロセス同士の論理的な接続をサポートする。これは通信の両側がデータのやり取りを行うことに合意する明示的な接続確立フェーズが TCP で必要になることを意味する。この違いは専用電話回線を使わない場合に電話番号を毎回ダイヤルしなければならないのに似ていると言える。接続確立フェーズでは、スライディングウィンドウアルゴリズムの開始に必要な両者で共有される状態の作成などが行われる。また、TCP は明示的な接続の終了 (teardown) フェーズを持つ。接続終了フェーズは両ホストで共有される状態を破棄して構わないことを知らせるために存在する。
第二に、単一の物理リンクは常に同じ二つのコンピューターを固定された RTT (ラウンドトリップタイム) で結ぶのに対して、TCP の接続はそれぞれが大きく異なる RTT を持つ。例えばサンフランシスコにあるホストとボストンにあるホストを結ぶ TCP 接続は数千キロの長さを持つので、100 ms 程度の RTT を持つかもしれない。しかし同じ部屋にある二つのホストを結ぶ TCP 接続は数メートルしか離れていないので、RTT はわずか 1 ms 程度となるだろう。二つの接続を同じ TCP プロトコルで扱える必要がある。さらに問題を難しくするのが、サンフランシスコとボストンのホストを結ぶ TCP 接続の RTT は午前三時には 100 ms であっても、午後三時には 500 ms になる可能性がある事実である。RTT の変化は数分だけ保持される単一の TCP 接続でもあり得る。これはスライディングウィンドウアルゴリズムにおいて、再送を行うタイムアウトの仕組みが RTT の変化に適応できる必要があることを意味する (もちろんポイントツーポイントリンクでもタイムアウトまでの時間は設定可能なパラメータでなければならない。しかしポイントツーポイントリンクでは、結ばれるノードが同じならタイムアウトまでの時間を後から変化させる必要はない)。
第三に、複数のパケットをインターネット越しに送信すると順序が変わって相手に届く可能性がある。物理的なポイントツーポイントリンクでは最初に入れたパケットが必ず反対側で最初に出てくるので、順序が変わることはあり得ない。パケットの順序が少し前後するだけなら、スライディングウィンドウアルゴリズムのシーケンス番号を使えば正しく並べ替えられるので問題はない。本当の問題はパケットの順序がどれだけ前後する可能性があるのか、言い換えれば、パケットが宛先に到着するまでに最大でどれだけ遅れるのかである。最悪のケースでは、パケットは TTL (time to live, 寿命) が 0 になるまでインターネットをさまよってから破棄される (そのためパケットが任意に遅れて到着する心配はない)。IP は TTL が 0 になったパケットを破棄するので、TCP は各パケットに最大の寿命が存在すると仮定する。正確な寿命の値は MSL (maximum segment lifetime) と呼ばれ、エンジニアリングの対象となる。現在推奨される MSL の値は 120 秒である。MSL の推奨値が 120 秒である事実を IP は関知しないことに注意してほしい。MSL は TCP が仮定する IP パケットの寿命の保守的な推定値に過ぎない。MSL の存在が意味することは大きい: TCP で受信側は非常に古いパケットが突然現れても問題ないように準備をしておかなければならず、スラインディングウィンドウアルゴリズムが複雑になる。
第四に、ポイントツーポイントリンクで結ばれるコンピューターは通常そのリンクをサポートできるようになっている。例えば、リンクの帯域遅延積が 8 KB ── 任意の時点で確認応答が届いていないデータが 8 KB 存在できるようにウィンドウのサイズを選ぶ必要があることを意味する ── なら、リンクの両端にあるコンピューターは少なくとも 8 KB のデータをバッファする機能を持つ可能性が高い。そうでないシステムを設計するのは馬鹿げている。一方で、インターネットにはあらゆる種類のコンピューターが接続できるので、それぞれの TCP 接続に割り当てられるリソースの格差が非常に大きい。特に、どのホストも数百の TCP 接続を同時にサポートできることを考えるとなおさらである。このため、反対側のホストが接続に割り当てられるリソース (例えばバッファの量) を「学習」する仕組みが TCP に必要になる。これはフロー制御の問題と言える。
第五に、物理的なポイントツーポイントリンクに帯域より多いデータを送信するのは不可能であり、リンクにデータを注ぎ込むホストは必ず一つしか存在しない。そのためリンクで知らず知らずのうちに輻輳が起こることはあり得ない。言い換えれば、リンクの負荷は送信側が持つパケットのキューを見れば分かる。これに対して、TCP 接続の送信側はパケットが宛先に到達するまでに使われるリンクに関して何の知識も持たない。例えば、送信側のマシンが比較的高速な ── 10 Gbps でデータを送れる ── イーサネットで接続されていたとしても、ネットワークの途中で 1.5 Mbps のリンクを通らなければならないかもしれない。さらに悪いことに、多くの異なる送信元から送られたデータがこの遅いリンクを通ろうとする可能性がある。これはネットワークの輻輳という問題であり、次章で議論される。
最後に、順序が保たれる確実な転送サービスを提供するための TCP のアプローチを、歴史的に重要な X.25 ネットワークのような仮想回線ベースのネットワークで使われるアプローチと比較してエンドツーエンドの議論を終える。TCP では下位の IP ネットワークが行うパケット転送が順序を保持せず、確実でもないと仮定される。TCP はスライディングウィンドウアルゴリズムをエンドツーエンドで (両端にあるホストで) 実行することで順序を保った確実な転送を提供する。これに対して、X.25 ネットワークではスライディングウィンドウアルゴリズムを使ったプロトコルがホップバイホップで (全てのリンクの両端にあるホストで) 利用される。このアプローチの背後にある仮定は「送信元ホストと宛先ホストを結ぶ経路上の全てのリンクの間でメッセージが順序を保って確実に転送されるなら、エンドツーエンドのサービスも順序を保った確実な転送を提供するだろう」というものである。
後者のアプローチの問題点は、ホップごとに順序を保った確実な転送を保証しても、必ずしもエンドツーエンドでそれを保証したことにはならない点にある。第一に、もし経路の片方の端に不均一なリンク (例えばイーサネット) が追加されたら、このホップが他のホップと同様のサービスを提供する保証は存在しない。第二に、スライディングウィンドウアルゴリズムを使ったプロトコルがノード A からノード B、およびノード B からノード C への正しい転送を保証したとしても、ノード B が完璧に振る舞う保証はどこにも存在しない。例えば、ネットワークノードは入力バッファから出力バッファにデータを移すときにミスをするかもしれないし、誤ってメッセージの順序を入れ替えるかもしれない。このような危険性が (可能性は非常に低いものの) 存在するので、順序を保った確実なサービスを本当に保証するには (下位のシステムが同じ機能を実装したとしても) エンドツーエンドでの検証がどうしても必要になる。
教訓
この議論は、最も重要なシステム設計指針の一つエンドツーエンド原理 (end-to-end principle) の例を示している。簡単に言うと、エンドツーエンド原理は「ある機能 (今の例であれば順序を保った確実な転送の提供) をシステムの下位のレベルで一切の間違いなく完全に実装できないなら、そのレベルで提供するべきではない」と主張する。この原理に従えば TCP/IP のアプローチが望ましいと言える。ただしエンドツーエンド原理は絶対ではなく、パフォーマンスの最適化のために下位のレベルで不完全な機能を提供することは許される。そのため、ホップバイホップで誤り検出 (例えば CRC) を行うのはエンドツーエンド原理に反していない: あるホップで生じたパケットの破損を検出してその場で再送を行うのは、データ全体をエンドツーエンドで再送するより望ましい。
5.2.2 セグメントのフォーマット
TCP はバイト指向プロトコルであり、送信側は TCP 接続にバイト列を書き込み、受信側は TCP 接続からバイト列を読み出す。TCP はアプリケーションに「バイトストリーム」を提供すると表現されるものの、TCP 自身は個別のバイトを別々にインターネットで転送するわけではない。送信プロセスからのデータはそれなりの大きさのパケットに収まるサイズになるまで送信バッファにデータに貯められる。宛先ホストの TCP は受け取ったパケットの中身を全て受信バッファに移し、受信プロセスはそのバッファから好きなペースで読み取りを行う。この様子を図 127 に示す。ここでは図を簡単にするためにデータが一方向に流れるものとしているが、一般に TCP は両方向のバイトストリームをサポートする。
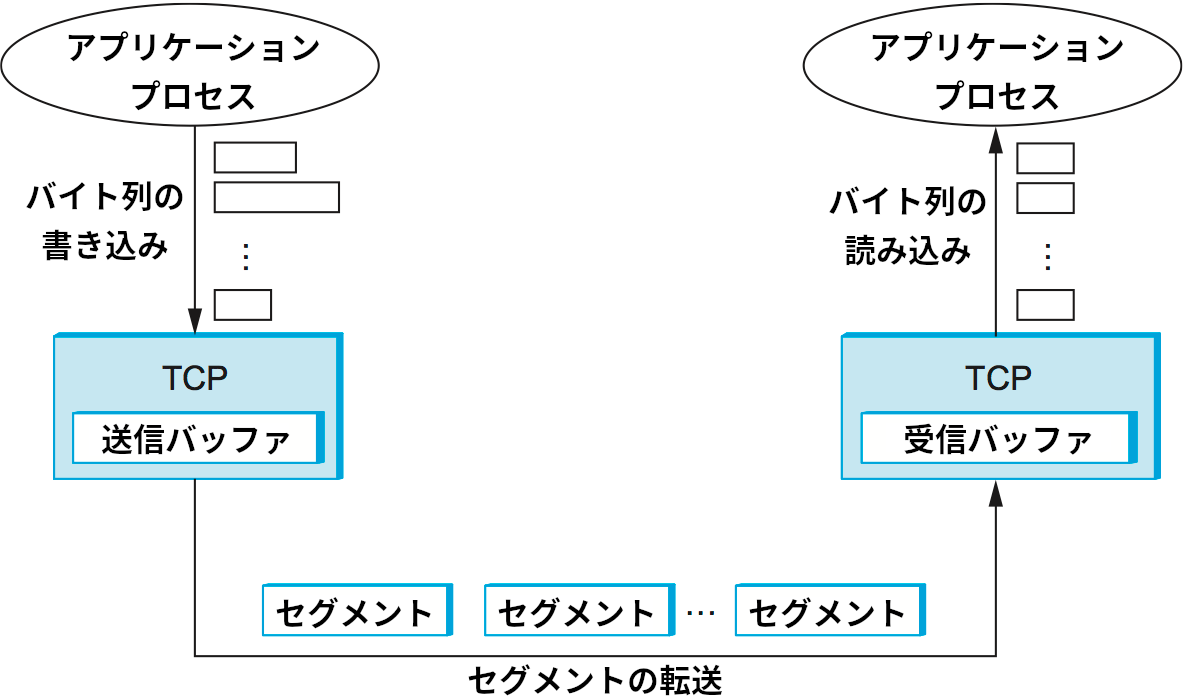
TCP ピアの間で交換されるパケットはバイトストリームの断片なので、セグメント (segment) と呼ばれる。各 TCP セグメントは図 128 に示すヘッダーを持つ。様々なフィールドの関連性は本節を通じて解説される。ここでは簡単な紹介だけに留める。

SrcPort フィールドと DstPort フィールドはそれぞれ送信元ポートと宛先ポートを識別する。UDP と同様に、この二つのフィールドと送信元 IP アドレスと宛先 IP アドレスが TCP 接続を一意に識別する。つまり、TCP の逆多重化鍵は次の 4 要素のタプルで表される:
(SrcPort, SrcIPAddr, DstPort, DstIPAddr)
クローズされた TCP 接続は再利用される点に注意してほしい。つまり特定のポートの組を結ぶ TCP 接続が確立され、データの送受信が行われてから閉じられると、後で同じポートの組が別の接続で使われることがあり得る。この状況を指して「同じ接続が異なる形で二回具象化 (incarnate) された」と言うことがある。
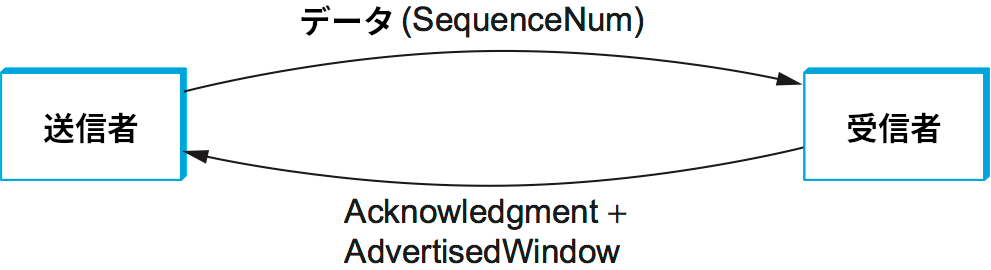
