基本的なグラフアルゴリズム
知識が分かれ互いに関連する様子を描いたとしたら、それは一つの角度と点で交わる線分の集まりのようにはならず、一つの幹でつながる無数の木の枝のようになる。知識は初め連続的に全体に広がっており、そうでなくなった知識が大枝となる。
ですから、お分かりになるでしょう。この種の問題は数学とほとんど関係がないのです。なぜあなたが他でもない数学者に答えをお求めになるのか、私には理解できません。
いいか、村の消防署を左に曲がって、ため池の隣を通る郵便用の道路を通って ...いやこれじゃ上手く行かないな。
そうじゃなくって、タールで舗装された道路を学校に着くまでまっすぐ行って、左に曲がって、Bennett の湖に向かう道路を ...いやこれでもだめだ。
East Millinocket って言ったか? 考えてみりゃあ、ここからはそこに行けないよ。
導入と歴史
グラフとは組 (pair) を集めたものです ――整数の組、人の組、都市の組、星の組、国の組、科学論文の組、ウェブページの組、ゲームの配置の組、再帰的な小問題の組、さらにグラフの組だって考えます。グラフを図示するときに一番よく使われる方法と対応して、組にされるオブジェクトは頂点 (vertex) あるいはノード (node) と呼ばれ、組そのものは辺 (edge) あるいは弧 (arc) と呼ばれます。しかしもちろん、オブジェクトと組はどんなものでも構いません。
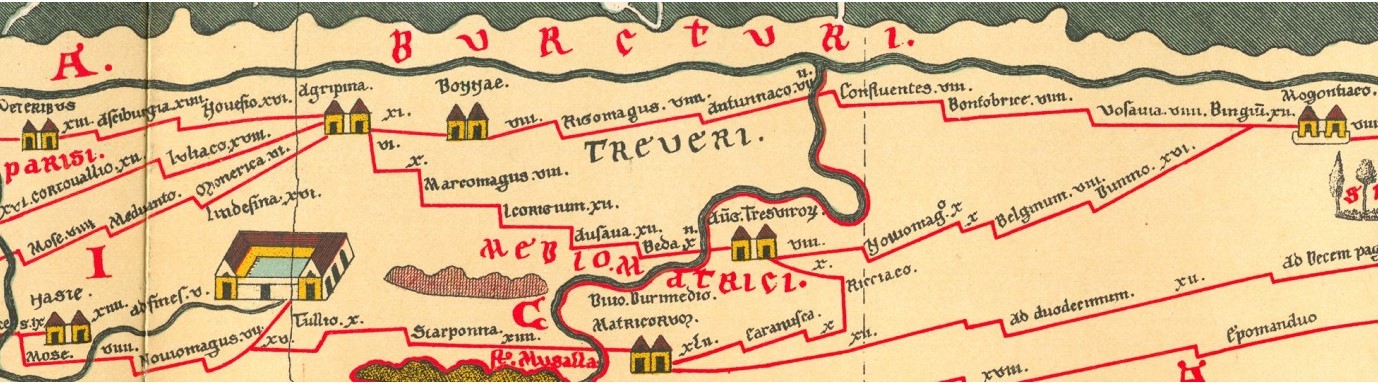
人類が初めてグラフを使った例の一つは、道路ネットワークを表した地図です。ローマ帝国時代、ローマの技師たちはヨーロッパ、西アジア、中央アジア、北アフリカを横断する 400,000km 以上に及ぶ道路ネットワークを構築しました。この道路を利用する旅人はイティネラリア (itineraria) と呼ばれる、道路沿いにある目印や道路の長さを図示した巻物を携帯していました。ポイティンガー図 (Tabula Peutingeriana) はローマのクルスス・プブリクス (Cursus publicus、 ローマ帝国の駅伝制度) を図示した十三世紀の巻物ですが、これのもとになったのは一世紀のアウグストゥス・カエサルの治世中に作成されたイティネラリア・ピクタム (itinerarium pictum) を五世紀に改訂したものであると広く信じられています。ポイティンガー図は地理的に正しい地図ではありません ――歴史家の間にはそもそもこれを地図と呼んでもいいのかという議論さえあります!―― が、道路ネットワークを抽象的に表現しており、その意味では現代の地下鉄の地図と同じと言えます。
ポイティンガー図では道路沿いの都市が道路の垂直に折れる部分で表され、都市の名前や都市の間の道路の長さも地図に示されます。そのためこの地図には五世紀のローマ帝国における任意の二都市間の最短経路を見つけるのに十分な情報が含まれています。
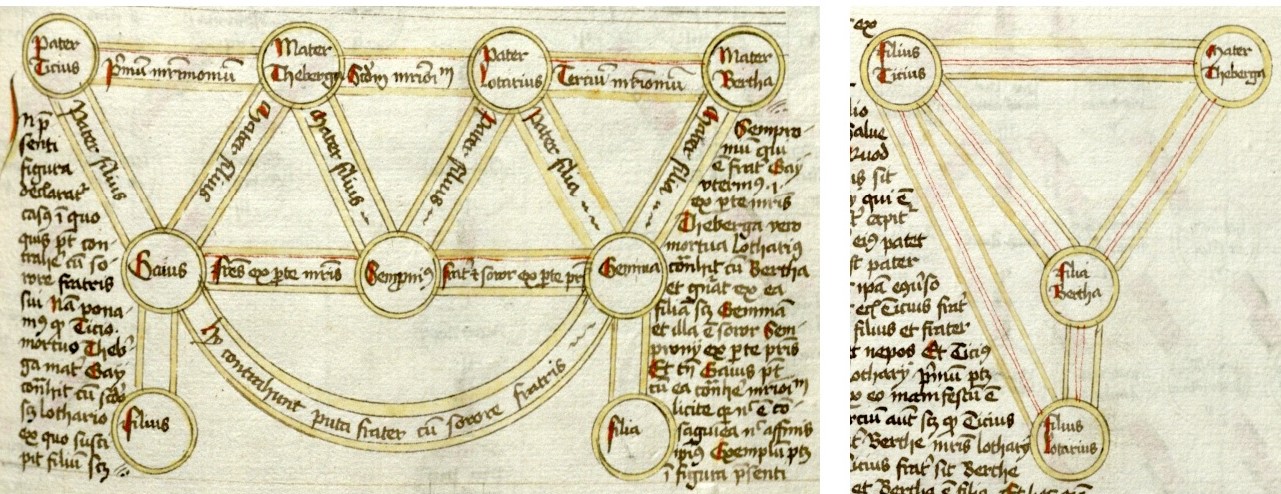
グラフ (の一種である木) の最も古い古典的な応用例の一つは、グラフで表された家系図です。結婚や相続あるいは皇帝の跡継ぎに関する法的な問題を解決するときには、複雑な家系 "木" が何世紀にも渡って使われてきました。後に初期のカトリック教会法に組み込まれることになるローマ法では、いとこよりも近い近親との結婚が禁止されます。つまりローマの computatio legalis では、男女の一番近い共通の祖先との距離の和が少なくとも 4 であることが結婚のために必要でした。九世紀になって教会は必要とされる距離とその計算方法を変更し、新しい computatio canonica は一番近い祖先との距離の最大値が少なくとも 7 であることを要求しました。1215 年には実際に計算を行うのが困難なこと (そして実際に行われていた慣習) に屈する形で、教会は結婚できる距離を 4 としました2。
次の画像に示すのは特に複雑なケースです: 「Tirius と Theburga が結婚し、Tirius が死亡した後に Gaius という子が産まれた。その後 Theburga は Lothar と結婚し、子をもうけ、死亡した。さらに Lothar は Bertha と結婚し、 Gemma という娘をもうけた。 Gaius は合法的に Gemma の娘と結婚できるか?」
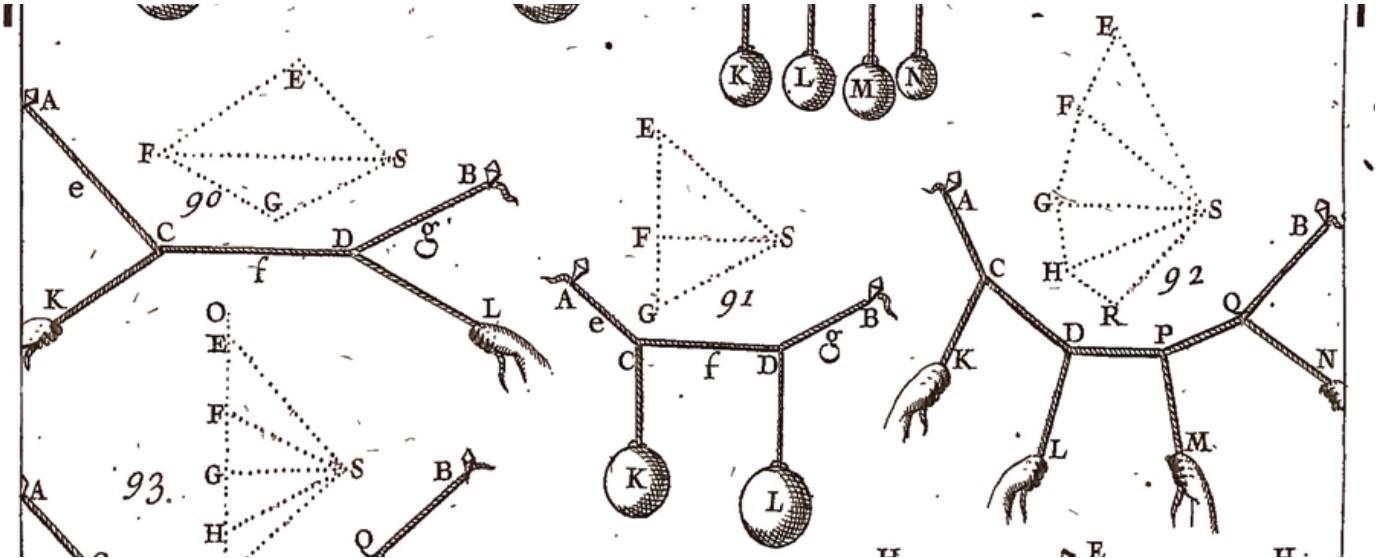
1680 年代の中頃、約一世紀前に出版された Simon Stevin (シモン・ステヴィン) による初期研究を発展させる形で、フランス人数学者 Pierre Varignon (ピエール・ヴァリニョン) は木の形をしたロープのネットワークに張力が働いたときの平衡位置を図を使って計算する方法を開発しました。Varignon が気付いたのは、ロープが平衡状態にあるとき、辺がロープ片と平行なグラフであって、辺の長さが張力と等しく、任意のロープ片の交わる点にグラフの閉路が対応するものが存在するということでした。Varignon の図式に関する研究は彼の死から二年後の 1725 年に完全な形で出版されました。このグラフは現在では reciprocal force diagram あるいは Maxwell-Cremona diagram という名前で知られています。James Clerk Maxwell (ジェームズ・クラーク・マクスウェル) と Luigi Cremona (ルイージ・クレモナ) は Carl Culmann (カール・クールマン) らと共に 1800 年代の終わりにかけてこの図式をもとにした広大な理論を構築しました。
もちろんこれ以外にも身近なグラフの例はたくさんあります:
- ボードゲーム: 古代までさかのぼります。
- 多面体の頂点と辺: 古代ギリシャの哲学者によって詳細に研究されましたが、さらに古い起源を持ちます。
- 星型模様の可視化: 東アジアで紀元前七世紀には行われていました。
- ナイトツアー: 九世紀から十世紀にかけて al-Adli (アル=アドリ)、Rudrata (ルドラータ)、al-Suli (アル=スリ) らによって解明されました。
- 迷路: 現代的なものは Giovanni Fontana (ジョバンニ・フォンタナ) によって 1420 年ごろに作成されました。
- 三角測量: Gemma Frisius (ゲンマ・フリシウス) によって 1533 年に発明され、1615 年には Willebrord Snell (ヴィレブロルト・スネル) が地球の全周を求めるのに利用し、1799 年にはメートルを定義するのに使われました。
- Leonhard Euler (レオンハルト・オイラー) によるケーニヒスベルクの橋パズルに対するよく知られた部分的な5解 (1735)
- 電報およびその他の通信ネットワーク: 最初に提案されたのは 1753 年、その後 1800 年代初頭に Francis Ronalds (フランシス・ロナルズ)、Pavel Schilling (パヴェル・シリング)、Carl Friedrich Gauss (カール・フリードリヒ・ガウス)、Wilhelm Weber (ヴィルヘルム・ヴェーバー) らによって実際に作成され、 1800 年代後半には世界中に配備されました。
- 電子回路: Georg Ohm (ゲオルク・オーム)、James Clerk Maxwell (ジェームズ・クラーク・マクスウェル)、Gustav Kirchhoff (グスタフ・キルヒホッフ) らによって 1800 年代初等に定式化されました。
- 分子構造の法則: 1857 年には August Kekulé (アウグスト・ケクレ) によって、1858 年には Archibald Couper (アーチボルド・クーパー) によってそれぞれ独立に発見されました。
- ソーシャルネットワーク: 社会学者 Jacob Moreno (ヤコブ・モレノ) によって 1930 年代中ごろに初めて研究されました。
- デジタル電子回路: Charles Sanders Pierce (チャールズ・サンダース・パース) によって 1886 年に提案され、Claude Shannon (クロード・シャノン) によって現代的な形になりました。
えぇ、どうしてもというなら言いますよ、現代のインターネットもグラフを使っています。
