5.1 単純な逆多重化 (UDP)
可能な中で最も単純なトランスポートプロトコルは、下位のネットワークが提供するホスト間のパケット転送サービスをそのままプロセス間の通信サービスとしたものである。一つのホストで複数のプロセスが実行されることはあるだろうから、このプロトコルは何らかの逆多重化を行ってホストで実行される複数のアプリケーションがネットワークを共有できるようにする必要がある。この要件を除けば、このプロトコルは下位のネットワークによって提供されるベストエフォート型サービスに何の機能も追加しない。こういったプロトコルの例としてインターネットの UDP (User Datagram Protocol) がある。
こういったプロトコルに関連する唯一の興味深い問題として、ターゲットのプロセスを識別するのに使われるアドレスの形式がある。プロセス同士は OS が割り当てるプロセス ID (pid) を利用して互いを直接識別できるものの、pid をプロトコルにおける識別子として利用できるのは、全てのホストが単一の OS によって実行され各プロセスにユニークな識別子が割り当てられるクローズドな分散システムに限られる。これより使われることの多いアプローチは、各プロセスが抽象的な指定子を通して間接的にお互いを識別するものである。これは UDP でも利用されるアプローチであり、抽象的な指定子はポート (port) と呼ばれる場合が多い。送信元プロセスはメッセージをポートに送信し、宛先のプロセスはメッセージをポートから受信するのが基本的なアイデアとなる。
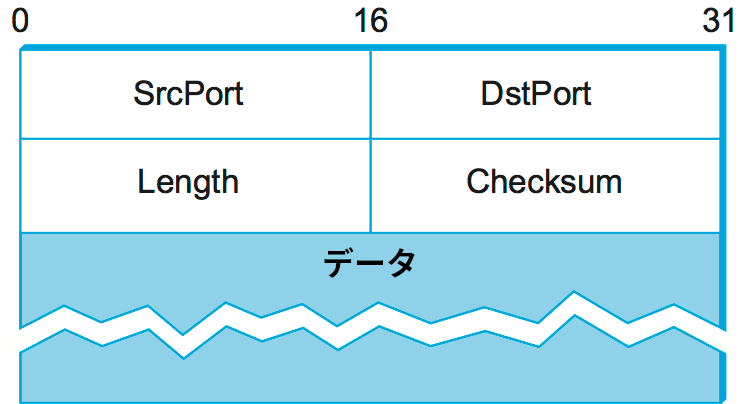
この逆多重化機能を実装するトランスポートプロトコルのヘッダーにはメッセージの送信元 (source) と宛先 (destination) が含まれる。例として 図 125 に UDP ヘッダーを示す。UDP のポートフィールドは長さが 16 ビットしかない点に注目してほしい。これは UDP のポートが最大でも約 65 万個しか存在できないことを意味する。65 万個のポートはインターネットに存在する全てのプロセスを識別するには明らかに足りないものの、幸いポートは単一のホストでのみ解釈されるので問題にならない。つまりプロセスは特定のホストにおけるポートとして識別され、(ポート, ホスト) の組が実際の識別子となる。この組が UDP プロトコルにおける逆多重化鍵の役割を果たす。
続いて、プロセスに宛ててメッセージを送信するときに利用すべきポートを学習する方法が問題となる。典型的なシナリオでは、クライアントプロセスがサーバープロセスとのメッセージ交換を開始する。クライアントが一度でもサーバーと接触できれば、サーバーは (メッセージヘッダーの SrcPrt フィールドから) クライアントのポートを学習できるので、クライアントに対する返答も可能になる。よって本当の問題はクライアントが最初にサーバーのポートを学習する方法となる。この問題に対してよく使われるアプローチは、サーバーがウェルノウンポート (well-known port) でメッセージを受け取るようにするというものである。つまり、各サーバーは広く公開された固定のポートでメッセージを受け取る。これはアメリカで緊急電話サービスに広く知られた電話番号 911 が使われるのと同様と言える。例えばインターネットでは、DNS は各ホストのウェルノウンポート 53 でメッセージを受け取ることが決まっており、他にもメールサービスではウェルノウンポート 25、Unix の talk プログラムではウェルノウンポート 517 を使うなどと決まっている。この対応付けは RFC で定期的に公開されており、たいていの Unix システムではファイル /etc/services から確認できる。ウェルノウンポートが通信の開始地点としてだけ使われる場合もある: クライアントとサーバーはウェルノウンポートを使った通信を通して以降の通信で使う他のポートに合意するだけで、ウェルノウンポートはすぐに他のクライアントから使えるようになる。