Acknowledgement, SequenceNum, AdvertisedWindow の三つのフィールドは TCP のスライディングウィンドウプロトコルに関連する。TCP はバイト指向プロトコルなので、データの各バイト1はシーケンス番号を持つ。SequenceNum フィールドはこのセグメントで伝達されるデータの最初のバイトに対するシーケンス番号を表す。Acknowledgement フィールドと AdvertisedWindow フィールドは逆方向に流れるデータフローに関する情報を伝達する。議論を簡単にするため、ここではデータフローを両方向に流せる事実は無視して、SequenceNum とデータが一方向に伝達され、その反対方向に Acknowledgement と AdvertisedWindow が伝達される図 129 のような状況を考えることにする。この三つのフィールドは本章の後半でさらに詳しく解説される。
6 ビットの Flags フィールドは制御情報を伝達するために使われる。Flags フィールドには SYN, FIN, RST, PSH, URG, ACK などの値を設定できる。SYN フラグと FIN フラグはそれぞれ TCP 接続の確立と終了で使われる (詳細は後述)。ACK フラグは Acknowledgement フィールドが正当な値を持つときに設定され、受信側に Acknowledgement フィールドを確認するよう伝える。URG フラグはこのセグメントが緊急のデータを含むことを示す。URG フラグが設定されるとき、UrgPtr フィールドはこのセグメントに含まれる緊急でないデータの開始位置を表す。緊急データはセグメント本体の先頭部分から始まり、UrgPtr バイトの長さを持つ。PSH フラグは送信側がプッシュ操作を開始したことを意味する。プッシュ操作を使うと、パケットを受信するプロセスにその事実が伝わる。RST フラグは受信側が混乱した ── 例えば予期していないセグメントを受け取った ── ために接続をリセットしたいと思っていることを表す。
Checksum フィールドは UDP と全く同じように使われる ── TCP ヘッダー、TCP データ、疑似ヘッダーを使って計算される。疑似ヘッダーは送信元 IP アドレス、宛先 IP アドレス、IP ヘッダーの長さからなる。チェックサムは IPv4 と IPv6 の両方で必須である。また、TCP ヘッダーの長さは固定されていない (必須フィールドの後にオプションを付けられる) ので、32 ビットのワードを一単位とした長さが HdrLen フィールドによって与えられる。このフィールドはパケットの先頭からデータの先頭までのオフセットを表すので、Offset フィールドとも呼ばれる。
5.2.3 TCP 接続の確立と終了
TCP 接続はクライアントがサーバーに向かって接続の能動的オープンを行うことで開始される。サーバーが受動的オープンを行っていると仮定すれば、二つのホストは接続を確立するためのメッセージ交換を開始する (第 1 章でソケット API を解説したときと同じように、接続を確立したいと思っている方が能動的オープンを行い、接続を受け入れたいと思っている方が受動的オープンを行う2)。この接続確立フェーズが終了して初めて、二つのホストはデータの送受信を行えるようになる。同様に、データの送信が終わったホストは自分から相手に向かう接続をクローズし、接続終了メッセージのやり取りを行う。接続のセットアップは非対称的 (能動的オープンをする側と受動的オープンをする側が存在する) のに対して、接続の終了は対称的となる (二つのホストは独立して接続をクローズできる) 点に注意してほしい。このため、ある方向の接続はクローズされデータを送れなくても、逆方向の接続はオープンしたままでデータを送れる状況が発生する。
スリーウェイハンドシェイク
TCP が接続の確立と終了で使うアルゴリズムはスリーウェイハンドシェイク (three-way handshake) と呼ばれる。まず基本的なアルゴリズムを説明し、それから TCP でどのように使われるかを説明する。図 130 のタイムラインに示すように、スリーウェイハンドシェイクではクライアントとサーバーの間で三つのメッセージが交換される。
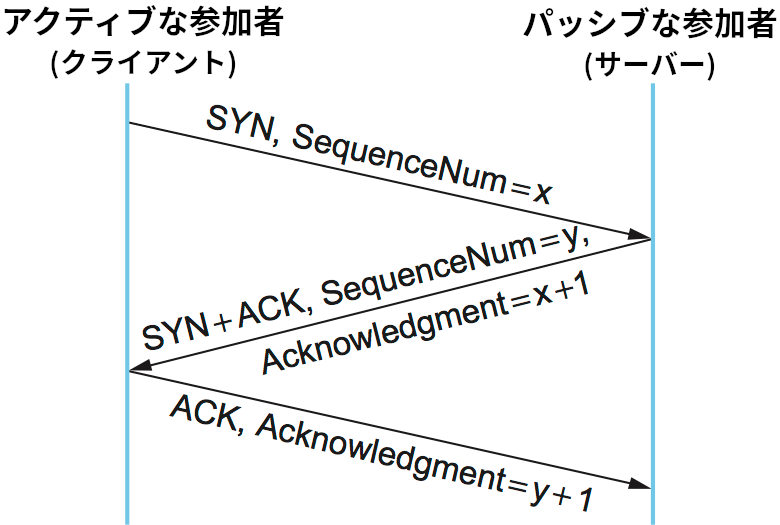
この三つのメッセージを通して両者が何らかのパラメータに合意するのが基本的なアイデアとなる。TCP 接続のオープンでは両者が利用するシーケンス番号の初期値に関して合意が形成されるものの、一般には両ホストが知っておきたい任意の情報となる。まず、クライアント (能動的な参加者) は利用する予定のシーケンス番号の初期値を含んだセグメント (Flags = SYN, SequenceNum = x) をサーバーに送信する。続いてサーバーはクライアントのシーケンス番号に対する確認応答 (Flags = ACK, Ack = x + 1) と自身が利用する予定のシーケンス番号の初期値の伝達 (Flags = SYN, SequenceNum = y) を兼ねる二つ目のメッセージをクライアントに送信する。つまり、このメッセージでは Flags フィールドの SYN ビットと ACK ビットが両方設定される。最後に、クライアントはサーバーのシーケンス番号に対する確認応答 (Flags = ACK, Ack = y + 1) を伝達する三つ目のメッセージをサーバーに送信する。両ホストが相手から知らされたシーケンス番号より 1 大きい数に対する確認応答を送信するのは、Acknowledgement フィールドが「次に受け取ると期待しているシーケンス番号」を表すためである (間接的にそれより小さい全ての番号に対する確認応答となる)。このタイムラインには示されていないものの、最初の二つのセグメントにはタイマーが設定され、一定時間が経過しても返答が返ってこなければメッセージが再送される。
クライアントとサーバーがシーケンス番号を接続のセットアップ時に交換しなければならない理由を疑問に思うかもしれない。両者が「ウェルノウン」なシーケンス番号 (例えば 0) から始めるようにすれば初期値を知らせる処理は必要ないように思える。実は、TCP の仕様がシーケンス番号の初期値をランダムに選択することをクライアントとサーバーの両方に要求している。この理由は、同じ接続の異なる具象化が同じシーケンス番号をすぐに再利用する状況を起こりにくくするためである。この状況が発生すると、接続の過去の具象化に対して送られたセグメントが現在の具象化と干渉する可能性が生まれる。
状態遷移図
TCP は非常に複雑なので、その仕様には状態遷移図が含まれている。その写しを図 131 に示す。この図には接続のオープンに関係する状態 (ESTABLISHED より上) とクローズに関係する状態 (ESTABLISHED より下) だけが示されている。接続がオープンの間に起こること ── つまり、スライディングウィンドウアルゴリズムの動作 ── は全て ESTABLISHED 状態の中に隠されている。
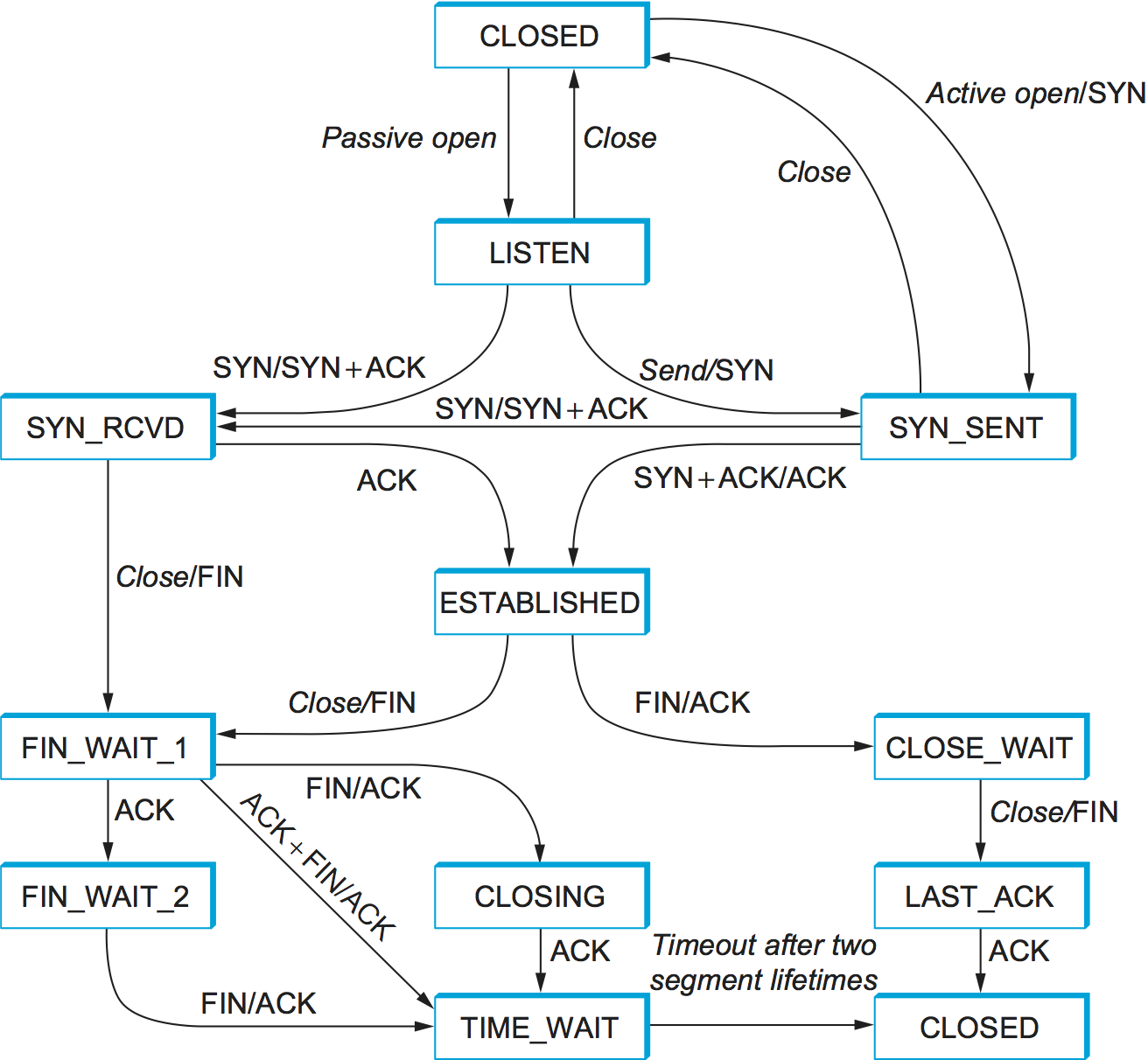
TCP の状態遷移図を理解するのは難しくない。それぞれの四角が TCP 接続が取りうる状態を表している。全ての接続は CLOSED 状態から始まり、接続のセットアップが進行すると矢印に沿って接続の状態が変化していく。矢印には イベント/アクション のラベルが付いており、例えば LISTEN 状態にある接続に対して SYN セグメント (Flags フィールドに SYN フラグが設定されたセグメント) の受信というイベントがおきたら、その接続は SYN_RCVD 状態に遷移し、ACK+SYN セグメントを返信するというアクションを行う。
状態遷移を起こすイベントには二つの種類があることに注意してほしい:
- セグメントがピアに届く (
LISTENからSYN_RCVDに向かう矢印など) - ローカルのアプリケーションプロセスが TCP の操作を行う (
CLOSEDからSYN_SENTに向かう矢印など)
言い換えると、図 131 に示した TCP の状態遷移図は事実上ピア同士のインターフェースおよびサービスのインターフェースの意味論を定義する。これら二つのインターフェースの構文は、それぞれ図 128 に示したセグメントフォーマットおよびソケット API などの API によって与えられる。
では、図 131 を使って典型的な遷移をなぞってみよう。クライアントとサーバーでそれぞれ異なる状態遷移が起きることを念頭に置いてほしい。接続をオープンするとき、最初にサーバーが受動的オープンの操作を行う。この操作によってサーバーは LISTEN 状態に遷移する。その後クライアントが能動的オープンの操作を行い、SYN セグメントをサーバーに送信して SYN_SENT 状態に遷移する。SYN セグメントを受け取ったサーバーは SYN+ACK セグメントを返信して SYN_RCVD 状態に遷移する。このセグメントを受け取ったクライアントはサーバーに ACK セグメントを返信して ESTABLISHED 状態に遷移する。この ACK セグメントを受け取って初めてサーバーも ESTABLISHED 状態に遷移する。こうしてスリーウェイハンドシェイクが完了する。
接続の確立に関連する遷移図の上半分に関して言及したい点が三つある。第一に、もしクライアントがサーバーに送る ACK セグメント (スリーウェイハンドシェイクにおける三つ目のメッセージ) が失われたとしても、接続は正しく動作する。その場合でもクライアントは既に ESTABLISHED 状態に遷移しており、ローカルのアプリケーションプロセスはデータの送信を開始できるためである。クライアントから送信される各データセグメントは ACK フラグを持った Flags フィールドと適切な Acknowledgement フィールドを持つので、サーバーは最初のデータを受け取ったときに ESTABLISHED 状態に遷移する。実はこの点は TCP で重要となる ── 全てのセグメントは送信側が次に受信すると期待するシーケンス番号を報告し、以前のセグメントが同じ情報を伝えているからといって省略することはない。
第二に、LISTEN 状態にあるホストでローカルプロセスが TCP の「送信」操作を行った場合に発生する奇妙な遷移が存在する。つまり、自分が接続を確立したいと思っているホストが判明したなら、向こうからの能動的オープンを待つのを止めてこちらから能動的オープンを送って接続を確立して構わない。著者らの知る限り、これはアプリケーションプロセスから利用されたことがない TCP の機能である。