抽象的な数学的対象としての「グラフ (graph)」という言葉は 1878年に James Sylvester (ジェームス・シルベスター) によって初めて使われました。彼が graph という単語を使い始めたのは、Kekulé がとある代数的不変量を表現するために "chemicograph" という言葉を使っていることを同僚であった William Clifford (ウィリアム・クリフォード) から聞いたためであったと言います。また連結非巡回グラフを「木 (tree)」と始めて呼んだのは Arthur Cayley (アーサー・ケイリー) で、1853 年のことです。ただし抽象的な対象としての木は Gustav Kirchhoff (グスタフ・キルヒホッフ) と Karl von Staudt (カール・フォン・シュタウト) によってそれより 10 年前に使われていました。グラフ理論に関する André Sainte-Laguë (アンドレ・サン=ラグ) による本の第零版は 1926 年に出版され、Dénes Kőnig (デネス・ケーニヒ) による本はそれから十年後です。
基本的な定義
きちんと述べると、 (単純) グラフとは集合の組 \((V, E)\) であって、 \(V\) が任意の空でない有限の集合で、\(E\) が \(V\) の要素の組の集合であるものです。ここで \(V\) の要素は 頂点 (vertex)6 またはノード (node) と呼ばれ、\(E\) の要素は辺 (edge) と呼ばれます。無向グラフ (unordered graph) では辺は順序の無い組、つまり大きさ 2 の集合です。これからは頂点 \(u\) と \(v\) の間の無向辺を \(\lbrace u, v\rbrace\) ではなく \(uv\) と書きます。また \(u\) から \(v\) へ向かう有向辺は \((u, v)\) ではなく \(u \rightarrow v\) と書きます。
標準的な記法に従って、\(V\) でグラフの頂点の数を、 \(E\) でグラフの辺の数を表すことにします (この記法が紛らわしいのは私も認めます)。この記法から、任意の無向グラフについて \(0 \leq E \leq \binom{V}{2}\) であり、任意の有向グラフについて \(0 \leq E \leq V(V - 1)\) と分かります。
辺 \(uv\) および \(u \rightarrow v\) について、頂点 \(u\) と \(v\) を端点 (endpoint) と呼びます。有向辺 \(u \rightarrow v\) の二つの端点については、\(u\) を尾 (tail)、\(v\) を頭 (head) と呼んで区別します。
グラフは組の集合として定義されるので、同じ端点を持つ無向辺および尾と頭が同じ有向辺を複数持つことはできません (有向グラフは辺 \(u \rightarrow v\) とその逆 \(v \rightarrow u\) を持てます)。同様に無向グラフの辺は二つの頂点の集合として定義されているので、端点が同じ辺は複数存在できません。このように端点が同じ辺および多重辺を持たないグラフのことを、単純 (simple) であると言います。単純でないグラフを多重グラフ (multigraph) と呼ぶことがあります。多重グラフの正式な定義は単純グラフと異なっているものの、単純なグラフに対するアルゴリズムの多くはほんの少し変更するだけで多重グラフに対するアルゴリズムに変形できるので、ここで正式な定義を説明する必要はないでしょう。
無向グラフの任意の辺 \(uv\) について、\(u\) は \(v\) の (および \(v\) は \(u\) の) 隣接点 (neighbor) である、あるいは \(u\) は \(v\) に (および \(v\) は \(u\) に) 隣接する (adjacent) と言います。\(v\) 頂点の次数 (degree) とは、その頂点に隣接する頂点の数です。有向グラフでは隣の頂点が二種類存在し、有向辺 \(u \rightarrow v\) について、 \(u\) を \(v\) の前者 (predecessor) あるいは入隣接点 (in-neighbor) と呼び、\(v\) を \(u\) の後者 (successor) あるいは出隣接点 (out-neighbor) と呼びます。有向グラフの頂点 \(v\) の入次数 (in-degree) とは \(v\) の前者の数であり、出次数 (out-degree) とは \(v\) の後者の数です。
グラフ \(G^{\prime} = (V^{\prime}, E^{\prime})\) が \(G = (V, E)\) の部分グラフ (subgraph) であるとは、\(V^{\prime} \subseteq V\) かつ \(E^{\prime} \subseteq E\) であることを言います。 \(G\) の真部分グラフ (proper subgraph) とは、\(G\) の部分グラフで \(G\) と等しくないものを言います。
無向グラフの歩道 (walk) とは、隣り合う頂点がグラフ上で隣接しているような頂点の列のことです。正式な定義ではありませんが、歩道を辺の列と考えることもできます。歩道の最初と最後の点が同じならば、その歩道は (閉じている (closed)) と言います。各頂点に多くとも一度しか通り抜けない歩道を路 (path) と呼びます。グラフ \(G\) の二つの頂点 \(u\) と \(v\) について、 \(u\) から始まって \(v\) に至る歩道 (つまりは路) が存在するとき、\(u\) から見て \(v\) は到達可能 (reachable) であると言います。全ての無向グラフは一つ以上の成分 (component) に分かれます。成分とは極大な連結部分グラフのことであり、二つの頂点が同じ成分に属することはその頂点の間に路があることと同値です7。
最初と最後の頂点が同じ路で一つ以上の辺を含むものを 閉路 (cycle) と呼びます。無向グラフが非巡回 (acyclic) であるとは、部分グラフとして閉路を含まないことを言います。非巡回グラフは森 (forest) とも呼ばれます。連結な非巡回グラフは 木 (tree) と呼びます。無向グラフ \(G\) の全域木 (spanning tree) とは、\(G\) の部分グラフの木であって \(G\) の頂点を全て含むものを言います。グラフが全域木を持つことはグラフが連結であることと同値です。グラフ \(G\) の全域森 (spanning forest) とは \(G\) の各成分に対する全域木を合わせたものです。
有向グラフに対しては少し異なる定義が必要です。有向歩道 (directed walk) とは、有向辺の列であって任意の辺の頭が次の辺の尾と同じものを言います。有向路 (directed path) とは同じ頂点を二度以上含まない有向歩道のことです。有向グラフ \(G\) において頂点 \(v\) が頂点 \(u\) から到達可能 (reachable) であるとは、\(G\) に \(u\) から \(v\) の有向歩道 (つまりは有向路) が存在することと同値です。有向グラフの全ての頂点が他の全ての頂点から到達可能であるとき、その有向グラフは強連結 (strongly connected) であると言います。有向グラフが非巡回 (acyclic) であるとは、有向閉路を持たないことを言います。有向非巡回グラフ (directed acyclic graph) は略して DAG と呼ばれます。
グラフの表現と例
グラフを可視化する最も簡単な方法は描くことです。描いたグラフのことを、グラフの描画 (drawing) と呼びます。グラフの描画は各頂点を平面上の (普通小さい円などで表される) 点に、各辺を頂点間の直線 (または曲線) に対応させます。どの辺も交わらないようにグラフを描画できるとき、グラフは平面 (planar) であると言い、そのような描画を埋め込み (embedding) と呼びます8。同じグラフでも描画はいくつもあり得るので、特定の描画とグラフを混同しないようにしてください。特に、平面グラフにも平面的でない描画があり得ます!