もう一つの戦略として、このアイデアを一般化してウェルノウンポートを一つだけにするものがある ── このウェルノウンポートはポートマッパー (port mapper) サービスがメッセージを受け取るのに使われる。クライアントは自身が利用したいサービスで使うべきポートを尋ねるメッセージをポートマッパーのウェルノウンポートに送信し、ポートマッパーは適切なポートを返信する。この戦略を使うと、サービスが利用するポートを後から変更したり、同じサービスを使う複数のホストにそれぞれ異なるポートを割り当てたりするのが簡単になる。
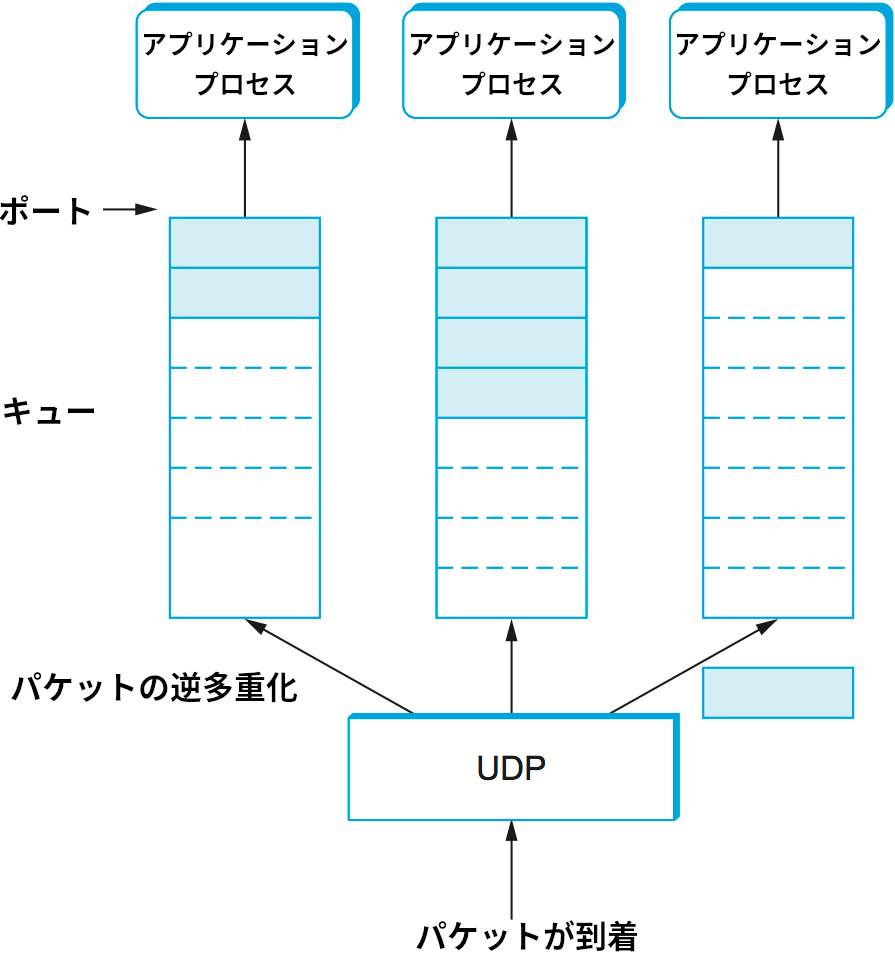
先述したように、ポートは単なる抽象化でしかない。ポートの実装方法はシステムごとに (より正確には OS ごとに) に異なる。例えば第 1 章で説明したソケット API はポートの実装の一つである。典型的にポートは図 126 に示すようなメッセージキューとして実装される。メッセージが届くと、プロトコル (ここでは UDP としよう) の実装がそれをキューの末尾に追加する。もしキューが満杯になら、メッセージは破棄される。送信側にスピードを落とすよう伝えるフロー制御の仕組みは UDP に存在しない。アプリケーションプロセスがメッセージを受け取ろうとすると、キューからメッセージが一つ取り除かれてプロセスに渡される。もしキューが空なら、プロセスはメッセージが利用可能になるまでブロックする。
最後に、UDP はフロー制御や確実な転送、および順序を保った転送を実装しないものの、メッセージの逆多重化と異なる機能を一つだけアプリケーションプロセスに提供する ── UDP はチェックサムを使ってメッセージの正しさを保証する (UDP のチェックサムは IPv4 では省略可能だったものの、IPv6 では必須となった)。UDP のチェックサムアルゴリズムは基本的に IP で使われるものと変わらない ── 入力されたデータを 16 ビットのワードの連なりとして解釈し、各ワードを 1 の補数算術で足し、その和の 1 の補数を取ったものがチェックサムとなる。ただし UDP ではチェックサムの計算に使われる入力データが少しだけ分かりにくくなっている。
UDP のチェックサムは入力として UDP ヘッダー、メッセージの本体、そして疑似ヘッダー (pseudoheader) と呼ばれるものを受け取る。疑似ヘッダーは IP ヘッダーから取ったプロトコル番号、送信元 IP アドレス、宛先 IP アドレスという三つのフィールド、そして UDP のパケット長を表すフィールドからなる (書き間違いではない: UDP のパケット長はチェックサムの計算で二度使われる)。疑似ヘッダーが使われる理由は、メッセージが正しいエンドポイントから正しいエンドポイントへと届けられたことを確認するためである。例えば、もしパケットの転送中に宛先 IP アドレスが変化してパケットが間違ったアドレスに届けられた場合、その事実は UDP チェックサムによって検出される。