最後に、この図には示されていない矢印が存在する。具体的には、セグメントの送信が関連する状態のほとんどはタイムアウトを設定し、期待される応答が返ってこなければ再送を行う。この再送は状態遷移図に示されていない。もし再送が何度か失敗したなら、その接続は諦めて CLOSED 状態に戻る。
続いて接続の終了プロセスに話題を移そう。意識しておくべき重要な事実として、接続の両端のホストで実行されるアプリケーションプロセスはそれぞれが独立に自身から相手に向かう接続をクローズしなければならない。もし片方のホストだけが接続をクローズしたなら、そのホストはデータを送れなくなるものの、依然として反対側のホストからのデータは受信できる。このため「クローズ」の操作を両側のホストが同時に行う場合と別々に行う場合の両方を考慮する必要があり、状態遷移図は複雑になる。具体的には、接続が ESTABLISHED 状態から CLOSED 状態へ遷移するルートには次の三つがある:
-
「こちら側」からクローズする:
ESTABLISHED→FIN_WAIT_1→FIN_WAIT_2→TIME_WAIT→CLOSED -
「あちら側」からクローズする:
ESTABLISHED→CLOSE_WAIT→LAST_ACK→CLOSED -
両側が同時にクローズする:
ESTABLISHED→FIN_WAIT_1→CLOSING→TIME_WAIT→CLOSED
実はこれらとは異なる四つ目の CLOSED への遷移ルートが存在する。このルートは FIN_WAIT_1 から TIME_WAIT に向かう矢印をたどる。この四つ目の可能性がどのような状況が組み合わさると発生するかを考えるのは読者への練習問題とする。
もう一つ重要な点として、TIME_WAIT 状態にある接続はインターネットにおける IP データグラムの寿命 (つまり 120 秒) の二倍が経過するまで CLOSED 状態に遷移できないことがある。こうなっている理由は、接続の反対側から送られてきた FIN セグメントに対する ACK セグメントをこちらから送信したとしても、その ACK セグメントが正しく届くかどうかは分からないためである。この ACK セグメントが正しく届かないと反対側のホストは FIN セグメントを再送し、この二つ目の FIN セグメントがネットワークの中で遅延して届くかもしれない。もし接続が直接 CLOSED 状態に遷移できてしまうと、別のアプリケーションプロセスの組が同じ接続 (同じポート番号の組) をオープンした場合に一つ前の具象化に属する FIN セグメントが遅延して届き、関係ない現在の具象化で接続の終了が開始されてしまう可能性が生じる。
5.2.4 スライディングウィンドウ再考
TCP で使われるスライディングウィンドウアルゴリズムの変種を議論する準備がこれで整った。このアルゴリズムには複数の役割がある:
- データが確実に転送されることを保証する。
- データが順序を保って転送されることを保証する。
- 送信側と受信側の間でフロー制御を強制する。
一つ目と二つ目の機能に関しては TCP のスライディングウィンドウアルゴリズムはリンクレベルのものと変わらない。両者が異なるのは、TCP のアルゴリズムにフロー制御の機能が含まれている点である。具体的には、固定サイズのスライディングウィンドウを使うのではなく、受信側がウィンドウサイズを送信側に広報 (advertise) する。この広報は TCP ヘッダーの AdvertisedWindow フィールドを利用して行われる。ウィンドウサイズの広報を受け取った送信側は確認応答を得ていないデータを AdvertisedWindow バイトより多く持つことを禁止される。受信側は受信データをバッファするために接続に割り当てられたメモリの量から適切な AdvertisedWindow の値を選択する。この仕組みは送信側が受信側のバッファを満杯にしないようにするために存在する。この話題は後で詳しく議論する。
順序を保った確実な転送
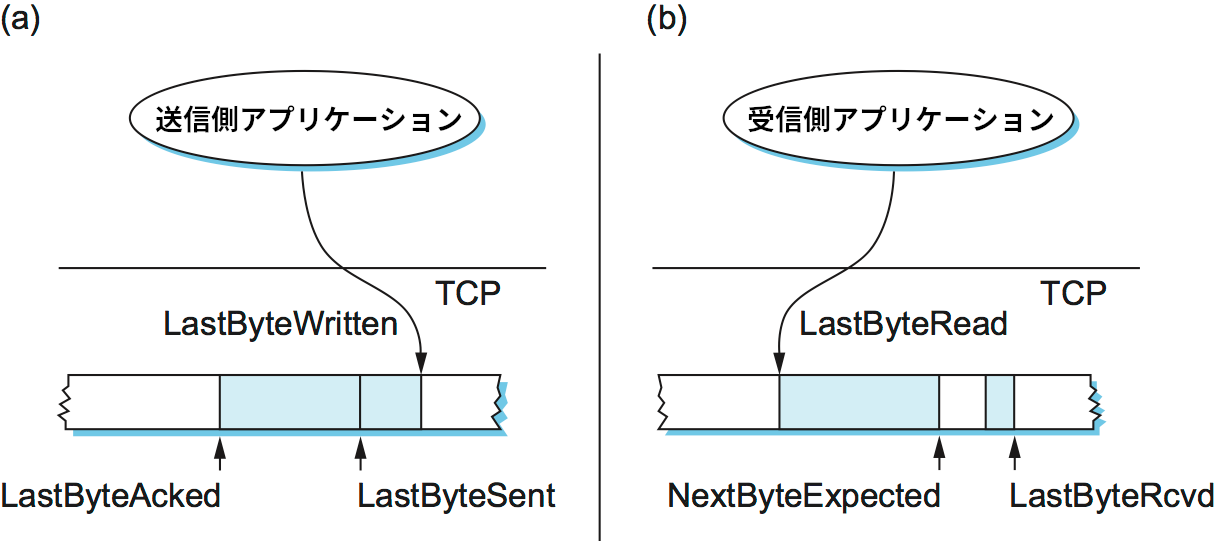
順序を保った確実な転送を行う上で TCP の送信側と受信側がどのように対話するかを理解するために、図 132 に示す状況を考えよう。送信側の TCP は送信バッファを管理し、そこには送信されたものの確認応答が届いていないデータ、およびアプリケーションによって書き込まれたものの送信されていないデータが格納される。受信側の TCP も受信バッファを管理し、そこには順序を保たずに届いたデータ、および順序を保って届いたデータ (穴の空いていないバイトストリーム) であってアプリケーションプロセスがまだ読んでいないものが格納される。
以降の議論を簡単にするために、二つのバッファとシーケンス番号が有限であり、いずれラップアラウンドが起こる事実を最初は無視する。さらに、データの特定のバイトが格納されたバッファの箇所を指すポインタとそのバイトに対するシーケンス番号を同一視する。
最初に送信側を見よう。送信バッファに関して三つのポインタが管理される:
LastByteAcked: 確認応答を受け取った最も後ろのバイトLastByteSent: 送信した最も後ろのバイトLastByteWritten: アプリケーションプロセスによって書き込まれた最も後ろのバイト
まず、受信側が未送信のバイトに対して確認応答することはないので、明らかに次の関係が成り立つ:
LastByteAcked <= LastByteSent
また、TCP はアプリケーションプロセスによって書き込まれていないバイトを送信できないので、次の関係も成り立つ:
LastByteSent <= LastByteWritten
LastByteAcked より左にあるバイトは確認応答が済んでいるので、送信バッファに保存する必要がないことに注意してほしい。さらに、LastByteWritten より右にあるバイトも (意味のあるデータを含んでいないので) 送信バッファに保存する必要がない。
同様に、受信側でも受信バッファに関して三つのポインタが管理される:
LastByteRead: アプリケーションプロセスによって読み込まれた最も後ろのバイトNextByteExpected: 次に受信すると期待しているバイトLastByteRcvd: 受信した最も後ろのバイト
しかし送信バッファの場合と異なり、これらの値に関して成り立つ不等式は少し複雑になる。下位プロトコルでデータの転送が順序を保たずに行われるためである。まず、次の不等式が成り立つ:
LastByteRead < NextByteExpected
この不等式が成り立つのは、アプリケーションプロセスがバイトを読み込むとき、そのバイトとそのバイトより前の全てのバイトが必ず受信されているためである。NextByteExpected はこの条件が成り立つ最も後ろのバイトの次のバイトを指す。続いて、次の不等式が成り立つ:
NextByteExpected <= LastByteRcvd + 1
この不等式が成り立つのは、データが順序を保って到着したとき NextByteExpected は LastByteRcvd の一つ後ろを指し、順序を保たずに到着したとき NextByteExpected は先頭の隙間が始まるバイトを指すためである。LastByteRead より左のバイトはローカルのアプリケーションプロセスによって既に読み込まれているので受信バッファに保存する必要がなく、LastByteRcvd より右のバイトはまだ届いていないので受信バッファに格納する必要がないことに注意してほしい。
フロー制御
以上の議論は標準的なスライディングウィンドウアルゴリズムと大きくは変わらない: TCP のスライディングウィンドウアルゴリズムが持つ唯一の本当の違いは、アプリケーションプロセスがローカルのバッファに対して書き込み (送信側) や読み込み (受信側) を行う事実に注目すると姿を現す。ここまでの議論は下流に送信したデータが送信バッファから削除され、上流のノードから到着したデータが受信バッファに書き込まれる事実を無視していた。
二つのアルゴリズムが大きく異なる点をこれから説明するので、読み進める前にここまでに説明したことの理解を確認してほしい。これからは、送信バッファのサイズ MaxSendBuffer と受信バッファのサイズ MaxRcvBuffer が有限であるというこれまで無視していた事実を考慮した議論を行う。ただしバッファの実装詳細は無視する: 言い換えれば、バッファされるバイト数だけに注目し、そのバイトが実際にどのように格納されるかは考えないものとする。
スライディングウィンドウアルゴリズムにおいて、ウィンドウのサイズは受信側からの確認応答を待たずに送信側が送信できるデータの量を設定したことを思い出してほしい。そのため、受信側は自身がバッファできるデータ量より小さいウィンドウサイズを送信側に広報することでデータの送信速度を調整する。受信側の TCP はバッファのオーバーフローを避けるために次の不等式を成り立たせる必要がある:
LastByteRcvd - LastByteRead <= MaxRcvBuffer
受信側が広報するウィンドウサイズは次のように表せる:
AdvertisedWindow = MaxRcvBuffer - ((NextByteExpected - 1) - LastByteRead)
AdvertisedWindow の値は受信バッファの空き容量を表す。データが到着すると、受信側はそのデータより前のデータが全て受信済みであれば確認応答を行う。このとき LastByteRcvd は右に進み (1 だけ大きくなり)、広報されるウィンドウサイズが小さくなる可能性が生じる。ウィンドウサイズが小さくなるかどうかはローカルのアプリケーションプロセスがデータを消費する速度に依存する。もしローカルプロセスがデータの到着と同じ速度でデータの読み込みを行う (LastByteRead が LastByteRcvd と同じ速度で大きくなる) なら、広報されるウィンドウサイズはそのまま (AdvertisedWindow = MaxRcvBuffer) となる。一方で、もしローカルプロセスによるデータの読み込みがデータの受信よりも遅い (例えば読み込んだデータの各バイトに長い時間のかかる操作をしている) なら、広報されるウィンドウサイズはデータを受信するごとに小さくなり、いずれ 0 になる。