しかし、グラフを上手く表現できるのは描画だけというわけではありません。例えば幾何学的なオブジェクトを使えば交差グラフ (intersection graph) が定義できます。交差グラフの頂点はその幾何学的なオブジェクトであり、その間に辺があるのはオブジェクト同士が交差するときだけです。特定のグラフが交差グラフとして表せるかどうかは頂点としてどんなオブジェクトを考えているかによって変化し、異なる幾何学的オブジェクト (線分、長方形、円など) は異なるグラフのクラスを定義します。特に有用な交差グラフは頂点が数直線上の区間に対応する区間グラフ (interval graph) であり、区間グラフの辺は二つの区間が重なるときに限って存在します。
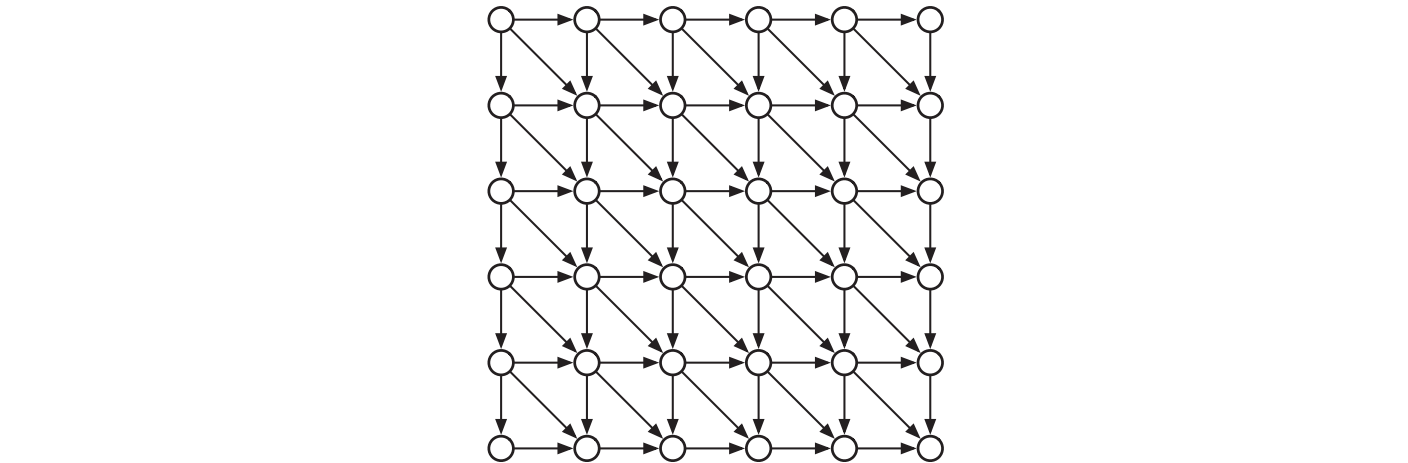
描画以外のグラフの表現のもう一つの良い例は、再帰的な問題に対する依存グラフ (dependency graph) です。依存グラフは有向非巡回グラフであり、頂点は特定の入力に対してアルゴリズムを実行したときに計算される再帰的な小問題を表します。二つの頂点の間に辺があるのは、頭の問題を実行するときに尾の問題が実行されるときだけです。例えばフィボナッチ数列の再帰方程式 \[ F_{n} = \begin{cases} 0 & \text{if } n = 0 \\ 1 & \text{if } n = 1 \\ F_{n-1} + F_{n-2} & \text{それ以外} \end{cases} \] に対する依存グラフは頂点が \(0, 1, 2, \ldots ,n\) であり、2 から \(n\) についての \(i\) について \((i-1) \rightarrow i\) と \((i-2) \rightarrow i\) という辺が存在します:

より複雑な依存グラフを持つ再帰方程式の例としては、三章で扱った編集距離問題に対する再帰方程式があります: \[ \mathit{Edit}(i, j) = \begin{cases} i & \text{if } j = 0 \\ j & \text{if } i = 0 \\ \min \left\lbrace \begin{array}{c} \mathit{Edit}(i - 1, j) + 1 \\ \mathit{Edit}(i, j - 1) + 1 \\ \mathit{Edit}(i - 1, j - 1) + [A[i] \neq B[j]] \end{array} \right\rbrace & \text{それ以外} \end{cases} \]
この再帰方程式に対する依存グラフは \(m \times n\) の格子であり、頂点 \((i, j)\) が垂直な辺 \((i-1, j) \rightarrow (i, j)\) と平行な辺 \((i, j - 1) \rightarrow (i, j)\) と対角方向の辺 \((i - 1, j - 1) \rightarrow (i, j)\) で結ばれています。動的計画法が効率良く動作するのは依存グラフが十分小さい場合であり、動的計画法の正しい評価順序では全ての小問題がその前者よりも後に解かれることが保証されます。
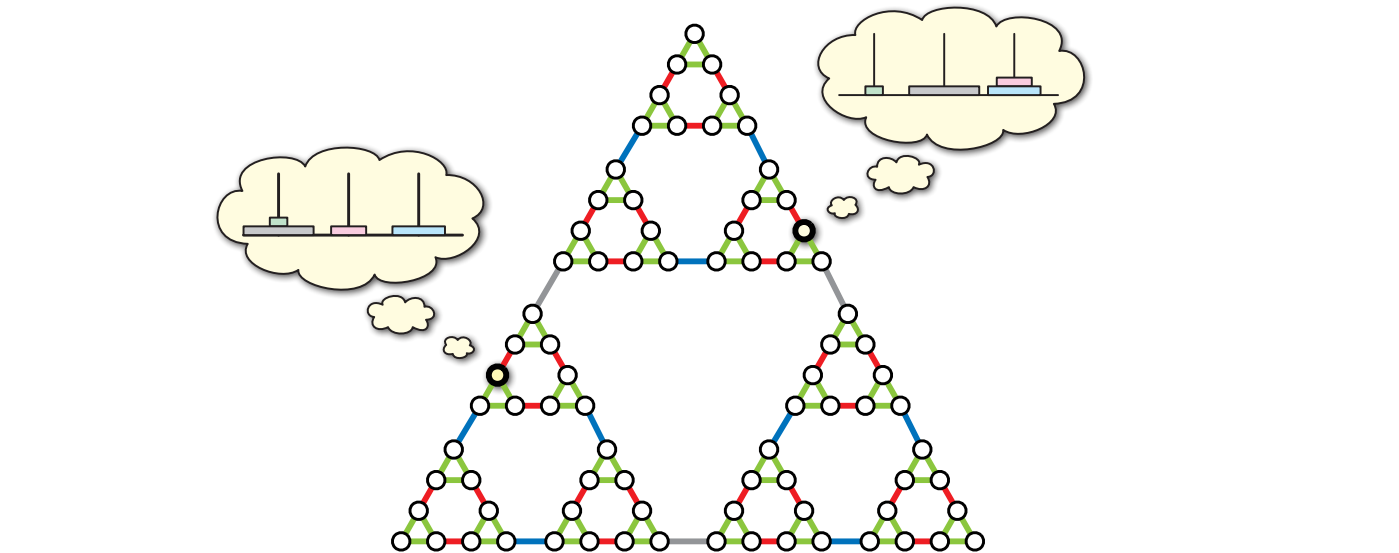
もう一つの面白い例は、ゲーム、パズル、あるいは tic-tac-toe やチェッカー、ルービックキューブなどの装置に対して定義される構成グラフ (configuration graph) です。頂点がパズルの合法な構成を表し、ある構成から別の構成に一つの手で移れる場合に限って対応する頂点の間に辺があります (明らかに、グラフの正確な定義はゲームの合法手が何であるかに依存します)。単純な装置であっても構成グラフが非常に複雑になることがあり、考えている構成グラフの一部に対してしかアクセスできないのが普通です。
構成グラフは二章で考えたゲーム木とよく似ていますが、重要な違いがあります。それは、ゲーム木には同じ状態が何度も現れるのに対して、構成グラフには同じ状態がちょうど一つだけ含まれる点です。つまり、構成グラフはメモ化されたゲーム木です!
形式言語理論で使われる有限状態オートマトン (finite-state automata) もラベル付きの有向グラフとしてモデル化できます。決定性有限状態オートマトンの形式的な定義は 5-タプル \(M = (\Sigma, Q, s, A, \delta)\) を使うものであり、ここで \(\Sigma\) はアルファベットと呼ばれる有限集合、 \(Q\) は状態の有限集合、\(s \in Q\) は開始状態、\(A \subseteq Q\) は受理状態、 \(\delta: Q \times \Sigma \rightarrow Q\) は遷移関数を表します。しかしこの定義を使わずに \(M\) を有向グラフ \(G_{M}\) として定義し、\(G_{M}\) の頂点が状態 \(Q\) で、全ての \(q \in Q\) と \(a \in \Sigma\) に対して \(q \rightarrow \delta(q, a)\) という辺が存在するとした方が考えやすいことが多いです。 \(M\) が受理する言語 \(L(M)\) に関する基本的な問題はグラフ \(G_{M}\) に対する問題に変換できます。例えば、 \(L(M) = \varnothing\) は開始状態/頂点 \(s\) から到達可能な受理状態/頂点が存在しないことと同値です。
最後に、あるグラフがもっと大きなグラフを暗黙のうちに表現することがあります。分かりやすい例は NFA を DFA に変換するときに使う部分集合の構築です。具体的には、与えられた有向グラフ \(G=(V, E)\) から新しい有向グラフ \(G^{\prime} = (2^{V}, E^{\prime})\) を作る操作です。ここで頂点 \(2^{V}\) は \(V\) の全ての部分集合であり、辺 \(E^{\prime}\) は次の式で定義されます: \[ E^{\prime} := \lbrace A \rightarrow B\ |\ \text{ある } u \in A \text{ と } v \in B \text{ があって } u \rightarrow v \in E \rbrace \] この定義を機械的に翻訳すれば \(G\) から \(G^{\prime}\) を構築するアルゴリズムが得られますが、この構築は必要ではありません。なぜなら \(\pmb{G}\) は既に \(\pmb{G^{\prime}}\) の陰的な表現だからです。
ここまでに説明してきた例/表現を正式な定義と混同しないように注意してください。グラフとは集合の組 \((V, E)\) であり、\(V\) は任意の集合、\(E\) は \(V\) の要素の (順序の有る、または無い) 組の集合です。一言で言えば: グラフは物の組の集合です。
データ構造
実際のプログラムでグラフを扱うときは、たいていは隣接リストと隣接行列という二つのよく知られたデータ構造のどちらかを使ってグラフを表現することになります。高いレベルで抽象的に言うと、どちらのデータ構造も頂点を添え字とした配列です。各頂点に \(1\) から \(V\) のユニークな整数を割り当てて、この整数と頂点を同一視します。
隣接リスト
グラフの格納に使われる最も一般的なデータ構造は隣接リスト (adjacency list) です。隣接リストはリストの配列であり、配列の各要素が一つの頂点に隣接する全ての頂点 (有向グラフの場合は出隣接点9) を保持します。無向グラフでは、全ての辺 \(uv\) は隣接リストに二度格納されます: 一度は \(u\) の隣接リストに、もう一度は \(v\) の隣接リストに格納されるからです。これに対して無向グラフでは、辺 \(u \rightarrow v\) はその尾 \(u\) の隣接リストに一度だけ格納されます。無向グラフと有向グラフの両方において、隣接リストに必要になる空間量は \(O(V+E)\) です。
隣接リストを表現する方法はいくつかありますが、通常の実装は一重連結リストを使います。こうした場合、\(v\) の隣接リストをたどることで、頂点 \(v\) に隣接する頂点を \(O(1 + \deg (v))\) 時間で列挙できます。同様に \(u \rightarrow v\) が辺かどうかは、\(u\) の隣接リストをたどることで \(O(1 + \deg (u))\) 時間で判定できます。無向グラフでは、この時間を \(O(1 + \min \lbrace \deg (u), \deg (v) \rbrace)\) にできます: \(u\) と \(v\) の隣接リストを同時にたどれば、目的の辺またはどちらかの終端までたどるだけで済むからです。
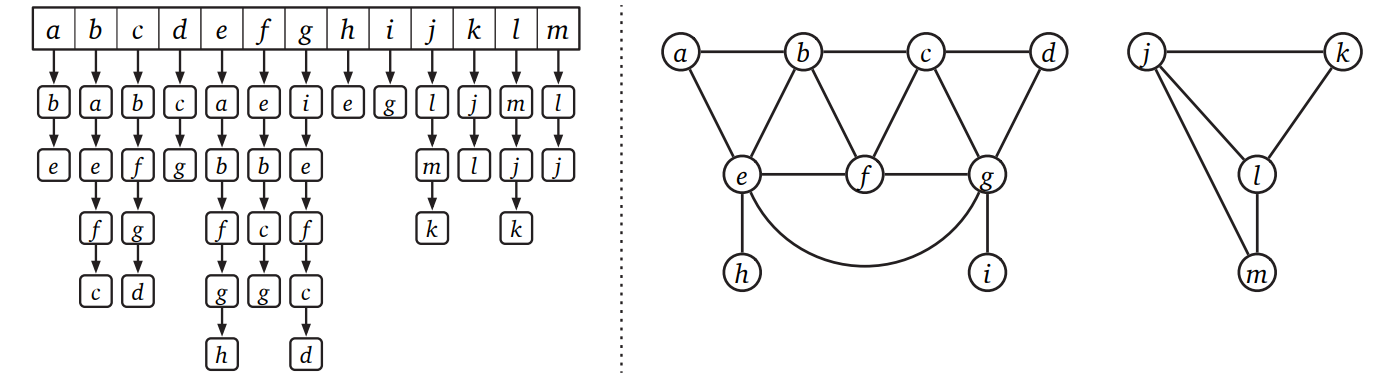
もちろん、隣接リストの実装に使うことができるデータ構造が連結リストだけであるというわけではありません。探索、列挙、挿入、削除をサポートするデータ構造であれば何でも使うことができます。例えばバランスの取れた二分探索木を使って \(u\) の隣接頂点を格納すれば、 \(uv\) が辺かどうかを判定するのにかかる時間を \(O(1 + \log(\deg(u)))\) に削減できます。あるいは適切に構築されたハッシュテーブルを使って、探索を \(O(1)\) 時間にすることだってできます10。
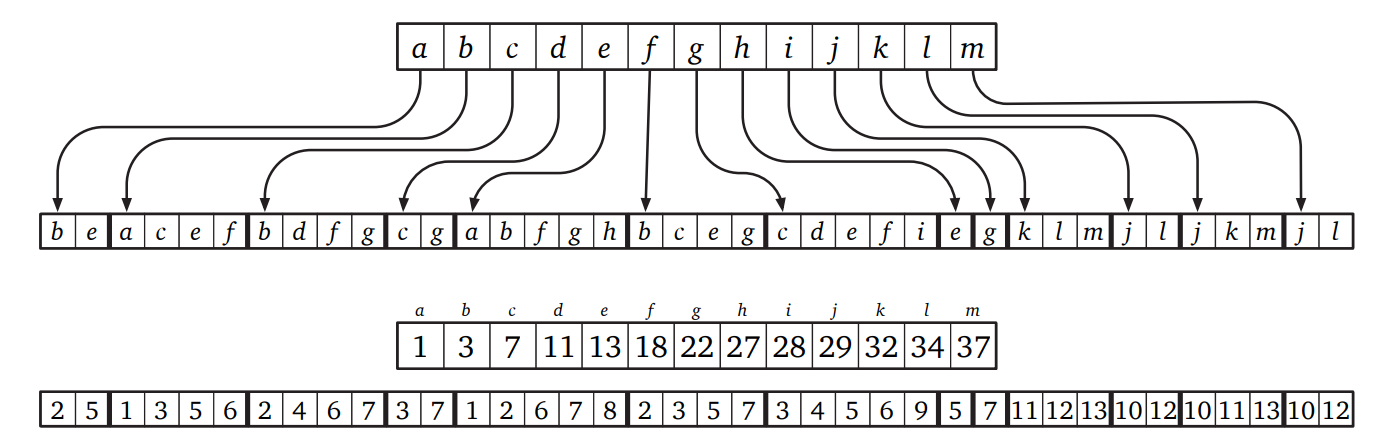
もう一つのよく使われる隣接リストの実装は隣接配列 (adjacency array) です。一つの配列 (図中下) には全ての辺が格納され、ある頂点を始点とする辺の集合が連続する部分列で表されます。そしてもう一つの配列 (図中上) には各頂点に対応する一つ目の配列の部分列が始まる場所が格納されます。加えて下の図に示すように各頂点に対応する部分配列をソートした状態に保っておくと、 \(u\) と \(v\) が隣接しているかどうかを \(O(\log \deg (u))\) 時間で判定できます。
隣接行列
グラフを表現するもう一つのよく知られたデータ構造は隣接行列 (adjacency matrix) です。1894年に George Burunel (ジョージ・ブルーネル) によって最初に提案されました。グラフ \(G\) の隣接行列とは要素が \(0\) と \(1\) からなる \(V \times V\) の行列で、通常は二次元配列 \(A[1..V, 1..V]\) によって表されます。隣接行列の各要素は辺に対応し、その辺が \(G\) に存在するかどうかを表します:
- グラフが無向ならば、全ての頂点 \(u, v\) に対して \(A[u,v] := [uv \in E]\)
- グラフが有効ならば、全ての頂点 \(u, v\) に対して \(A[u,v] := [u \rightarrow v \in E]\)
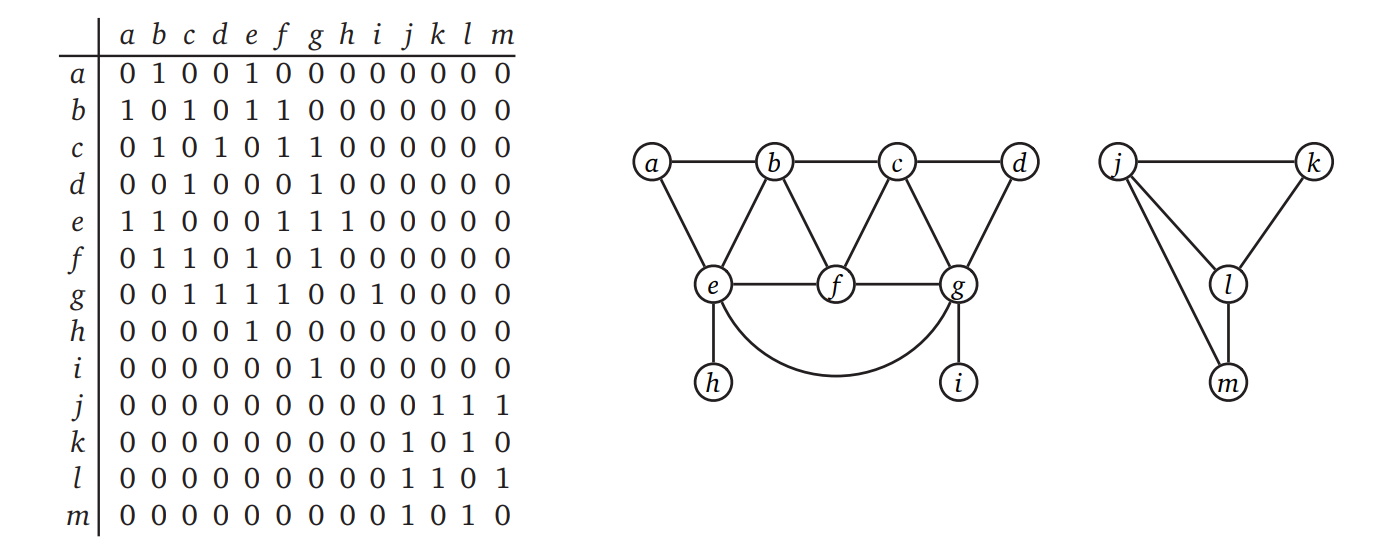
無向グラフでは \(uv\) と \(vu\) は同じ辺に対する違う名前にすぎないので、任意の \(u, v\) に対して \(A[u,v] = A[v,u]\) であり、隣接行列は必ず対称です。また無向グラフの対角要素 \(A[u,u]\) は全て \(0\) です。これに対して有向グラフに対する隣接行列は対称でないこともあり、対角要素も \(0\) だとは限りません。
隣接行列が与えられたとき、二つの頂点が辺で結ばれているかの判定は \(\Theta(1)\) 時間で行えます。行列の対応する要素を調べるだけで済むからです。またある頂点に隣接する頂点の列挙は、対応する行 (または列) を走査することで \(\Theta(V)\) 時間で行えます。この実行時間は最悪ケースでは最適ですが、頂点に隣接する頂点が少ししか無いときにも列全体を走査する必要があります。同様に、隣接行列はグラフに含まれる辺の数に関わらず \(\Theta(V^{2})\) の空間を必要とします。このため隣接行列は密なグラフを表すときの空間効率に優れています。
比較
基本的なグラフデータ構造のパフォーマンスを次の表にまとめます。星印 \({}^{\ast}\) は動的ハッシュテーブルを使った場合の期待償却計算時間 (expected amortized time11)を示します。 \[ \footnotesize \begin{array}{c|ccc} & \text{標準的な隣接リスト} & \text{高速な隣接リスト} & \text{隣接行列} \\ & \text{(連結リスト)} & \text{(ハッシュテーブル)} & \\ \hline \text{空間} & \Theta(V + E) & \Theta(V + E) & \Theta(V^{2}) \\ \hdashline uv \in E \text{ の判定} & O(1 + \min \lbrace \deg(u),\ \deg(v) \rbrace) = O(V) & O(1) & O(1) \\ u \rightarrow v \in E \text{ の判定} & O(1 + \deg(u)) = O(V) & O(1) & O(1) \\ v \text{ の隣接頂点の列挙} & \Theta(1 + \deg(v)) = O(V) & \Theta(1 + \deg(v)) = O(V) & O(V) \\ \text{全ての辺の列挙} & \Theta(V + E) & \Theta(V+E) & \Theta(V^{2}) \\ \text{辺 } uv \text{ の追加} & O(1) & O(1)^{\ast} & O(1) \\ \text{辺 } uv \text{ の削除} & O(\deg(u) + \deg(v)) = O(V) & O(1)^{\ast} & O(1) \end{array} \]
時間効率にも空間効率にも劣る隣接行列を使おうとする人がいるのか、というのはこの比較を見たときに生じるもっともな疑問です。隣接行列を使う一番の理由は、十分に密なグラフに対しては隣接行列を使った方がより単純でかつ実際の効率も良いからです。隣接行列にはポインタを使った間接参照やハッシュ関数によるオーバーヘッドが無く、連続したメモリ領域を処理できます。
同様に、二分探索木やハッシュテーブルではなくて連結リストを使って隣接リスト構造を実装する人がいるのか、というのももっともな疑問です。実際にプログラムを書く人の最初の答えはまず間違いなく「みんなそうしてるから」 ――Donald Knuth のコードで問題なかったのなら、自分のコードで使っても問題ないに違いない!―― ですが、もう少しきちんとした議論もできます。一つ目の理由は、ほとんどのアプリケーションでは連結リストを使った普通の隣接リストで十分なことです。大多数の標準的なグラフアルゴリズムにおいては、特定の辺が存在するかどうかを判定したり、辺の追加/削除したりすることが全く (あるいはほとんど) ありません。そのためそういった操作を高速化するためのデータ構造は不必要です。
しかし私の意見では、二つの標準的なデータ構造を使う最も説得力ある理由は「多くのグラフが隣接行列または標準的な隣接リストを暗黙のうちに定義するから」です。例えば:
-
区間グラフは基本となる幾何学的オブジェクトのリストとして定義されるのが普通です。二つのオブジェクトが交差するかどうかを定数時間で判定できるならば、入力のグラフが隣接行列として与えられたとみなしてグラフアルゴリズムを区間グラフに適用できます。
-
互いを指すポインタを持つレコードからなる任意のデータ構造は有向グラフとみなせます。このデータ構造を標準的な連結リストで表されたグラフだとみなせば、グラフアルゴリズムをこのデータ構造に適用できます。
-
同様に、ゲームの任意の構成からの次の手を (一手につき) 定数時間で列挙できるならば、そのゲームの構成グラフが標準的な隣接リストで表されているとみなしてグラフアルゴリズムを構成グラフに適用できます。
最後の二つの例では任意の頂点から出る辺をその頂点の次数に比例する時間で列挙できますが、二つの頂点の間に辺があるかを定数時間で求めることは必ずしも可能とは限りません (「このレコードからあのレコードの間へ向かうポインタはあるか?」あるいは「この構成からあの構成に一手で行けるか?」)。さらに、レコードのポインタの整理やゲーム構成の定義の変更によってデータ構造の効率を改善することは通常できません。このような理由により、隣り合う頂点を連結リストに収めた標準的な連結リストがこの種のデータ構造を表現するのに適しています。
この本ではこの先、明示的にそうでないと書く場合を除いて、グラフアルゴリズムの実行時間の解析は入力グラフが標準的な (連結リストを使った) 隣接リストで表されていることを仮定して行います。同様に、明示的に書く場合を除いて、練習問題でアルゴリズムを説明、解析するときには入力グラフが標準的な隣接リストで表されていると仮定してください。
何か優先探索
ここまではグラフに対する局所的な操作のみを考えてきましたが、ここからはグラフ全体に関する操作や性質を考えます。グラフ全体に関係する最も基礎的な性質は到達可能性 (reachablity) です。到達可能性問題では、グラフ \(G\) と頂点 \(s\) が与えられたときにどの頂点が \(s\) から到達可能か、つまり \(s\) からの路が存在する頂点はどれかを考えます。まずは無向グラフを考え、有向グラフは節の終わりで軽く触れることにします。無向グラフでは、\(s\) から到達可能な頂点は \(s\) の成分に含まれる頂点に等しくなります。
再帰的に考えることに慣れている私たちのような人にとって、到達可能性問題に対する最も自然なアルゴリズムは次に示す深さ優先探索 (depth-first serach, DFS) です。このアルゴリズムは再帰的にも手続き的にも書くことができ、どちらの方法を使ってもアルゴリズムは全く同じです。唯一の違いは、再帰的でないバージョンでは "再帰" スタックを実際に見ることができる点です。
procedure \(\texttt{RecursiveDFS}\)(\(v\))
if \(v\) に印が付いていない then
\(v\) に印を付ける
for \(vw\) の形をした辺 do
\(\texttt{RecursiveDFS}\)(\(w\))