送信側の TCP は受信側から広報されたウィンドウサイズを守らなければならない。これは任意の時点で次の不等式を成り立たせることを意味する:
LastByteSent - LastByteAcked <= AdvertisedWindow
言い換えれば、送信側が送信できるデータ量を表す実効ウィンドウサイズ EffectiveWindow は次のように計算できる:
EffectiveWindow = AdvertisedWindow - (LastByteSent - LastByteAcked)
明らかに、EffectiveWindow が 0 より大きくなければ送信側はデータを送信できない。なお、 x バイトの確認応答を含んだセグメントが到着して LastByteAcked が x だけ大きくなったとしても、受信側のローカルプロセスがデータを読み込んでいないために広報されるウィンドウサイズも前回より x だけ小さくなる状況があり得る。その場合、送信側はバッファの空間を解放できるものの、データを追加で送信することはできない。
こういった処理に加えて、送信側はローカルのアプリケーションプロセスが送信バッファをオーバーフローさせないようにする必要がある。つまり次の不等式が成り立たなければならない:
LastByteWritten - LastByteAcked <= MaxSendBuffer
送信を行うプロセスが y バイトを TCP に書き込もうとしたとしても、もし
(LastByteWritten - LastByteAcked) + y > MaxSendBuffer
が成り立つなら、TCP はそのプロセスをブロックしてデータの生成を抑制する。
これで低速な受信プロセスがどのように高速な送信プロセスを減速させるかが理解できるようになった。まず、受信側の受信バッファが満杯になって広報されるウィンドウサイズが 0 になる。これは送信側が以前に送信したデータに対する肯定的な確認応答を受け取っていたとしても全くデータを送信できないことを意味する。データを送信できないことで送信バッファが埋まっていき、最終的に TCP は送信プロセスをブロックするようになる。受信プロセスがデータの読み込みを再開すると、受信側から 0 より大きいウィンドウサイズが広報され、送信側の TCP は送信バッファからデータを送信できるようになる。このデータに対する確認応答を受け取ると LastByteAcked が大きくなり、その確認応答に対応する送信バッファの空間が解放され、送信プロセスはブロックを解かれて送信バッファにデータを書き込めるようになる。
最後に一つ解決すべき問題がある ── ウィンドウサイズが一度 0 になった後、送信側はウィンドウサイズが 0 でなくなったことをどのように知るのだろうか? 上述したように、TCP の受信側は必ず受信したデータセグメントに対する応答としてセグメントを送信し、この応答には Acknowledge フィールドと AdvertisedWindow フィールドに対する最新の値が (前回に送ったセグメントから変化がない場合でも) 含まれている。もし受信側が 0 のウィンドウサイズを広報すると、送信側からはデータを一切送れなくなる。これは将来ウィンドウサイズが 0 でなくなったときに受信側がそれを広報する方法が存在しないことを意味する。受信側の TCP は自発的に非データセグメントを送ることはできず、受け取ったデータセグメントに対する応答だけが許されている: ウィンドウサイズは受け取ったデータセグメントに対する応答に含ませることでしか広報できない。
この状況を TCP は次のように解決する: 相手が 0 のウィンドウサイズを広報した場合でも、送信側は 1 バイトのデータを持ったセグメントを定期的に送信する。送信側はセグメントに含まれるデータが受け入れられないことを承知で、ウィンドウサイズの最新の広報を含んだ応答を引き起こすためにこのセグメントを送信する。この 1 バイトの調査用セグメントの応答には、いずれ 0 でないウィンドウサイズの広報が含まれるようになる。
この 1 バイトのセグメントはゼロウィンドウプローブ (Zero Window Probe) と呼ばれ、現実のデバイスでは 5 秒から 60 秒に一度の頻度で送信される。ゼロウィンドウプローブに使われる 1 バイトのデータにはウィンドウの外にある実際のデータが使われる (受信側が受理した場合に備えて実際のデータを使う必要がある)。
教訓
送信側が定期的にゼロウィンドウプローブを送る理由は、受信側をできる限り単純にするように TCP が設計されているためである ── 受信側は送信側が送ったセグメントに応答するだけであり、自分から操作を開始することはない。これは、短い呼び名がないために賢い送信者と愚かな受信者の原則 (smart sender/dumb receiver rule) という長い名前で呼ばれる広く知られた (ただし常に適用されるとは限らない) プロトコルの設計原則の例と言える。この原則の例はスライディングウィンドウアルゴリズムにおける NACK の議論でも見た。
ラップアラウンドの対処
本項と次項では SequenceNum フィールドと AdvertisedWindow フィールドのサイズ、およびこれらのサイズが持つ TCP の正しさとパフォーマンスへの影響を考察する。TCP の SequenceNum フィールドの長さは 32 ビット、AdvertisedWindow フィールドの長さは 16 ビットである。\(2^{32} \gg 2 \times 2^{16}\) なので、TCP は「シーケンス番号の個数はウィンドウサイズの 2 倍以上でなければならない」というスライディングウィンドウアルゴリズムの要件を簡単に満足できる。しかし、この要件は二つのフィールドに関して興味深い点ではない。それぞれについて順に見ていく。
シーケンス番号は有限なので、特定の接続で利用されるシーケンス番号がラップアラウンドする可能性がある ── あるバイトがシーケンス番号 \(S\) で送られ、しばらくして異なるバイトが同じシーケンス番号 \(S\) で送られる状況があり得る。パケットは MSL の推奨値の間だけインターネットにとどまるので、少なくとも 120 秒の間はシーケンス番号がラップアラウンドしてはいけない。この間にラップアラウンドが起こるかどうかは、ホストがインターネットにデータを送信する速度 ── シーケンス番号が消費される速度 ── によって決まる (パイプに隙間を作らないようにするとき、シーケンス番号は高速に消費される)。様々なテクノロジの典型的な帯域とシーケンス番号がラップアラウンドするまでにかかる時間の関係を表 22 に示す。
| テクノロジ (帯域) | ラップアラウンドまでの時間 |
|---|---|
| T1 (1.5 Mbps) | 6.4 時間 |
| T3 (45 Mbps) | 13 分 |
| 高速なイーサネット (100 Mbps) | 6 分 |
| OC-3 (155 Mbps) | 4 分 |
| OC-48 (2.5 Gbps) | 14 秒 |
| OC-192 (10 Gbps) | 3 秒 |
| 10 ギガビットイーサネット (10 Gbps) | 3 秒 |
表 22 から分かるように、ある程度の速さのテクノロジまでは 32 ビットのシーケンス番号で問題ない。しかし現在インターネットバックボーンで普通に使われている OC-192 リンクや多くのサーバーで利用される 10 ギガビットイーサネットでは、32 ビットのシーケンス番号を全て使い果たすまでの時間があまりにも短い。幸い、利用可能なシーケンス番号を増加させてラップアラウンドに対処するための TCP の拡張が IETF によって策定されている。この拡張に関しては第 5.2.8 項で扱う。
パイプに隙間を作らない
AdvertisedWindow フィールドは送信側がパイプに隙間を作らないで済むほどに大きくできなければならない。もちろん、受信側がウィンドウサイズを AdvertisedWindow フィールドが許すだけ大きくしない状況もある。今は受信側が AdvertisedWindow フィールドの最大値より大きいバッファを持つ状況を考えている。
この状況では、ネットワーク帯域だけではなく帯域遅延積が AdvertisedWindow フィールドで表せなければならない最大値を決定する ── ウィンドウは帯域遅延積だけのデータを同時に転送できるだけの大きさを持つ必要がある。RTT が 100 ms (アメリカを横断する回線で典型的な値) のとき、様々なネットワークテクノロジにおける帯域遅延積は表 23 のようになる。
| 帯域 | 帯域遅延積 |
|---|---|
| T1 (1.5 Mbps) | 18 KB |
| T3 (45 Mbps) | 549 KB |
| 高速なイーサネット (100 Mbps) | 1.2 MB |
| OC-3 (155 Mbps) | 1.8 MB |
| OC-48 (2.5 Gbps) | 29.6 MB |
| OC-192 (10 Gbps) | 118.4 MB |
| 10 ギガビットイーサネット (10 Gbps) | 118.4 MB |
表 23 からは、TCP の AdvertisedWindow フィールドが SequenceNum フィールドより悪い状況にあることが分かる ── 16 ビットの AdvertisedWindow フィールドは最大でもわずか 64 KB のウィンドウサイズしか広報できないので、アメリカ本土を横断する T3 回線に対してさえ十分でない。先述した TCP の拡張は広報できるウィンドウサイズを事実上増加させる仕組みも提供する。
5.2.5 転送の開始
続いて驚くほど細かい疑問を考える: TCP はセグメントの転送をどのように決断するのだろうか? TCP はやり取りされるデータをバイトストリームとして抽象化する。つまりアプリケーションプロセスはバイトをストリームとして書き込み、セグメントとして送信するだけのバイトが溜まったかどうかの判断は TCP に任せられる。この判断を左右する要因は何だろうか?