procedure \(\texttt{IterativeDFS}\)(\(s\))
\(\texttt{Push}\)(\(s\))
while スタックが空でない do
\(v \leftarrow\)\(\texttt{Pop}\)()
if \(v\) に印が付いていない then
\(v\)に印を付ける
for \(vw\) の形をした辺 do
\(\texttt{Push}\)(\(w\))
深さ優先探索は、私が何か優先探索 (whatever-first search) と呼ぶ一般的なグラフ走査アルゴリズムのクラスに属する (おそらくは一番有名な) アルゴリズムです。何か優先探索という一般的なグラフ走査アルゴリズムでは、候補となる辺を「袋 (bag)」と私が呼ぶデータ構造に保存します。この「袋」が持つべき機能は一度入れたものを後で取り出す機能だけです。スタックは袋の具体的な例ですが、もちろん、袋となれるのはスタックだけではありません。
一般的な何か優先探索アルゴリズムを次に示します:
procedure \(\texttt{WhateverFirstSearch}\)(\(s\))
袋に \(s\) を入れる
while 袋が空でない do
袋から頂点を取り出して \(v\) とする
if \(v\) に印が付いていない then
\(v\) に印を付ける
for \(vw\) の形をした辺 do
\(w\) を袋に入れる
\(\textsc{WhateverFirstSearch}\) が \(s\) から到達可能な頂点全てに印をつけ、それ以外の頂点に印をつけないことをこれから示します。このアルゴリズムが \(G\) に含まれる全ての頂点に最大でも一回ずつ印をつけるのはすぐに分かります。一方で \(s\) から到達可能な全ての頂点に少なくとも一回印が付くことを示すには、アルゴリズムを次に示すように少し変更する必要があります。赤く示されたこの変更を行うと、最初に頂点 \(v\) を訪れたときに、\(v\) を袋に入れたときに処理していた頂点を思い出すことができます。以降この頂点を \(v\) の親 (parent) と呼びます。
procedure \(\texttt{WhateverFirstSearch}\)(\(s\))
袋に \(\color{red}{(\varnothing, s)}\) を入れる
while 袋が空でない do
袋から要素を取り出して \(\color{red}{(p, v)}\) とする \((\star)\)
if \(v\) に印が付いていない then
\(v\) に印を付ける \((\dagger)\)
\(\color{red}{\mathit{parent}(v) \leftarrow p}\)
for \(vw\) の形をした辺 do
\(\color{red}{(v, w)}\) を袋に入れる \((\star \star)\)
命題 5.1 \(\textsc{WhateverFirstSearch}\) は \(s\) から到達可能な全ての頂点に印をつけ、それ以外の頂点に印をつけない。そして、\(\mathit{parent}(v) \neq \varnothing\) である全ての \((v, \mathit{parent}(v))\) の組の集合は \(s\) を含む成分の全域木を定義する。
証明 \(s\) から到達可能な頂点 \(v\) 全てに印が付くことをまず示す。\(s\) から \(v\) への最短路の長さについての帰納法を用いる。まず、アルゴリズムは \(s\) に印をつける。\(v\) を \(s\) から到達可能な頂点とし、 \(s\) から \(v\) への最短路を \(s \rightarrow \cdots \) \(\rightarrow u \rightarrow v\) とする (\(v\) が \(s\) から到達可能なことから、この路は必ず存在する)。接頭部分 \(s \rightarrow \cdots \rightarrow u\) は \(s\) から \(v\) への最短路よりも短いから、帰納法の仮定よりアルゴリズムは \(u\) に印をつける。 \(u\) に印が付くとき、アルゴリズムはその後すぐに \((u, v)\) を袋に入れ、後で取り出される。\((u, v)\) を袋から取り出したとき、既に印が付いていない限り \(v\) には印が付けられる。よって示せた。
\(\mathit{parent}(v) = \varnothing\) を満たす組 \((v, \mathit{parent}(v))\) は \(G\) における辺である。印の付いた任意の頂点 \(v\) について、親をたどって行く路 \(v \rightarrow \mathit{parent}(v) \) \(\rightarrow \mathit{parent}(\mathit{parent}(v))\) \(\rightarrow \cdots\) がいつか \(s\) に戻ることをこれから示す。頂点に印がつけられた順番についての帰納法で示す。\(s\) が \(s\) から到達可能なのは自明だから、\(v\) を印の付いた \(s\) 以外の頂点とする。帰納法の仮定より \(\mathit{parent}(v) \rightarrow\) \(\mathit{parent}(\mathit{parent}(v)) \rightarrow \cdots\) は \(s\) に戻ってくる。この路に最初の部分に辺 \(v \rightarrow \mathit{parent}(v)\) を加えれば求めたい路が得られる。よって示せた。
このことから、\(s\) から到達可能な全ての頂点には印が付き、印の付いた頂点とその親を結ぶ辺を全て合わせると連結なグラフとなる。\(s\) 以外の印の付いた頂点はただ一つの親を持つので、このグラフの辺の数は頂点の数より \(1\) 小さい。すなわち、親をたどる辺が作るこのグラフは木である。 \(\Box\)
解析
この走査アルゴリズムの実行時間は "袋" のデータ構造に依存するので、袋に一つの要素を挿入する操作と袋から要素を取り出す操作の実行時間を \(T\) とします。\((\dagger)\) は印の付く頂点に対して一度ずつ実行されるので、最大でも \(V\) 回実行されます。また \(s\) の成分に含まれる辺 \(uv\) は (組 \((u,v)\) および \((v, u)\) として) 二度袋に入れられるので、\((\star \star)\) は最大でも \(2E\) 回実行されます。最後に、袋に入れた回数よりも多く袋から取り出すことはできないので、\((\star)\) は最大でも \(2E + 1\) 回実行されます。したがって、\(G\) が標準的な隣接リストで与えられるという仮定の下では、\(\textsc{WhateverFirstSearch}\) の実行時間は \(\pmb{O(V + ET)}\) です (もし隣接行列を使うなら実行時間は \(O(V^{2} + E T)\) です)。
重要な変種
スタック: 深さ優先
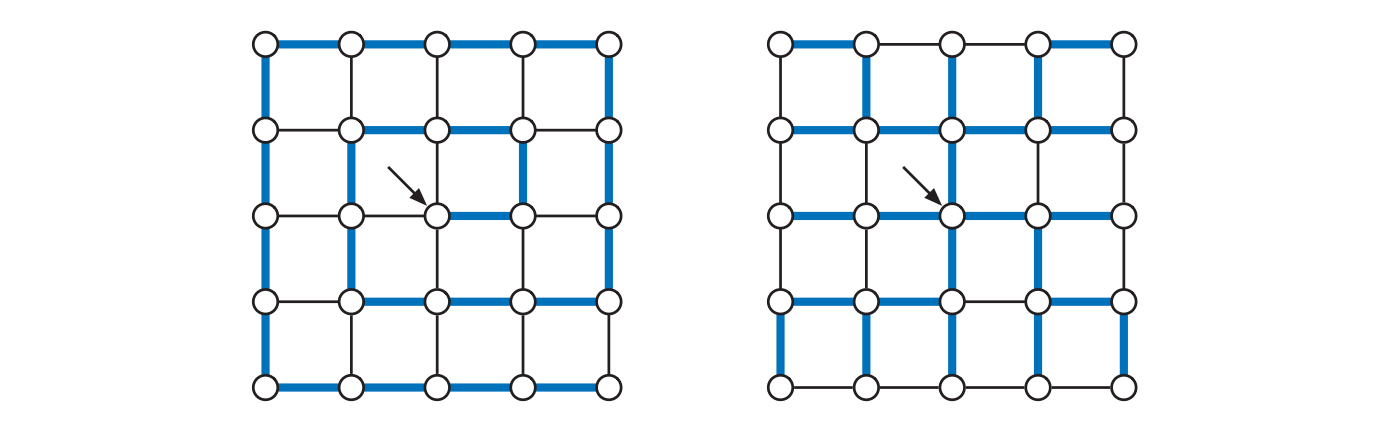
"袋" としてスタックを使って何か優先探索を実装した場合、以前に紹介した深さ優先探索となります。スタックでは挿入 (プッシュ) と削除 (ポップ) をそれぞれ \(O(1)\) 時間で行えることから、アルゴリズム全体の実行時間は \(\pmb{O(V + E)}\) です。親へ向かう辺を集めることで形成される全域木は深さ優先全域木 (depth-first spanning tree) と呼ばれます。この全域木の正確な形は探索を始める頂点と for ループにおいて辺を選ぶ順番に依存しますが、一般的に言って、深さ優先全域木は細長い形になります。深さ優先探索の重要な特徴と応用については六章で見ます。
キュー: 幅優先
"袋" としてキューを使って何か優先探索を実装した場合、幅優先探索 (breadth-first search, BFS) と呼ばれる別のグラフ走査アルゴリズムとなります。キューは挿入 (プッシュ) と削除 (プル) をそれぞれ \(O(1)\) で行えるので、アルゴリズム全体の実行時間は \(\pmb{O(V + E)}\) です。この場合、親への辺を集めた全域木は幅優先全域木 (breadth-first spanning tree) と呼ばれます。また \(s\) 以外の各頂点から親への辺をたどっていくと \(s\) からその頂点への最短路が手に入ります。最短路問題については八章で扱います。幅優先全域木の正確な形はここでも探索を始める頂点と for ループ において辺を選ぶ順番に依存しますが、一般的に言って、幅優先全域木の形は短いブラシ状になります。
優先度付きキュー: 最良優先
最後の例は "袋" として優先度付きキューを使って何か優先探索を実装する場合で、このときに手に入るのは最良優先探索 (best-first search) と呼ばれるアルゴリズムのクラスです。優先度付きキューには全ての辺が最大で一回ずつ格納され、辺の追加および優先度が最低の辺の取り出しには \(O(\log E)\) 時間かかるので、最良優先探索の実行時間は \(\pmb{O(V + E \log E)}\) です。
最良優先探索をアルゴリズムの "クラス" と言ったのは、辺に優先度を付ける方法がいくつかあり、異なる優先度の付け方によって異なるアルゴリズムが手に入るためです。ここではよく知られた変種を三種類紹介します。これから紹介するアルゴリズムでは、全ての辺 \(uv\) または \(u \rightarrow v\) が非負の重み \(w(uv)\) または \(w(u \rightarrow v)\) を持っているとします。
まず、無向グラフの入力に対して辺の重みを優先度として使った場合、最良優先探索は \(s\) の属する成分の最小全域木 (minimum spanning tree) を構築します。意外なことに、全ての辺の重みが異なっているならば、最小全域木の形は探索を始める頂点や隣接する頂点を調べる順番に依存しません: このような条件では最小全域木が唯一となります。最良優先のこのインスタンスは通常 Prim (プリム) のアルゴリズムとして知られています (が、ここでも名前は正しくありません)。このアルゴリズムと他の最小全域木アルゴリズムは七章で扱います。
次に、路の長さを辺の重みの和として定義し、この長さを優先度として最良優先探索を行うと、\(s\) から各頂点への最短路 (shortest path) を計算できます。このアルゴリズムでは印の付く頂点 \(v\) に対して距離 \(\mathit{dist}(v)\) が記録されます。最初 \(s\) に対しては \(\mathit{dist}(s) = 0\) とします。他の全ての頂点 \(v\) に対しては \(\mathit{parent}(v) \leftarrow p\) とするときに \(\mathit{dist}(v) \leftarrow \mathit{dist}(p) + w(p \rightarrow v)\) と設定し、優先度付きキューに辺 \(v \rightarrow w\) を挿入するときには優先度として \(\mathit{dist}(v) + w(v \rightarrow w)\) を使います。辺の重みが正であれば、 \(\mathit{dist}(v)\) には \(s\) から \(v\) への最短路の長さが記録されます。最良優先探索のこのインスタンスは Dijkstra (ダイクストラ) のアルゴリズムとして知られています (が、ここでも厳密に言えば名前は正しくありません)。このアルゴリズムは八章で扱います。
最後に考えるのは、路の幅を路に含まれる辺の重みの最小値と定義し、この幅を優先度とした場合です。Djkstra の最良優先探索アルゴリズムを少しだけ変更したこのアルゴリズムが計算するのは最幅路 (widest path)、またの名をボトルネック最短路 (bottleneck shortest path) です。このアルゴリズムでは印の付く頂点 \(v\) に対して \(\mathit{width}(v)\) という値が記録されます。最初 \(s\) に対しては \(\mathit{width}(s) = \infty\) とし、他の頂点 \(v\) に対しては、\(\mathit{parent}(v) \leftarrow p\) とするときに \(\mathit{width}(v) \leftarrow \min \lbrace \mathit{width}(p), w(p \rightarrow v) \rbrace\) と設定します。そして優先度付きキューに辺 \(v \rightarrow w\) を挿入するときには優先度として \(\min \lbrace \mathit{width}(v), w(v \rightarrow w) \rbrace\) を使います。最幅路は最大フローを計算するときに利用します。最大フローについては (お分かりでしょうが) 十章で扱います。
非連結グラフ
\(\textsc{WhateverFirstSearch}\) は探索を始める \(s\) から到達可能な頂点だけを訪れます。そのため \(G\) の全ての点を訪れるには、次に示す簡単な "ラッパー" 関数が必要になります:
procedure \(\texttt{WFSAll}\)(\(G\))
for 頂点 \(v\) do
\(v\) に印がない状態にする
for 頂点 \(v\) do
if \(v\) に印が付いていない then
\(\texttt{WhateverFirstSearch}\)(\(v\))
あなたが質問するのが聞こえます: 「ちょっと待った。なぜそんな複雑にする必要が? 頂点配列を走査すればそれで終わり12では?」
procedure \(\texttt{MarkEveryVertexDuh}\)(\(G\))
for 頂点 \(v\) do
\(v\) に印をつける
ええ、こうすることもできます。ただしこれができるのは頂点の完全なリストがあるときだけです。グラフの中には頂点の明示的なリストを持たないグラフもあります13。さらに重要なこととして、仮に頂点のリストがあった場合でも、このナイーブなアルゴリズムでは頂点を訪れる順番が "袋" として使われるデータ構造だけで決まってしまい、グラフの抽象的な構造が順番に反映されなくなってしまいます。
具体的に言うと、\(\textsc{WFSAll}\) はまずある成分に含まれる全ての頂点を訪れ、その次に別の成分を訪れる、というふうに全ての成分を調べます。この順番を利用すれば、非連結グラフの成分の数を単純なカウンターを使って数えることができます。これはナイーブなアルゴリズムでは不可能です:
procedure \(\texttt{CountComponents}\)(\(G\))
\(\color{red}{\mathit{count} \leftarrow 0}\)
for 頂点 \(v\) do
\(v\) に印がない状態にする
for 頂点 \(v\) do
if \(v\) に印が付いていない then
\(\color{red}{\mathit{count} \leftarrow \mathit{count} + 1}\)
\(\texttt{WhateverFirstSearch}\)(\(v\))
return \(\color{red}{\mathit{count}}\)
もう少し頑張れば、全ての頂点に印をつける代わりに、全ての頂点がどの成分に属しているかを記録することもできます:
procedure \(\texttt{CountAndLabel}\)(\(G\))
\(\mathit{count} \leftarrow 0\)
for 頂点 \(v\) do
\(v\) に印がない状態にする
for 頂点 \(v\) do
if \(v\) に印が付いていない then
\(\mathit{count} \leftarrow \mathit{count} + 1\)
\(\texttt{LabelOne}\)(\(v, \mathit{count}\))
return \(\mathit{count}\)
⟨⟨属する成分でラベル付けする⟩⟩
procedure \(\texttt{LabelOne}\)(\(s, \mathit{count}\))
袋に \(s\) を入れる
while 袋が空でない do
袋から頂点を取り出して \(v\) とする
if \(v\) に印が付いていない then
\(v\) に印を付ける
\(\color{red}{comp(v) \leftarrow \mathit{count}}\)
for \(vw\) の形をした辺 do
\(w\) を袋に入れる
\(\textsc{WFSAll}\) は全ての頂点に一回ずつ印をつけ、全ての辺を一回ずつ袋に入れ、全ての辺を袋から一回ずつ袋から取り出すので、全体の実行時間は \(O(V + ET)\) です。ここで \(T\) は袋を使った操作の実行時間です。具体的に言うと、深さ優先探索と幅優先探索ではアルゴリズムの実行時間は \(O(V+E)\) であり、\(\textsc{WhateverFirstSearch}\) と同じです。
\(\textsc{WhateverFirstSearch}\) が一つの成分の全域木を計算することから、\(\textsc{WFSAll}\) を使えばグラフの全域森を計算できます。特に、辺の重さを優先度に使う最良優先探索は最小重み全域森を \(O(V + E \log E)\) で計算します。
驚く外ないのですが、少なくとも一つのとても有名なアルゴリズムの教科書には、このラッパー関数を使うことができるのが深さ優先探索だけであると書かれています14。これは完全な間違いです。歴史を見れば、1945 年に Konrad Zuse (コンラート・ツーゼ) がまだ実装の存在しなかったプログラミング言語 Plankalkül (プランカルキュール) で書いた世界初の幅優先探索の実装は、無向グラフの成分を数えてラベル付けするために作られています。
有向グラフ
何か優先探索を有向グラフに適用するのは簡単です。唯一の違いは頂点に印をつけた後に袋に入れるのがその頂点の後者であるという点です。実は、標準的な隣接リストまたは隣接行列を使っているなら、無向グラフに対するアルゴリズムのコードをそのまま有向グラフに使うことができます!