フロー制御の可能性を無視するなら ── 接続開始直後のウィンドウサイズが非常に大きい状態がずっと続くと仮定するなら ── TCP はセグメントの転送を開始するための仕組みを三つ持つ。第一に、TCP は MSS (maximum segment size, 最大セグメントサイズ) と呼ばれる変数を管理しており、データを送信するアプリケーションプロセスから MSS バイトが書き込まれるとセグメントの転送を開始する。通常 MSS はローカル IP でフラグメントを起こさずに送信できる最大のセグメントサイズに設定される。つまり、MSS は送信側ホストに直接接続されたネットワークの MTU (maximum transmission unit, 最大転送ユニット) から TCP と IP のヘッダーのサイズを引いた値となる。第二に、データを送信するアプリケーションプロセスが明示的にセグメントの転送を要求したときにも転送は開始される。具体的には、TCP はプッシュ操作をサポートし、アプリケーションプロセスはこの操作を使って未送信バイトのバッファを空にできる。第三に、セグメントの転送を開始するためのタイマーが存在する: タイマーによって転送が開始されるセグメントには可能な限り多くのバッファされているデータが含まれる。ただし後述するように、このタイマーは「タイマー」と聞いて普通に想像されるものと少し異なる。
間抜けなウィンドウ症候群
もちろん、フロー制御を無視することはできない。フロー制御は送信側のスピードを抑制するために存在する。もし送信側の送信バッファに MSS バイト以上の未送信データが溜まっていて、ウィンドウサイズが MSS 以上なら、送信側は完全なセグメントを送信する。では送信バッファにデータはあるにもかかわらずウィンドウが閉まっている (ウィンドウサイズが 0) の場合を考えよう。この状態で ACK が届き、ウィンドウが (例えば MSS の半分だけ) 開いたとする。このとき送信側は半分だけ詰まったセグメントを送信すべきだろうか、それともウィンドウが完全に開くまで待つべきだろうか? オリジナルの TCP 仕様にはこの点に言及しておらず、初期の TCP 実装は特に気にせず半分だけ詰まったセグメントを送信していた。結局ウィンドウがいつ完全に開くかは分からないので、これは理にかなった振る舞いに思える。
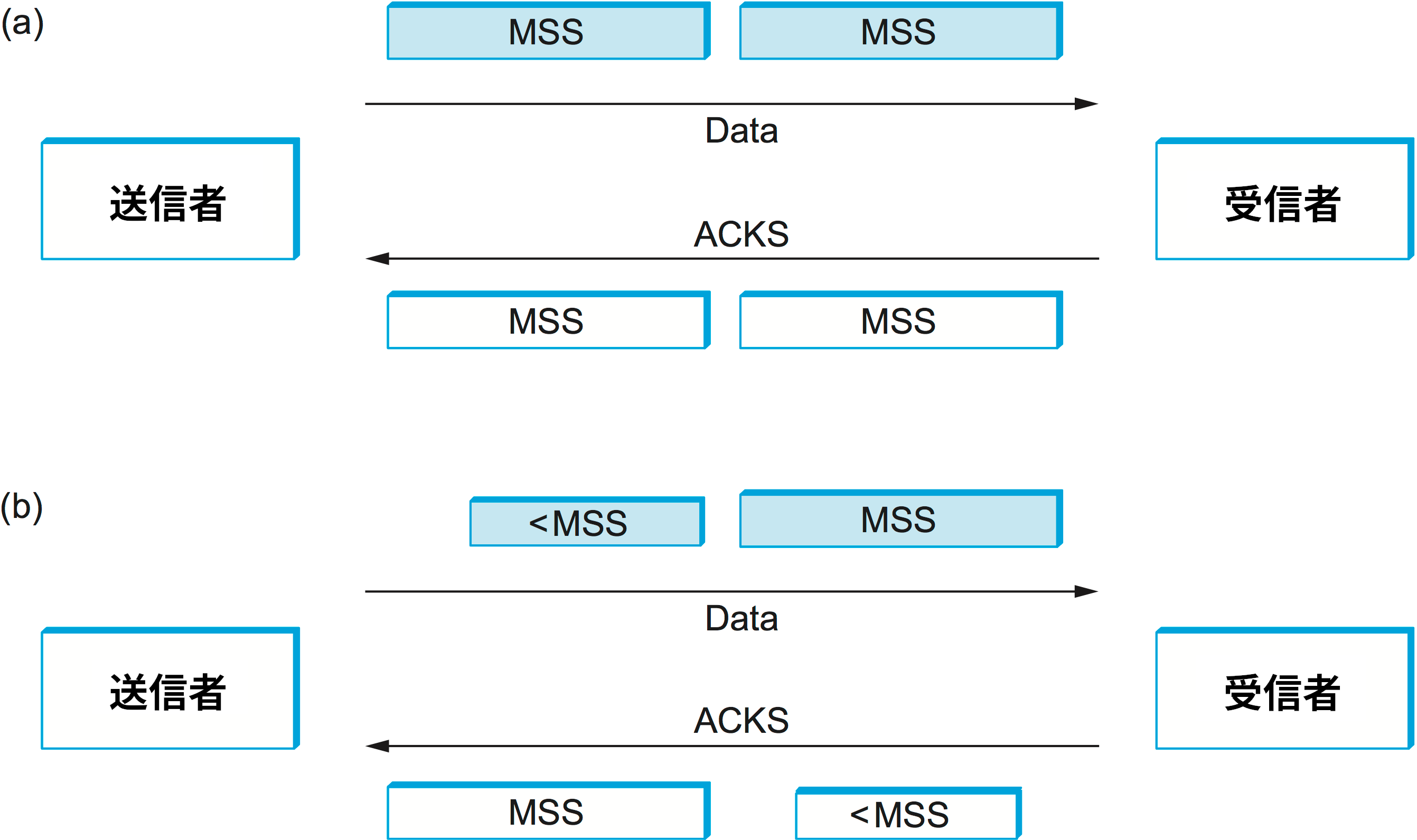
しかし、この「利用可能なウィンドウを積極的に利用する」戦略は間抜けなウィンドウ症候群 (silly window syndrome) と呼ばれる問題を引き起こすことが知られている。この問題の様子を図 133 に示す。TCP 接続をベルトコンベアと考えれば、片方向には中身の詰まった容器 (データセグメント) が流れ、その逆方向には空の容器 (ACK) が流れる。送信側がサイズ MSS のセグメントを送信し、受信側が同じ間隔で ACK を送信するなら、何も問題はない。しかし受信側がウィンドウを狭めると、送信側はいずれ MSS だけのデータを送れなくなる。この状況で送信側が満杯になっていない容器 (サイズが MSS より小さいデータセグメント) を送ると、受信側は狭い範囲を ACK するので、システムに追加された満杯でない容器はいつまでも残り続ける。つまり、容器に少量の中身を入れる処理とそこから少量の中身を取り出す処理がベルトコンベアの両端で繰り返され、いくつかの容器の中身をまとめて一つの容器に移し替える処理は決して起こらない。このシナリオは初期の TCP 実装が非常に小さいセグメントでネットワークを埋めてしまうことがよくあったために発見された。
間抜けなウィンドウ症候群の問題が起こるのは送信側が小さなセグメントを送ったとき、および受信側のウィンドウが狭くなったときであることに注意してほしい。これらの条件がどちらも満たされないなら、満杯でない容器はベルトコンベア上に現れない。小さなセグメントの送信を禁止することはできない: 例えば、アプリケーションプロセスは 1 バイトを送信した後にプッシュ操作を行うかもしれない。しかし、小さい容器が現れる (小さいウィンドウが開く) のを受信側から防ぐことはできる。そのため「ウィンドウサイズ 0 を広報したら、MSS だけの空間が確保されるのを待ってから 0 より大きいウィンドウサイズを広報しなければならない」という規則が存在する。
ストリームに満杯でない容器が混入する可能性は排除できないので、そういった容器をまとめる仕組みが必要になる。受信側は ACK を遅らせることで ── 小さな範囲に対する ACK をいくつかまとめて一つの ACK として送ることで ── これを行える。しかし他のセグメントが届くかアプリケーションがデータをさらに読み込む (そしてウィンドウが開く) かするまでの時間は受信側からは分からないので、これは部分的な解決策でしかない。最終的な解決は送信側で行わなければならず、私たちは最初に考えた問題に戻ってくる: TCP の送信側はセグメントの転送をどのように決断するのだろうか?
Nagle のアルゴリズム
TCP の送信側を考えよう。転送すべきデータがあり、ウィンドウサイズが MSS より小さい場合、そのデータを転送する前に一定の時間だけ待てばセグメントの無駄が減る。しかしどれだけ待てばいいのだろうか? 長く待ちすぎると、Telnet のような対話的アプリケーションのサービス品質が低下してしまう。かといって待つ時間が短すぎると、小さなセグメントが大量に送られることになって間抜けなウィンドウ症候群が生じるかもしれない。答えは「タイマーを導入し、タイマーが時間切れとなったときに転送を開始する」となる。
クロックベースのタイマー (例えば 100 ms ごとに発火するタイマー) を使うこともできるものの、Nagle は自己クロック (self-clocking) を利用する美しい解決法を提案した。そのアイデアは「送信側が以前に送ったデータに対する ACK をいずれ受け取る。この ACK をタイマーの発火とみなし、次のデータ転送を開始する」というものである。Nagle のアルゴリズム (Nagle's algorithm) は転送のタイミングを決定する単純で統一的なルールを提供する:
when アプリケーションが送信すべきデータを生成したとき
if (利用可能なデータ >= MSS) and (ウィンドウサイズ >= MSS)
完全なセグメントを送信する
else
if ACK されてない送信済みデータが存在する
ACK が届くまでデータをバッファする
else
データをすぐに全て送信する
end
end
end
言葉で説明すれば、ウィンドウが十分に広いなら完全なセグメントをいつでも送信して構わない。さらに ACK を待っているセグメントが存在しないときは少量のデータを送信して構わない。しかし ACK を待っている (転送中の) セグメントが存在するときは、送信側は次の ACK が届くまで次のセグメントの送信を遅延させる。そのため、Telnet のような一度に 1 バイトの書き込みを継続的に行う対話的アプリケーションは RTT ごとに一つのセグメントのペースでデータを送信することになる。一つのセグメントにデータが 1 バイトしか含まれない場合もあれば、RTT の間にユーザーがたくさんのキーを打ち込んだ場合などセグメントに複数のバイトが含まれる場合もある。
Nagle のアルゴリズムを使うと、最大で RTT だけの遅延が TCP 接続に対する全ての書き込みで発生する可能性が生じる。この遅延が受け入れられない一部のアプリケーションのために、ソケットインターフェースは Nagle のアルゴリズムを無効化するための TCP_NODELAY オプションを提供している。このオプションを有効にすると転送が可能な限り早く行われる。
5.2.6 適応型再送
TCP はデータの確実な転送を保証するので、一定の時間が経過しても ACK が届かない場合はセグメントの再送を行う。このタイムアウトは TCP 接続が結ぶ二つのホスト間の RTT の関数として設定される。残念ながら、インターネット上のホスト間の RTT はホストの組ごとに大きく異なり、さらに同じ二つのホスト間の RTT も時間の経過とともに変化する。そのため、適切なタイムアウトの値を選択する問題は簡単に解決できない。この問題を解決するために、TCP は適応型再送 (adaptive retransmission) の仕組みを持つ。本項では適応型再送の仕組み、そしてインターネットコミュニティが TCP の経験を積む中でその仕組みをどのように進化させてきたかを説明する。
オリジナルのアルゴリズム
二つのホスト間のタイムアウトを計算する単純なアルゴリズムから始めよう。これはオリジナルの TCP 仕様で説明されたアルゴリズムであり、そのため TCP の用語で説明されているものの、同じアルゴリズムは任意のエンドツーエンドプロトコルで利用できる。
このアルゴリズムのアイデアは「RTT の移動平均を取り、その値の関数としてタイムアウトを計算する」というものである。具体的な処理としては、TCP はデータセグメントを送信するたびに時刻を記録する。そのセグメントに対する ACK が到着したとき、TCP は時刻を再度確認し、RTT のサンプル値 SampleRTT を二つの時刻の差として計算する。その後 TCP は RTT の推定値 EstimatedRTT を前回の推定値と新しいサンプルの加重平均として計算する:
EstimatedRTT = alpha x EstimatedRTT + (1 - alpha) x SampleRTT
パラメータ alpha は EstimatedRTT が滑らかになるように選択する。alpha を小さくすると RTT の変動に素早く適応できるものの、一時的な変動に影響を受けすぎる可能性が生じる。一方で alpha を大きくすると値は安定するものの、本当の変動に素早く適応できなくなる。オリジナルの TCP 仕様は alpha を 0.8 から 0.9 に設定し、タイムアウトを EstimatedRTT を使って次のように保守的に計算することを推奨している:
TimeOut = 2 x EstimatedRTT
Karn/Partridge のアルゴリズム
この単純なアルゴリズムがインターネットで使われて数年が経過すると、明らかな欠点が浮かび上がった。問題は ACK によって通知されるのが正確にはデータの転送ではない点にある: 実際に ACK が通知するのはデータの受け取りである。つまり、セグメントが再送された後に ACK が届いた場合、その ACK が通知するのは一度目の転送と二度目の転送のどちらかが分からず、RTT のサンプル値を正確に計算できない。正確な SampleRTT を計算するには、セグメントがどの転送に対応付くかを知らなければならない。図 134 に示すように、再送に対する ACK を最初の転送に対する ACK と誤解して SampleRTT を計算すると実際より大きな値が計算され、最初の転送に対する ACK を再送に対する ACK と誤解して SampleRTT を計算すると実際より小さい値が計算される。
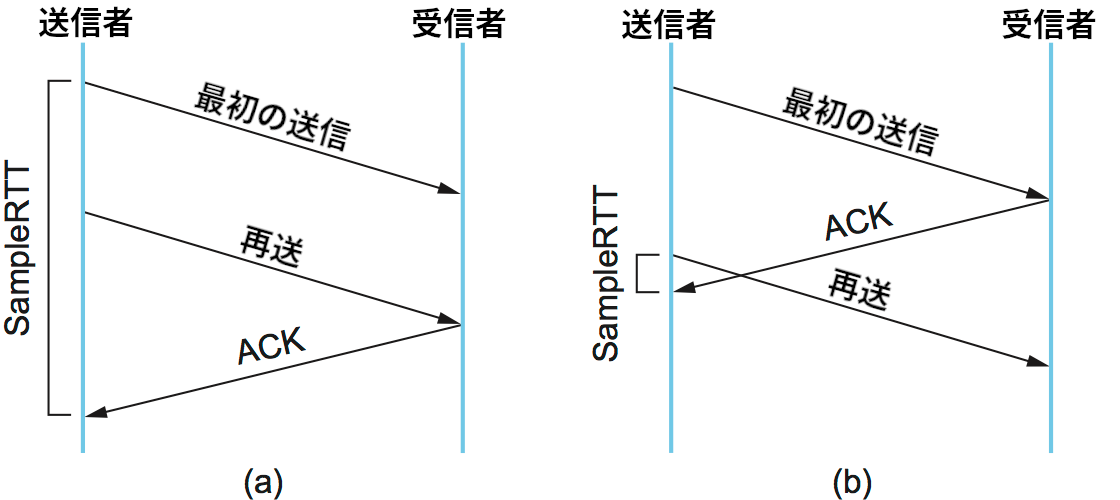
1987 年に提案された解決策は驚くほど簡単だった: TCP がセグメントの再送を行ったら、そのセグメントからは RTT のサンプル値を取得しなければいい。SampeleRTT の計測は一度の転送で ACK を受け取ったセグメントに対してだけ行われる。この解決策は考案者の名前を取って Karn/Partridge のアルゴリズム (Karn/Partridge algorithm) と呼ばれる。彼らは TCP のタイムアウトに関する変更も提案した: 再送が行ったとき次のタイムアウトは EstimatedRTT から計算した値ではなく前回のタイムアウトの二倍に設定すべきだとした。つまり Karn と Partridge はイーサネットと同様の指数バックオフを TCP で使うべきだと提案した。指数バックオフに対するモチベーションは単純だった: セグメントの喪失は輻輳によって起こる可能性が最も高いので、TCP の送信側はタイムアウトの後に積極的になり過ぎない方が望ましく、接続がタイムアウトするたびにさらに注意深くなる必要がある。次章では、この考え方が指数バックオフより格段に高度な仕組みでも利用されることを見る。