procedure \(\texttt{WhateverFirstSearch}\)(\(s\))
袋に \(s\) を入れる
while 袋が空でない do
袋から頂点を取り出して \(v\) とする
if \(v\) に印が付いていない then
\(v\) に印を付ける
for \(\color{red}{v \rightarrow w}\) の形をした辺 do
\(w\) を袋に入れる
前述の証明により、このアルゴリズムが \(s\) から到達可能な全ての頂点に印をつけること、そして有向辺 \(\mathit{parent}(v) \rightarrow v\) の集合が全ての辺が根 \(s\) から遠ざかる根付き木を定義することが言えます。しかし、仮にグラフが連結だったとしても、グラフの全域木が計算できるとは限りません。有向グラフにおいては到達可能性が対称でないからです。
一方で、\(\textsc{WhateverFirstSearch}\) は \(s\) から到達可能な頂点の全域木なら定義します。さらに "袋" のインスタンスを変えれば、到達可能な頂点に対する深さ優先全域木、幅優先全域木、最小重み全域有向木、最短路木、最幅路木が手に入ります。
グラフへの帰着
塗りつぶし (Flood Fill)
何か優先探索の現代的な例のうち最も古いものの一つは、Edward Moore (エドガー・ムーア) によって 1950 年代中ごろに提案された、ピクセルマップに対する塗りつぶし (flood fill) 演算です。ピクセルマップ (pixel-map) とは各要素が色を表す二次元配列であり、配列の要素は picture elements (画素) を省略してピクセル (pixel) と呼ばれます15。ピクセルマップの連結領域 (connected region) とは同じ色を持つピクセルの連結な部分集合のことです。ここで二つのピクセルが連結であるとは、それらが垂直または平行に隣り合っていることを言います。塗りつぶし演算とは連結領域内の全てのピクセルの色を新しい色に変更する操作であり、多くのラスタグラフィックス編集ソフトウェアでは絵具の缶で表されています。塗りつぶし演算の入力は対象の領域に含まれるピクセルの一つを表す添え字 \(i, j\) と新しい色です。
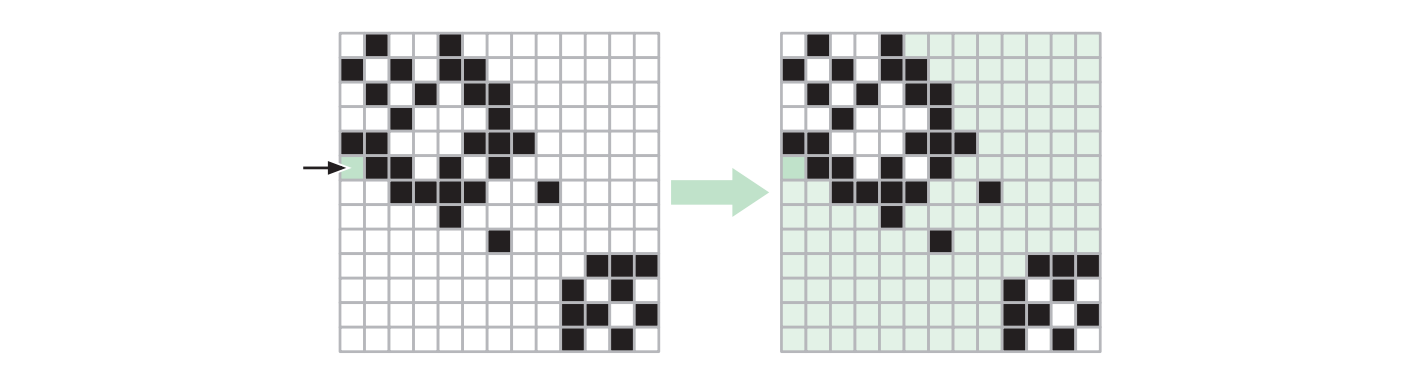
定義を追っていけば塗りつぶし問題を到達可能性問題に帰着させることができます: 頂点が各ピクセルに対応し、色が同じ隣り合うピクセル同士に辺があるような無向グラフを \(G=(V, E)\) とします。ピクセルマップにおける連結領域とは \(G\) における成分なので、塗りつぶし操作は \(G\) における到達可能性問題に帰着されます。この到達可能性問題は \(G\) に対する \((i, j)\) から始まる何か優先探索で解くことができます。ただし探索には少し変更が必要で、頂点に印をつけたときにその頂点の色を変えるようにする必要があります。 \(n \times n\) のピクセルマップに対するグラフ \(G\) には \(n^{2}\) 個の頂点と最大 \(2n^{2}\) の辺があるので、この何か優先探索の実行時間は \(O(V + E) = \pmb{O(n^{2})}\) です。
この単純な例には帰着の重要な要素が示されています。私たちは塗りつぶし問題を最初から解いたのではなく、知っているアルゴリズムをブラックボックスのサブルーチンとして使いました。何か優先探索が実際にどう動くかはこの問題に全く関係なく、関係があるのはその仕様、つまり何か優先探索にグラフ \(G\) と探索を始める頂点 \(s\) を入力すると、\(s\) から到達可能な全ての頂点に印が付くということだけです。ただし入力をどう構築するか、そして出力をどう使うかを説明しなければならない点は他のサブルーチンを使うときと同様です。またアルゴリズムの解析を行うときには、内部で使われるグラフアルゴリズムに対する入力ではなく元の問題への入力を使う必要があります。
ここまで来てアルゴリズムが動くようになったら ――ここで初めて――、アルゴリズムを高速化する最適化を行います。行える最適化は少なくとも二つあり、一つはプログラムによる実装に関するもので、もう一つは理論的な結論に関するものです:
-
プログラムを実装するときには、\(G\) に対応するグラフを表すデータ構造を実際に構築する必要はありません。そうする代わりに、ピクセルマップを標準的な隣接リストだと思ってアルゴリズムを適用できます。これができるのは任意のピクセルに対して同じ色を持つ隣り合うピクセルを \(O(1)\) 時間で列挙できるからです。それから、頂点に "印" をつける代わりに直接ピクセルの色を変えてしまっても問題ありません。
-
さらに注意深く解析を行うと、実行時間が塗りつぶされる領域のピクセル数に比例することが分かります。塗りつぶされる領域のピクセル数 というのは \(G\) において頂点 \((i, j)\) を含む成分の頂点数と同じであり、\(O(n^{2})\) よりも格段に小さくなることがあります。
練習問題
グラフ
-
次の定義が全て同値なことを示してください。
- 木とは連結な非巡回グラフである。
- 木とは一成分からなる森である (森は非巡回グラフ)。
- 木とは辺が \(V-1\) 個以下の連結グラフである。
- 木とは最小連結グラフである: 任意の辺を削除するとグラフが非連結となる。
- 木とは辺が \(V-1\) 個以上の非巡回グラフである。
- 木とは最大非巡回グラフである: 任意の二つの頂点の間に辺を追加すると閉路ができる。
-
\(n>2\) 個の頂点を持つ任意の連結非巡回グラフには少なくとも二つの次数 \(1\) の点が存在することを示してください。 "木" あるいは "葉" という単語、および木のよく知られた性質を使わずに、"連結" と "非巡回" の定義だけを使って示してください。
-
グラフ \((V,E)\) が二部 (bipartite) であるとは、\(V\) を二つの部分集合 \(L, R\) に分割して、全ての辺が \(L\) の点と \(R\) の点を結ぶようにできることを言います。
-
任意の木が二部グラフであることを示してください。
-
グラフ \(G\) が二部であることが、\(G\) に含まれる任意の閉路の長さが偶数なことと同値であると証明してください。
-
与えられた無向グラフが二部かどうかを判定する効率の良いアルゴリズムを説明、解析してください。
-
-
鳩が何羽か一緒になると、本能的につつき順序 (pecking order) を作ります。つまり任意の鳩の組について、必ずどちらかがもう一方をつつくことができ、相手を餌や将来のつがい相手から追い払えるということです。同じ鳩の組は何年も会っていなくても、周りにいる鳩が変わっても同じつつき順序を作ります。興味深いことに、つつき順序は全体として閉路を含むことがあります。例えば鳩 \(i\) が鳩 \(j\) をつつき、鳩 \(j\) が鳩 \(k\) をつつき、鳩 \(k\) が鳩 \(l\) をつついているときに、鳩 \(l\) が鳩 \(i\) をつつくことがあり得ます。
-
任意の数の鳩の集まりは一列に並べて任意の鳩が前にいる鳩の背中をつつけるようにできることを示してください (鳩のパレード?)。どうかお願いします。
-
\(n\) 羽の鳩のつつき関係を表す有向グラフが与えられたとします。つまりグラフの頂点が鳩を表し、鳩 \(i\) が 鳩 \(j\) をつつくときに限って辺 \(i \rightarrow j\) が存在します。(a) で存在が示されたつつき順序を計算するアルゴリズムを説明、解析してください。
-
三羽以上の任意の鳩の集合について、(a) で示されるつつき順序は唯一であるか、そうでなければある三羽の鳩 \(i,j,k\) がいて、鳩 \(i\) が鳩 \(j\) をつつき、鳩 \(j\) が鳩 \(k\) をつつき、鳩 \(k\) が鳩 \(i\) をつついていることを示してください。
-
-
グラフ \(G\) のオイラー周遊 (Eulerian tour) とは、\(G\) の閉じた歩道であって \(G\) の全ての辺をちょうど一回ずつ通るものを言います。
-
連結グラフ \(G\) がオイラー周遊を持つならば \(G\) の全ての頂点が偶数の次数を持つことを示してください (Euler はこれを示しました)。
-
連結グラフ \(G\) の全ての頂点が偶数の次数を持つならば \(G\) はオイラー周遊を持つことを示してください (Euler はこれを示しませんでした)。
-
与えられたグラフのオイラー周遊を計算するか、オイラー周遊が存在しなければ正しくそうだと報告するアルゴリズムを説明、解析してください (Euler がこの問題に対してぼんやりと手を振りました)。
-
-
\(d\) 次元超立方体は次のように定義されます: \(d\) ビットの異なる文字列でラベル付けされた頂点が \(2^{d}\) 個あり、二つの頂点の間に辺があるのは対応する文字列がちょうど一文字違うときだけです。
-
ハミルトン閉路 (Hamiltonian cycle) とは \(G\) の閉路であって \(G\) の頂点を全て通るものを言います。全ての \(d \geq 2\) に対して、\(d\) 次元超立方体に Hamilton 閉路が存在することを示してください。
-
オイラー周遊 (全ての辺を一度ずつ使う閉じた歩道) を持つ超立方体はどれですか? [ヒント: とても簡単です。]
\({}\)
走査アルゴリズム
-
-
有向グラフ \(G\) が強連結 (strongly connected) であるとは、\(G\) に含まれる任意の二つの頂点 \(u, v\) に対して、\(u\) から \(v\) および \(v\) から \(u\) の路が存在することを言います。
無向グラフ \(G\) が与えられ、\(G\) の各辺に向きをつけて有向グラフを作るときに、出来上がるグラフを強連結にできるかどうかを判定するアルゴリズムを説明、解析してください。
-
\(G\) を連結グラフとし、適当な頂点 \(v\) を根とする深さ優先全域木を \(T\) をします。\(v\) を根とする幅優先全域木が \(T\) と等しいならば \(G=T\) であることを示してください。
-
Epprich 教授と Goodstein 教授は一般的な何か優先探索アルゴリズムに対する次に示す最適化を提案しました。袋から取り出した時に頂点に印が付いているかを調べる代わりに、彼らのアルゴリズムは袋に頂点を入れる時にそれを調べます。そのため各頂点は多くとも一回しか袋に入りません。このアルゴリズムでは袋に入れるときに各頂点の親も記録されます。
procedure \(\texttt{EagerWFS}\)(\(s\))
\(s\) に印を付ける
袋に \(s\) を入れる
while 袋が空でない do
袋から頂点を取り出して \(v\) とする
for \(vw\) の形をした辺 do
if \(w\) に印が付いていない then
\(w\) に印を付ける
\(\mathit{parent}(w) \leftarrow v\)
\(w\) を袋に入れる
-
\(\textsc{EagerWFS}(s)\) が \(s\) から到達可能な頂点全てに印をつけ、それ以外の頂点には印をつけないことを示してください。同様に \(\textsc{EagerWFS}(s)\) が計算する親へ向かう辺 \(v \rightarrow \mathit{parent}(v)\) の集合が \(s\) を含む成分の全域木を定義することを示してください。
-
キューを使って袋を実装した場合、\(\textsc{EagerWFS}\) が幅優先探索と等価なことを示してください。つまり、二つのアルゴリズムが同じ頂点を同じ順番で訪れて同じ全域木を作ることを示してください。 [ヒント: キューの定義は何ですか?]