Jacobson/Karels のアルゴリズム
Karn/Partridge アルゴリズムはインターネットが高いレベルでのネットワーク輻輳に苦しんでいた時代に導入された。そのアプローチは輻輳を起こす要因の一部を修正するために設計されていた。しかし、このアルゴリズムによる改善はたしかにあったものの、輻輳が無くなることはなかった。翌年 (1988 年)、Jacobson と Karels という二人の研究者が輻輳に対処するためのさらに大規模な変更を提案した。彼らの提案について詳しくは次章で解説する。ここでは、セグメントのタイムアウトと再送を行うタイミングの判断に関連する部分だけを見ていく。
余談になるが、ここまで読んだ読者はタイムアウトの仕組みが輻輳に関係していることが理解できたと思う ── タイムアウトが早すぎれば、セグメントが不必要に再送され、ネットワークに無駄な負荷がかかる可能性がある。タイムアウトが輻輳を意味するとみなされ、輻輳制御の仕組みが起動する場合があることも正確なタイムアウトの値が必要なもう一つの理由として挙げられる。なお、Jacobson と Karels が提案したタイムアウトの計算方式は TCP に特有な部分を持たない。そのため任意のエンドツーエンドプロトコルで利用できる。
オリジナルの計算方式の主要な問題は RTT のサンプル値が持つ変動を考えに入れないことだった。直感的に言えば、もしサンプル値の変動が小さいなら EstimateRTT は非常に信頼できるので、タイムアウトを計算するときに 2 を乗じる必要はない。逆にサンプル値の変動が大きいなら、タイムアウトの値を EstimatedRTT と強く関連付けるべきでないことが示唆される。
Jacobson と Karels による新しいアプローチにおいて、送信側は SampleRTT をこれまでと同様に計測し、次の計算を行う:
Difference = SampleRTT - EstimatedRTT
EstimatedRTT = EstimatedRTT + (delta x Difference)
Deviation = Deviation + delta (|Difference| - Deviation)
ここで delta は 0 から 1 の値を取る定数である。この計算では、RTT の推定値 EstimatedRTT とその標準偏差 Deviation という二つの値が計算される。
その後タイムアウトの値は EstimatedRTT と Deviation から次のように計算される:
TimeOut = mu x EstimatedRTT + phi x Deviation
ここで通常 mu は 1 に、phi は 4 に設定される。これらの値は経験に基づいて決定されたものである。この計算式を使うと、標準偏差 Deviation が小さいと TimeOut は EstimatedRTT に近くなり、大きいと Deviation の項が TimeOut の中で支配的になる。
実装
TCP のタイムアウトを実装するときに注意が必要な点が二つある。第一に、EstimatedRTT と Deviation の計算は浮動小数点演算を使わずに行える。具体的には、delta を \(2^{-n}\) として計算全体に \(2^{n}\) を乗じると、乗算と除算をシフトで置き換えられるので整数演算だけで二つの値を計算できる。こうするとパフォーマンスが向上する。\(n=3\) (つまり delta = 1/8) としたときの計算を行うコードを次に示す。EstimatedRTT と Deviation はスケールされた値であるのに対して、計算の起点となる SampleRTT と計算結果の TimeOut はスケールされていない実際の値であることに注意してほしい。このコードの理解が難しいと感じたら、適当な値を代入して計算してみて、上で示した数式と同じ値が計算されることを確認するとよい。
{
SampleRTT -= (EstimatedRTT >> 3);
EstimatedRTT += SampleRTT;
if (SampleRTT < 0)
SampleRTT = -SampleRTT;
SampleRTT -= (Deviation >> 3);
Deviation += SampleRTT;
TimeOut = (EstimatedRTT >> 3) + (Deviation >> 1);
}
第二に、Jacobson/Karels のアルゴリズムの有用性は現在時刻を取得するクロックの精度に大きな影響を受ける。このアルゴリズムが提案された当時の典型的な Unix 実装ではクロックの精度が 500 ms 程度であり、大陸横断回線の RTT (100 ms から 200 ms 程度) よりずっと長かった。さらに悪いことに、Unix の TCP 実装はこの 500 ms のクロックが進んだときにだけタイムアウトが発生したかどうかを確認し、RTT につき一度しか RTT のサンプルを取得しなかった。この二つの要因が組み合わさると、タイムアウトの感知が発生より大幅に遅れる可能性が生じる。繰り返しになるが、これより正確な RTT の計算を行う仕組みが TCP の拡張には含まれている。
ここまでに議論した再送アルゴリズムはどれも ACK のタイムアウトを利用している。タイムアウトはセグメントがおそらく喪失したことを表す。しかしタイムアウトからは以前に送信されたセグメントが受信側に届いたかどうかに関して何も分からない点に注意してほしい: TCP の ACK は累積的なので、ACK は受信バッファに隙間なく並んでいる最も後ろのセグメント (先頭の隙間の一つ前のセグメント) がどれかを伝える。ネットワークが高速になってウィンドウが大きくなると、先頭の隙間より後ろのセグメントが受信されている状況は頻繁に発生する。もし ACK が先頭の隙間より後ろのセグメントで受信されているものを伝えられるなら、送信側は再送するセグメントをより賢く選択でき、さらに輻輳の状況に関する知識をより多く手にすることで RTT の優れた推定値を計算できる。この仕組みをサポートする TCP の拡張は第 5.2.8 項で説明する。
教訓
タイムアウトの計算に関してもう一つ述べておきたいことがある。タイムアウトの計算は非常にトリッキーな問題であり、この問題だけを論じた RFC (RFC 6298) が存在するほどである。このようにプロトコルを完全に規定するために必要な細かい事項があまりにも多くなり、仕様と実装の差が曖昧になる場合がある事実を頭に入れておいてほしい。これは TCP で何度か発生した状況であり、「実装こそが仕様じゃないか」という意見も出るほどだった。しかし、これは参照実装がオープンソースソフトウェアとして利用可能な限り必ずしも悪いことではない。より広い視点で言うと、ネットワーク産業ではオープンな規格が重要性を失う中でオープンソースソフトウェアの重要性が高まっている。
5.2.7 レコード境界
TCP はバイトストリーム指向のプロトコルなので、送信側が一度に書き込むバイト数と受信側が一度に読み込むバイト数は一致する必要がない。例えば送信側のアプリケーションプロセスが TCP 接続に 8 バイト、2 バイト、20 バイトをこの順に書き込んだとしても、受信側のアプリケーションは 5 バイトを読み込むループを 6 回実行するかもしれない。TCP は 8 番目のバイトと 9 番目のバイトの間、あるいは 10 番目のバイトと 11 番目のバイトの間にメッセージの切れ目を表すレコード境界 (record boundary) を挿入しない。これは送信側が送信したメッセージと同じ長さのメッセージが受信側に届くメッセージ指向のプロトコル (例えば UDP) と対照的な動作である。
TCP はバイトストリーム指向のプロトコルであるものの、送信側がバイトストリームにレコード境界を挿入する機能のための仕組みが二つ存在する。この機能を使うと受信側はバイトの並びをレコードの並びに分割できる (この機能は例えばデータベースアプリケーションで有用となる)。二つの仕組みが TCP に追加された理由は全く異なるものの、現在では同じ用途で使われるようになった。
一つ目の仕組みは緊急データを送信する機能を利用する。この機能は TCP ヘッダーの URG フラグと UrgPtr フィールドを使って実装される。緊急データを送信する機能はアウトオブバンド (out-of-band) のデータを相手のアプリケーションに送るために元々設計された。データが「アウトオブバンド」とは、通常のデータとは異なるフローで相手のアプリケーションに届くことを意味する (例えば現在実行中の操作を取り消すコマンドで使われる)。このアウトオブバンドのデータはセグメント内の UrgPtr フィールドが指すバイトから始まり、ホストに届くと同時に (シーケンス番号が前後することになったとしても) アプリケーションへ届けられる。しかし、時が経つにつれこの機能は使われなくなり、「緊急の」データではなく「特別な」データ (例えばレコード境界) を表すために使われるようになった。この用途が生まれたのは、プッシュ操作と同様に、URG フラグを使うとき受信側の TCP はアプリケーションに緊急データの到着を伝なければならないためである。つまり、緊急データ自身は重要ではない: 送信側のプロセスが受信者に事実上のシグナルを送信できる事実が重要となる。
二つ目の仕組みはプッシュ操作を利用する。元々プッシュ操作は送信側のプロセスが TCP に向かって「バッファされたデータを今すぐに全て相手に送信 (フラッシュ) してくれ」と指示できるようにするために設計された。仕様にはアプリケーションがプッシュ操作を行ったとき TCP は送信側でバッファされたデータを全て送らなければならず、宛先の TCP は受け取ったセグメントに PSH フラグが設定されているときアプリケーションに通知しなければならない (こちらは省略可能) ことが定められている。受信側が後者の処理をサポートするなら (ソケットインターフェースはサポートしない)、プッシュ操作を利用して TCP ストリームをレコードに分割できる。
もちろん、アプリケーションプログラムは TCP の助けを借りることなくレコード境界をストリームに挿入して構わない。例えばレコードの先頭に長さを表すフィールドを加えたり、データストリームにレコード境界を表すマーカーを挿入したりしても問題は無い。
5.2.8 TCP の拡張
本節で四度、下位のネットワークが高速になる中で TCP が直面した問題を解決するための TCP の拡張が策定されていることに言及した。この拡張は TCP への影響が最小限になるように、具体的には TCP ヘッダーの省略可能なオプションとして設計されている (以前はこの点を説明しなかったが、TCP ヘッダーは HdrLen フィールドを持つので長さが一定でない。後から追加されたオプションは可変長の部分に含まれる)。こういった拡張がオプションとして追加され、コアの TCP ヘッダーは変化しないことがなぜ重要かと言えば、ホストがオプションを実装しない場合でも TCP を使った通信を続けられるためである。その一方で、省略可能な拡張を実装するホストはオプションを使った処理を行える。TCP 接続の両端のホストは接続確立フェーズで利用するオプションに合意する。
一つ目の拡張は TCP のタイムアウトの仕組みを改善する。精度の粗いイベントを使って RTT を計測するのではなく、TCP はセグメントを送信する直前に実際のシステムクロックを読んでその値 ── 32 ビットのタイムスタンプ ── をセグメントのヘッダーに書き込む。受信側は ACK にそのタイムスタンプをそのまま書き移して送り返し、送信側は ACK を受け取った時刻のタイムスタンプから ACK に書き込まれているタイムスタンプを引いて RTT を計算する。本質的に、このタイムスタンプオプションは TCP がセグメントの送信開始時刻を記録するための場所となる: 時刻はセグメント自身に刻印される。接続のエンドポイント同士が同期されたクロックを持つ必要はない点に注意してほしい。タイムスタンプは送信側でのみ書き込みと読み込みが行われるので、同期は必要ない。
二つ目の拡張は TCP が持つ 32 ビットの SequenceNum フィールドが高速なネットワークですぐに使い果たされてラップアラウンドが起こる問題を解決する。64 ビットのシーケンス番号フィールドを定義するのではなく、TCP は前段落で説明した 32 ビットのタイムスタンプを使ってシーケンス番号空間を事実上拡張する。言い換えれば、TCP はセグメントの受理あるいは拒否の判断を上位 32 ビットが SequenceNum フィールドで下位 32 ビットがタイムスタンプの 64 ビットの識別子で行う。タイムスタンプは必ず単調増加なので、同じシーケンス番号の異なる具象化を区別するのに利用できる。なお、タイムスタンプはラップアラウンドに対する保護としてだけ利用され、データの並び替えや確認応答で使われるシーケンス番号の一部としては使われない。
三つ目の拡張は通常より大きなウィンドウサイズの広報を可能にする。こうすることで大きな帯域遅延積を持つ高速ネットワークに隙間を作らずにデータを詰められるようになる。この拡張では広報されるウィンドウサイズに対するスケーリングファクターを指定するオプションが利用される。このウィンドウスケーリング (window scaling) のオプションを使うと、ACK を受け取らないで送ってよいバイト数 (ウィンドウのサイズ) を AdvertisedWindow フィールドの値そのものではなく、AdvertisedWindow フィールドの値をスケーリングファクターの値だけ左にシフトした値に設定できる。
四つ目の拡張は通常の累積的な確認応答に加えて先頭の隙間より後ろの部分にある受信済みセグメントに対する選択的な確認応答を可能にする。これは SACK (selective acknowledgment, 選択的確認応答) オプションと呼ばれる。SACK オプションを使うとき、受信者は通常通りの確認応答を行う ── Acknowledgs フィールドの意味は変わらない ── ものの、それに加えてその他に受信済みデータのブロックに対する確認応答をオプションのフィールドを通して行う。SACK オプションを使うと送信側は選択的確認応答によって本当に届いていないことが分かったセグメントだけを再送できるようになる。
SACK が使えない場合、送信側が採用できる戦略は二つしかない。まず、悲観的な戦略ではタイムアウトしたセグメントに加えてそれ以降の全てのセグメントを再送する。つまり、この悲観的な戦略はタイムアウトしたセグメントより後ろの全てのセグメントが喪失した最悪のケースを想定する。この戦略の欠点は、最初の転送で正しく到着したセグメントを不必要に再送する可能性があることである。次に、楽観的な戦略ではタイムアウトしたセグメントだけを再送する。つまり、この楽観的な戦略はセグメントが一つだけ喪失したバラ色のケースを想定する。この戦略の欠点は、輻輳が発生するなどして連続するセグメントが喪失すると転送が不必要に非常に遅くなることである: 喪失した各セグメントの再送は一つ前のセグメントに対する ACK が送信側に届いてから開始されるので、喪失したセグメントごとに RTT だけの時間が消費される。SACK オプションがあれば、送信側はこれらより優れた戦略を採用できる: 選択的な確認応答によって明らかになった隙間に対応するセグメントだけを再送すればいい。
なお、こういった拡張が話の全てではない。TCP が輻輳に対処する方法を見る次章ではさらに異なる拡張が登場する。IANA (Internet Assigned Numbers Authority, インターネット番号割当機関) は TCP を始めとするインターネットで利用される様々なプロトコルに対して定義される全てのオプションを管理しており、例えば TCP の全オプションは https://www.iana.org/assignments/tcp-parameters/tcp-parameters.xhtml から確認できる。
5.2.9 パフォーマンスの測定
第 1.5 節では、ネットワークのパフォーマンスを評価する指標としてレイテンシとスループットを紹介した。そのときの議論でも触れたように、これらの指標は内部のハードウェア (伝播遅延とリンクの帯域) だけではなくソフトウェアによるオーバーヘッドからも影響を受ける。いくつかのトランスポートプロトコルを持つ完全なソフトウェアベースのプロトコルグラフがここまでの説明で理解できたと思うので、これからプロトコルグラフのパフォーマンスを意味のある形で計測する方法を議論する。この計測値はアプリケーションプログラムが体感するパフォーマンスを表すために重要となる。
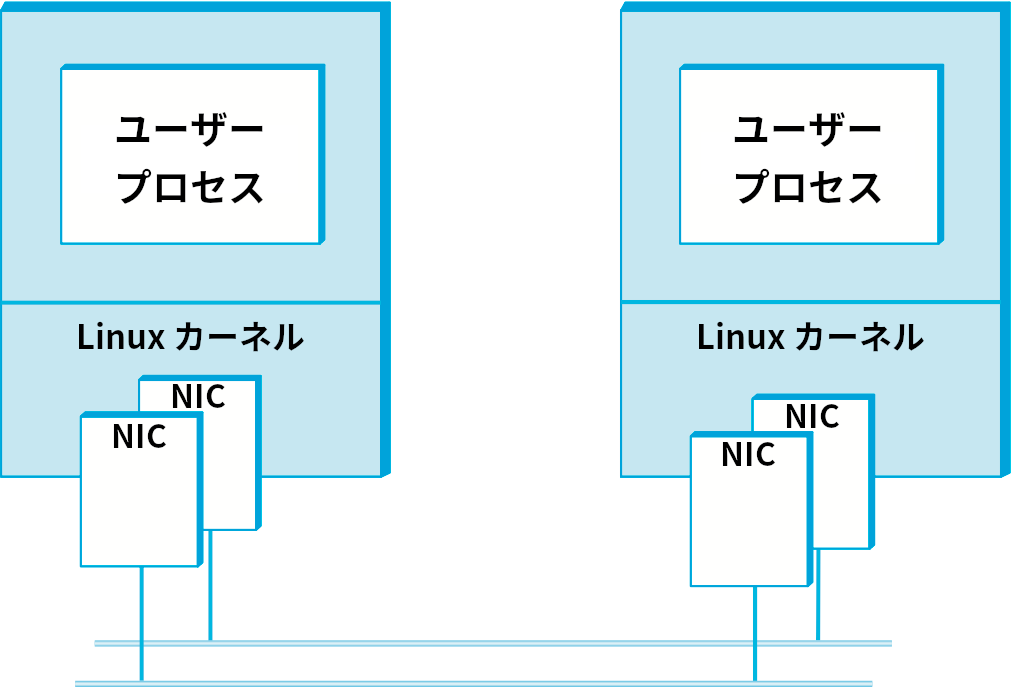
パフォーマンス計測の議論は、実験結果のレポートはどんなものであれ必ずそうでなくてはならないが、実験方法の説明から始まる。実験で用いられる装置も説明しなければならない。今考えている実験では 2.4 GHz の Xeon プロセッサを搭載した Linux マシン二台を用いる。二台のマシンは 2 Gbps のイーサネットリンクで接続されている。1 Gbps を上回る速度での通信を行うために、それぞれのマシンにはイーサネットアダプターが搭載されている。イーサネットアダプターは図中で NIC (network internet card) と表されている。このイーサネットは一つの部屋に収まるので伝播遅延は問題にならず、プロセッサ/ソフトウェアによるオーバーヘッドだけが計測できる。テストプログラムはソケットインターフェースを利用して書かれ、データを可能な限り速く一つのマシンから別のマシンへと移動させるだけの処理を行う。図 135 に全体の構成を示す。
この実験がハードウェアやリンク速度に関して最先端の機材を使っていないことに気が付いたかもしれない。この項のポイントは特定のプロトコルがどれだけ高速に動作できるかを示すことではなく、プロトコルのパフォーマンスを計測して報告するための一般的な方法論を説明することにある。
スループットのテストは TTCP と呼ばれる標準的なベンチマークツールを使って様々なメッセージサイズに対して行われる。この結果を 図 136 に示す。このグラフから分かる重要なポイントは、メッセージが大きくなるとスループットが増加することである。これは理にかなっている ── 各メッセージには一定のオーバーヘッドが存在するので、メッセージを大きくしてバイトあたりのメッセージの長さを短くすればオーバーヘッドは小さくなる。グラフからはメッセージサイズが 1 KB を超えるとスループットを示す曲線が平坦になることも分かる。これはプロトコルスタックが処理しなければならないメッセージごとのバイト数が増えたことで、メッセージごとのオーバーヘッドが相対的に十分小さくなったことを示している。
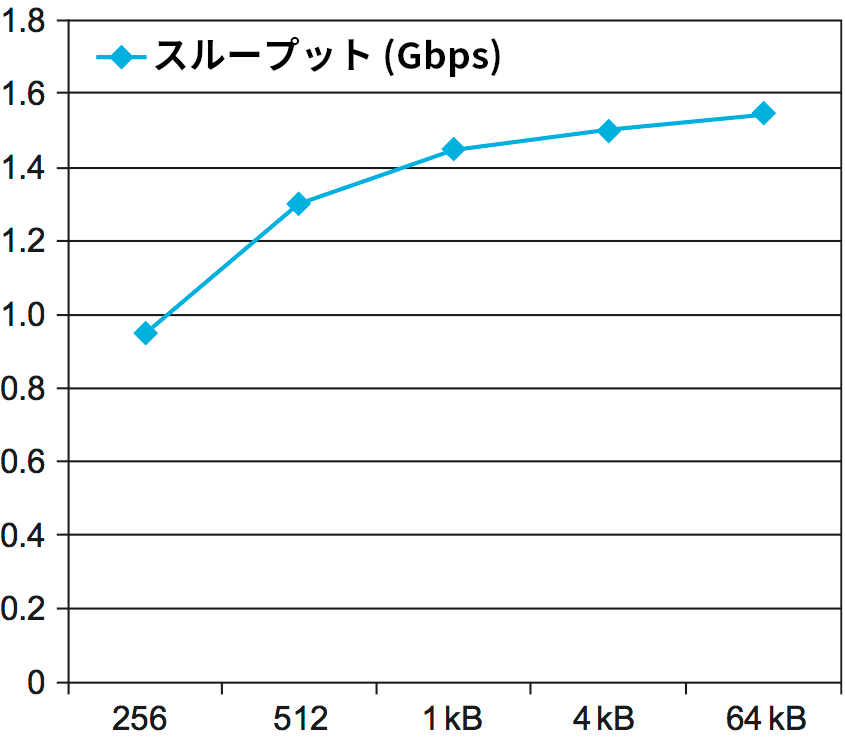
最大のスループットが利用可能な帯域 2 Gbps に満たないことは特筆に値する。ボトルネックを特定するには原因のさらなる調査と解析が必要になるだろう (原因が一つだけとも限らない)。例えば、CPU 負荷を確認すれば CPU がボトルネックなのか、そうではなくメモリ帯域や NIC のパフォーマンス、あるいは別の問題が原因なのかが分かるかもしれない。
また、この実験で用いられるネットワークが「完璧」であることも指摘しておく。このネットワークには遅延もデータ喪失も存在せず、パフォーマンスに影響を及ぼす要因はワークステーションのハードウェアとソフトウェア、そして TCP 実装しかない。これに対して、私たちが実際に頭を悩ませることになるネットワークは完璧から程遠い場合が多い。帯域が制限されたラストマイルリンクやデータ喪失が多い無線リンクがその例である。こういったリンクが持つ TCP のパフォーマンスへの影響を完全に理解するには、TCP が輻輳にどのように対処するかを理解する必要がある。これは次章のトピックとなる。
ネットワークの歴史を通じて何度か、ホストが受信したデータをアプリケーションに届ける速度が止むことなく増加を続けるネットワークリンクの速度に追いつけなくなるのではないかと危惧されたことがあった。例えばアメリカで 1989 年に始まった「ギガビットネットワーク」を構築するための大規模な研究活動では、1 Gbps 以上のリンクとスイッチを作成することだけではなく、それだけのスループットを単一のアプリケーションプロセスに提供することも目標とされた。そこで研究された課題の中には現実の問題となったものもあれば、それほど深刻な問題にならなかったものもある。例えばネットワークアダプター、ワークステーションのアーキテクチャ、オペレーティングシステムは全てネットワークからアプリケーションのスループットを念頭に設計されなければならなかった。そういった課題のリストで上位にあったのは、既存のトランスポートプロトコル (特に TCP) がギガビット毎秒の速度に対応できないのではないかという懸念だった。
実際にどうなったかと言えば、高速なネットワークとアプリケーションからの高まり続ける要求に TCP は問題なく応えることができている。最も重要な要因の一つは大きな帯域遅延積を持つ回線に対応するために導入されたウィンドウスケーリングである。しかし、TCP の理論的なパフォーマンスと実際に達成されるパフォーマンスの間には大きな差がある場合が多い。「ネットワークアダプターからアプリケーションにデータを移すときに必要な回数以上のコピーが発生する」といった比較的軽微な問題であっても、帯域遅延積が大きいときはパフォーマンスに影響をもたらすことがある。加えて TCP は (次章でさらに明らかになるように) 非常に複雑なダイナミクスを持つので、ネットワークの振る舞い、アプリケーションの振る舞い、あるいは TCP プロトコル自身が少し変更されただけでパフォーマンスが大きく変わることがある。
ネットワークを学ぶ私たちにとって重要なのは、ネットワークが高速になっても TCP は非常に上手くその仕事をこなし続けていること、そして何らかの限界 (通常は輻輳か帯域遅延積の増加、あるいはその両方) が近づいたときは研究者たちが我先にと解決策を模索し始めることである。この現象は本章でもいくつか見たものの、次章でもさらに見ることになる。
5.2.10 TCP と異なる設計の選択肢 (SCTP, QUIC)
TCP は広い範囲のアプリケーションの要求に応えられるロバストなプロトコルであることが示されているものの、トランスポートプロトコルの設計空間は非常に広大である。この設計空間に存在できるのは TCP だけというわけでは決してない。TCP に関する議論の締めくくりとして、TCP と異なる設計の選択肢をいくつか見る。TCP が選択した設計とそれを選択した理由を説明する中で、TCP とは異なる選択をした異なるプロトコルが存在すること、そして将来そういったプロトコルが生まれる可能性があることが理解できるだろう。
第一に、本書の最初の章でも示唆したように、トランスポートプロトコルには二つの興味深いクラスが存在する: TCP などのストリーム指向のプロトコルと、RPC などのリクエスト/リプライプロトコルである。言い換えれば、トランスポートプロトコルの設計空間は二つに分割でき、TCP はストリーム指向の側に配置される。ストリーム指向プロトコルの空間は転送が確実かどうかを基準としてさらに二つに分割できる。TCP は確実な転送を行うプロトコルであり、UDP などの確実な転送を行わないプロトコルは対話的映像アプリケーションに適している。映像アプリケーションでデータが届かないときは、再送を行って遅延を発生させるよりフレームを飛ばした方がいい。
こういったトランスポートプロトコルの分類は興味深く、細かい点に注目すればいつまでも続けることができる。しかし、世界はそれほど白黒がはっきりしていない。例えば、リクエスト/リプライ型のアプリケーションで利用するトランスポートプロトコルとして TCP がどれほど適しているかを考えてみよう。TCP は全二重のプロトコルなので、クライアントとサーバー間で TCP 接続を確立し、クライアントがリクエストメッセージを送り、サーバーがリプライメッセージを返すことは簡単に行える。しかし事態を複雑にする要素が二つある。まず、TCP はバイト指向のプロトコルであってメッセージ指向のプロトコルではないのに対して、リクエスト/リプライ型のアプリケーションは必ずメッセージをやり取りする (バイトとメッセージの違いは次の段落で詳しく説明する)。次に、リクエストメッセージとリプライメッセージがどちらも一つのネットワークパケットに収まる状況では、適切に設計されたリクエスト/リプライプロトコルはメッセージの交換を 2 つのパケットで行える。これに対して、 TCP では少なくとも 9 つのパケットが必要になる: 接続の確立に 3 つ、メッセージの交換に 2 つ、接続の終了に 4 つである。もちろん、リクエストメッセージまたはリプライメッセージが十分大きくて複数のネットワークパケットが必要になる (例えば 100,000 バイトのメッセージを送るために 100 個のパケットが必要になる) 場合には、接続の確立と終了にかかるオーバーヘッドは無視できるほど小さくなる。以上の議論は「特定のプロトコルが特定の機能をサポートできないわけではなく、ある設計が特定の問題に対して他の設計より効率的になる場合がある」とまとめられる。
第二に、一つ前の段落でも触れたように、TCP はメッセージストリームではなくバイトストリームのサービスを提供することを選択した。この理由を疑問に思ったかもしれない。レコードを交換するデータベースアプリケーションではメッセージが自然な選択となる。この疑問に対する答えは二つある。第一に、メッセージ指向のプロトコルでは定義によりメッセージサイズに上限が設定される (無限に長いメッセージとはバイトストリームである)。プロトコルがどんなメッセージのサイズを選択したとしても、それより大きなメッセージの送信を望むアプリケーションが現れることだろう。そのようなアプリケーションにとってそのトランスポートプロトコルは使いものにならないので、トランスポート層のサービスを独自に実装することを余儀なくされる。第二に、レコードを送り合うアプリケーションにはメッセージ指向のプロトコルが適しているのは事実であるものの、同じ機能はバイトストリームにレコード境界を挿入することで簡単に実装できる。
第三に、TCP は順序を保ってデータをアプリケーションに届けることを選択した。これはネットワークから実際の並びとは異なる順序でデータが届いた場合に、隙間が埋まるまでデータが取り置かれることを意味する。これは多くのアプリケーションにとって非常に有用であるものの、アプリケーションが順序を気にしないでデータを処理できる場合には邪魔になる。簡単な例を挙げれば、いくつかのオブジェクトが埋め込まれたウェブページを表示するとき、全てのオブジェクトの転送が完了するのを待たなくてもページの描画は開始できる。実際、ネットワークでパケットが破棄されたり順番が前後したりした場合でもデータを素早く手に入れるためにアプリケーション層でデータの順序を保たずに処理することを望むアプリケーションのクラスが存在する。そういったアプリケーションのサポートに対する要望から、IETF で二つのトランスポートプロトコルが標準化された。一つは SCTP (Stream Control Transmission Protocol) であり、TCP のような厳密に順序が保たれたデータ転送ではなく部分的に順序が保たれたデータ転送を提供する (SCTP にはこの他にも TCP と異なる設計判断をした部分がある。例えばメッセージ指向であることや単一セッションで複数の IP アドレスをサポートすることなど)。さらに最近になって、IETF はウェブトラフィックに最適化された QUIC と呼ばれるプロトコルを標準化した。QUIC は後で説明される。
第四に、TCP は明示的な接続の確立/終了フェーズを実装することを選択した。しかし、これが必須なわけではない。接続の確立について言えば、接続に関する必要なパラメータを最初のデータメッセージと一緒に送ることもできる。TCP が保守的なアプローチを選択したのは、データを受け取る前に接続を拒否する機会を受信側に与えるためである。接続の終了について言えば、長い間データをやり取りしていない接続を自動的にクローズすることもできる。しかし、接続が数週間にわたって続くこともあるリモートログインなどのアプリケーションはこの機能を不便に感じるだろう。そういったアプリケーションはアウトオブバンドの「生存報告」メッセージを定期的に送信して、接続の反対側で接続状態が消えてしまうのを防がなければならない。
最後に、TCP はウィンドウベースのプロトコルであるものの、選択肢は他にもある。レートベースの設計がその一つである。この設計では、受信側が送信側にデータを受信する速度を (一秒ごとのバイト数あるいはパケット数の形で) 伝える。例えば、受信側は「一秒間に 100 個のパケットを送って構わない」と送信側に伝えるかもしれない。ウィンドウとレートには興味深い関係がある: ウィンドウに含まれるパケット (あるいはバイト) の個数を RTT で割った値はレートに等しい。例えばウィンドウのサイズがパケット 10 個分で RTT が 100 ms なら、送信側は一秒間に 100 個のパケットを送信できる。受信側は広報するウィンドウサイズを上下させることで送信側がデータを送信できるレートを調整する。TCP において、この情報は各セグメントに対する ACK の AdvertisedWindow フィールドを通して送信側に伝えられる。レートベースプロトコルにおける主要な問題の一つに、望ましいレート ── 時間が経過すると変化する可能性がある ── を送信側に伝えるタイミングの問題がある。パケットごとに伝えるべきだろうか、それとも RTT ごとだろうか、あるいはレートが変わったときだけで十分だろうか? 今はフロー制御の文脈でウィンドウベースとレートベースを比較したものの、次章の話題である輻輳制御の文脈ではさらに激しい議論が存在する。
QUIC
QUIC は Google で 2012 年に誕生し、後に IETF で標準化が進められた。QUIC は既にそれなりの規模でデプロイされている (一部のウェブブラウザや多くの有名なウェブサイトなど)。ここまでの成功を収めた事実そのものが QUIC に関して興味深い点であり、実際 QUIC の設計においてデプロイが簡単に行えること (deployability) は重要な懸念事項だった。
QUIC のモチベーションには本書で TCP に関して述べてきたことが直接関係している: TCP を利用する特定の種類のアプリケーション (重要な例がウェブの HTTP トラフィック) にとって、TCP が下した設計判断の中に最適でないものが存在することが知られており、この問題は時が経つにつれて無視できないようになっていった。その理由としては高レイテンシの無線ネットワークが増加したこと、単一デバイスが複数のネットワーク (例えば Wi-Fi とセルラー) を持つ状況が増えたこと、そして暗号化された認証接続がウェブで頻繁に使われるようになったことが挙げられる。QUIC の完全な説明は本書の範囲を超えるものの、その重要な設計判断は議論するだけの価値がある。
マルチパス TCP
既存のプロトコルが特定のユースケースで上手く使えないときに必ず新しいプロトコルを定義しなければならないわけではない。オリジナルの仕様に従いながらも既存のプロトコルの実装方式を大きく変えることで問題が解決できる場合もある。この戦略を採用したテクノロジの例としてマルチパス TCP (Mutlpath TCP) がある。
マルチパス TCP のアイデアは、エンドポイントが持つ二つの異なる IP アドレスを使うなどしてパケットをインターネット上の複数のパスに流すというものである。これは Wi-Fi とセルラーネットワークの両方に接続される (二つの独立した IP アドレスを持つ) 携帯デバイスにデータを届けるときに特に有用となる。この二つのネットワークは無線なためにパケットロスが非常に多いので、パケットの転送で両方のネットワークを利用できるとユーザーエクスペリエンスが大きく向上する可能性がある。鍵となるのは受信側の TCP がオリジナルのバイトストリームを順序通りに再構築してアプリケーションに届けることであり、この事実があればアプリケーションはマルチパス TCP が使われることに気が付かない (これはパフォーマンスのために意図的に二つ以上の TCP 接続をオープンするアプリケーションとは対照的である)。
マルチパス TCP は単純なものに見えるかもしれないが、TCP のフロー制御、順序を保ったセグメントの再構築、輻輳制御がどのように実装されるかに関する多くの仮定が破られるために正しく動作させるのは非常に難しい。具体的に何が難しいかを調べるのは読者への練習問題とする。この練習問題に取り組めば TCP の基礎的な理解が確認できるだろう。
ネットワークのレイテンシが高い ── 数百ミリ秒程度の ── 状況では、完全なラウンドトリップが何度か行われるだけでエンドユーザーはアプリケーションが「固まった」ことを認識する。TLS が有効な HTTP セッションを TCP で確立する場合、最初の HTTP メッセージを送れるようになるまでに三回 (TCP セッションの確立に一回、暗号パラメータのセットアップに二回) のラウンドトリップが必要になる。QUIC の設計者は、この遅延 ── 層を積み重ねるプロトコル設計の必然的な結果と言える ── は接続のセットアップと必要なセキュリティ関連のハンドシェイクを一緒にしてラウンドトリップを最小限にすることで大きく削減できると理解していた。
それから、複数のネットワークインターフェースの存在が設計にもたらす影響にも注目してほしい。もし携帯電話が Wi-Fi の範囲外に移動してセルラー接続に切り替える必要が生じたとしたら、TCP であれば Wi-Fi 接続でタイムアウトが起こり、セルラー接続を確立するための新しいハンドシェイクが行われる。これに対して接続を異なるネットワーク層接続をまたいで持続させることは QUIC の設計目標だった。
最後に、先述したように、TCP の確実なバイトストリームモデルはウェブページのリクエストには適さない: ウェブページを読み込むには多くのオブジェクトをフェッチする必要がありながらも、ページのレンダリングはオブジェクトのデータが全て届く前に開始できる場合がある。複数の TCP 接続を並列にオープンするというワークアラウンドは存在するものの、初期のウェブで実際に使われていたこのアプローチには (特に輻輳制御に関して) 欠点がある。
興味深いことに、QUIC が生まれた時点で、新しいトランスポートプロトコルのデプロイで問題となる多くの設計判断が既に下されていた。特に、NAT やファイアウォール (第 8.5 節) といった「ミドルボックス」が広く使われる既存のトランスポートプロトコル (TCP と UDP) に関する知識を持っていて、新しいトランスポートプロトコルを通さない場合がある。この結果として、QUIC は UDP を利用して作られている。つまり、QUIC はトランスポートプロトコルの上で実行されるトランスポートプロトコルである。本書ではプロトコルの層に注目しているので意外に思うかもしれないが、これから二つの節を通じて見るように、こういったアプローチは珍しいものではない。
QUIC は最初のラウンドトリップにおける暗号化と認証を持った接続の高速な確立を実装する。また QUIC は下位ネットワークが変化しても持続する接続識別子を提供する。さらに、ヘッドオブラインブロッキング (head-of-line blocking) と呼ばれる単一のパケットが喪失したために正しく届いている他のパケットが無駄になる現象を避けるために、QUIC は単一のトランスポート接続を使った複数ストリームの多重化をサポートする。最後に、TCP が持つ輻輳を避けるための機能は QUIC にも含まれている。
QUIC はトランスポートプロトコルの世界で起きている最も興味深い進展と言える。TCP の欠点の多くは数十年前から知られていたものの、QUIC はトランスポートプロトコルの設計空間における TCP とは異なる点を示して見せる取り組みとして今までで最も成功したものの一つとなった。QUIC は HTTP とウェブ ── どちらも TCP がインターネットに広く普及してから登場した ── での経験に着想を得ているので、層を積み重ねる設計とインターネットの進化における今までにない相互作用の素晴らしいケーススタディと言える。