-
どんなデータ構造を袋として使っても (したがってスタックを使っても)、 \(\textsc{EagerWFS}\) が絶対に深さ優先探索と等価にならないことを示してください。
\(\textsc{EagerWFS}\) も \(\textsc{RecursiveDFS}\) も頂点 \(v\) を考えているときの辺 \(vw\) の順番を指定しておらず、辺の順番を変えると最終的な全域木も変わります。したがって証明のためには、具体的なグラフ \(G\) に対して、\(\textsc{RecursiveDFS}\) が作ることができる全ての全域木が \(\textsc{EagerWFS}\) によって作られないこと (あるいはその逆) を示す必要があります。
-
-
一般的なアルゴリズムのクラスとしての何か優先探索を説明した最初期の論文の一つは、自動ガベージコレクタ研究の一環として Edsger Dijkstra (エドガー・ダイクストラ)、Leslie Lamport (レスリー・ランポート)、Alain J.Martin (アラン・J・マーティン)、Carel S. Scholten (キャレル・S・スコルテン)、Elisabeth F. M. Steffens (エリザベス F・M・ステファンズ) らによって 1975 年に発表されました。彼らのアルゴリズムでは頂点に印を付けたり消したりするのではなく、頂点に対する白、灰色、黒のどれかの色を記録します。いつも通り、アルゴリズムは固定されたグラフ \(G\) を仮定します。
procedure \(\texttt{ThreeColorSearch}\)(\(s\))
全ての頂点を白く塗る
\(s\) を灰色に塗る
while 灰色の頂点がある do
\(\texttt{ThreeColorStep}\)()
procedure \(\texttt{ThreeColorStep}\)()
\(v \leftarrow \) 適当な灰色の頂点
if \(v\) に白い隣接点が無い then
\(v\) を黒く塗る
else
\(w \leftarrow v\) の白い隣接点
\(\mathit{parent}(w) \leftarrow v\)
\(w\) を灰色に塗る
-
\(\textsc{ThreeColorSearch}\) の各ステップにおいて、次の不変条件が満たされることを示してください: 「任意の白い頂点に隣接する頂点は黒くない」 [ヒント: 簡単なはずです。]
-
\(\textsc{ThreeColorSearch}(s)\) が停止したとき、\(s\) から到達可能な全ての頂点は黒く塗られていること、到達可能でない全ての頂点は白く塗られていること、親をたどる辺 \(v \rightarrow \mathit{parent}(v)\) の集合が \(s\) を含む成分の根付き全域木を定義することをそれぞれ示してください。
[ヒント: 直感的には黒い頂点が "印の付いた" 頂点であり、灰色の頂点が "袋に入った" 頂点を表します。しかし \(\textsc{WhateverFirstSearch}\) と違って、このアルゴリズムは同じ頂点から出る辺を同じタイミングで処理しません。]
-
次に示す \(\textsc{ThreeColorSearch}\) の変種が深さ優先探索と等価であることを示してください。このアルゴリズムでは灰色の頂点の集合が通常のスタックを使って管理されます。 [ヒント: \(\textsc{ThreeColorStackStep}\) の最後の二行の順番が重要です!]
procedure \(\texttt{ThreeColorStackSearch}\)(\(s\))
全ての頂点を白く塗る
\(s\) を灰色に塗る
\(s\) をスタックにプッシュする
while 灰色の頂点がある do
\(\texttt{ThreeColorStackStep}\)()
procedure \(\texttt{ThreeColorStackStep}\)()
スタックから頂点 \(v\) をポップする
if \(v\) に白い隣接点が無い then
\(v\) を黒く塗る
else
\(w \leftarrow v\) の白い隣接点
\(\mathit{parent}(w) \leftarrow v\)
\(w\) を灰色に塗る
\(v\) をスタックにプッシュする
\(w\) をスタックにプッシュする
-
次に示す \(\textsc{ThreeColorSearch}\) の変種が幅優先探索と等価でないことを示してください。このアルゴリズムでは灰色の頂点の集合が通常のキューを使って管理されます。 [ヒント: \(\textsc{ThreeColorQueueStep}\) の最後の二行の順番は重要ではありません!]
procedure \(\texttt{ThreeColorQueueSearch}\)(\(s\))
全ての頂点を白く塗る
\(s\) を灰色に塗る
\(s\) をキューにプッシュする
while 灰色の頂点がある do
\(\texttt{ThreeColorQueueStep}\)()
procedure \(\texttt{ThreeColorQueueStep}\)()
キューから頂点 \(v\) をプルする
if \(v\) に白い隣接点が無い then
\(v\) を黒く塗る
else
\(w \leftarrow v\) の白い隣接点
\(\mathit{parent}(w) \leftarrow v\)
\(w\) を灰色に塗る
\(v\) をキューにプッシュする
\(w\) をキューにプッシュする
-
❤ \(\textsc{ThreeColorSearch}\) の実行中に他のプロセスが \(G\) に辺を足していくとします。この場合、追加される辺によって (a) で示した不変条件が成り立たなくなる可能性があるので、このアルゴリズムの正しさ ――\(\textsc{ThreeColorSearch}\) が終了したときに \(s\) から到達可能な全ての頂点が黒く塗られていること―― が保証されなくなります。"頂点が白い" が "到達不可能だから削除しても構わない" を意味している場合、これは大問題です。
しかしもし他のプロセスが辺を足すときに色についての不変条件が保たれるように気を付けるならば、他のプロセスによって辺が足されていく場合でも三色アルゴリズムを使って到達不可能な頂点を見つけることができます。二つの並列アルゴリズムを次のようにモデル化します。\(\textsc{GarbageCollect}\) における either/or の選択および \(\textsc{Mutate}\) における \(u\) と \(w\) の選択はメインのアルゴリズムから全く制御できないとしてください16。
procedure \(\texttt{GarbageCollect}\)(\(s\))
全ての頂点を白く塗る
\(s\) を灰色に塗る
while 灰色の頂点がある do
\(\color{red}{either}\)
\(\quad\)\(\texttt{CollectStep}\)()
\(\color{red}{or}\)
\(\quad\) \(\color{red}{\textsc{Mutate}()}\)
procedure \(\texttt{CollectStep}\)()
\(v \leftarrow\) 適当な灰色の頂点
if \(v\) に白い隣接点が無い then
\(v\) を黒く塗る
else
\(w \leftarrow v\) の白い隣接点
\(w\) を灰色に塗る
procedure \(\texttt{Mutate}\)()
\(u \leftarrow\) 任意の頂点
\(w \leftarrow\) 任意の頂点
if \(uw\) が辺でない then
辺 \(uw\) を加える
if \(u\) が黒くて \(w\) が白い then
\(u\) を灰色に塗る
if \(u\) が白くて \(w\) が黒い then
\(w\) を灰色に塗る
\(\textsc{GarbageCollect}\) が確かに必ず終了し、\(s\) から到達可能な全ての頂点を黒く、\(s\) から到達不可能な点を白く塗ることを証明してください。
-
❤ \(\textsc{Mutate}\) における不変条件を保つための処理を変更して、黒い頂点を灰色にする代わりに白い頂点を灰色にするようにしたとします:
procedure \(\texttt{Mutate}\)()
\(u \leftarrow\) 任意の頂点
\(w \leftarrow\) 任意の頂点
if \(uv\) が辺でない then
辺 \(uw\) を加える
if \(u\) が黒くて \(w\) が白い then
\(w\) を灰色に塗る
if \(u\) が白くて \(w\) が黒い then
\(u\) を灰色に塗る
こうした場合でも \(\textsc{GarbageCollect}\) が確かに必ず終了し、\(s\) から到達可能な全ての頂点を黒く、\(s\) から到達不可能な点を白く塗ることを証明してください。
\({}\)
帰着
-
-
数迷路 (number maze) は正の整数が書かれた \(n \times n\) の格子で遊ぶパズルです。駒を左上のマスに置いた状態からゲームがスタートし、ゲームのゴールは駒を左下のマスに動かすことです。ターンごとにあなたは駒を上下左右に動かすことができますが、動かせる距離は現在いるマスに書かれている整数で決まります。例えば駒が 3 と書かれているマスにある場合、動かせるのは 3 マス上、3 マス下、3 マス右、3 マス左のどれかです。ただし駒を盤の外側に動かすことはできません。
与えられた数迷路を解くために必要になる最小の手数を計算するか、パズルに答えが無ければ正しくそうだと報告する効率の良いアルゴリズムを説明、解析してください。例えば次に示す迷路に対するアルゴリズムの答えは整数 \(8\) です。
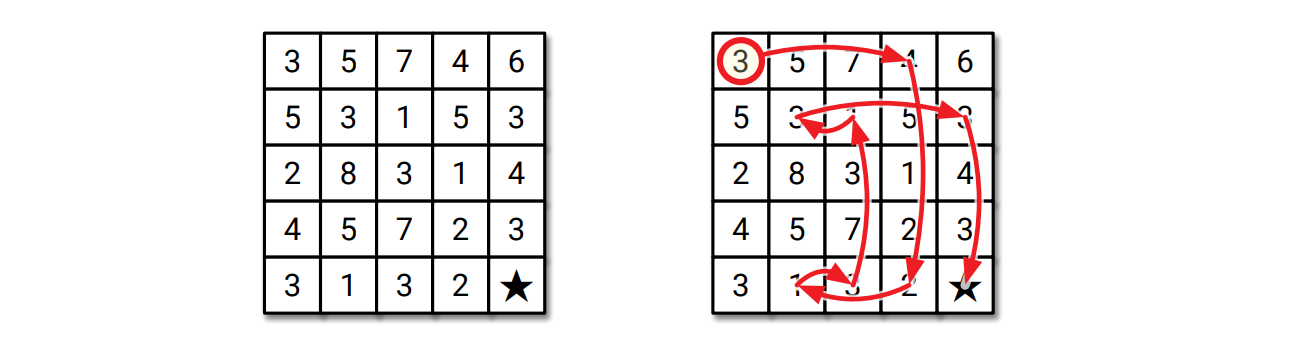 図 5.148 手で解くことができる \(5 \times 5\) の数迷路
図 5.148 手で解くことができる \(5 \times 5\) の数迷路 -
蛇と梯子 (snakes and ladders) は遅くとも 16 世紀にはインドで遊ばれていた古典的なボードゲームです。盤は \(n \times n\) の正方形のマスからなる格子であり、それぞれのマスには \(1\) から \(n^{2}\) までの数字が左下から右に向かって始まる蛇順で書かれており、行が異なる特定の二つのマスの間には「蛇 (戻る)」または「梯子 (進む)」がかかっています。一つのマスは蛇と梯子のどちらかの端点にしかなれません。
駒を左下のマス \(1\) に置いた状態からゲームが始まり、各ターンであなたは駒を最大 \(k\) マス進めることができます。ここで \(k\) は定数です。蛇の上端に止まった駒は蛇の下端まで移動します。同様に梯子の下端に止まった駒は梯子の上端まで移動します。
盤の最後のマスに到達するまでに必要となる最小の手数を計算する効率の良いアルゴリズムを説明、解析してください。
 蛇と梯子の盤 (上向きの直線の矢印が梯子、下向きの曲がった矢印が蛇を表す)
蛇と梯子の盤 (上向きの直線の矢印が梯子、下向きの曲がった矢印が蛇を表す) -
悪名高いモンゴル人パズル戦士 Vidrach Itky Leda は次のパズルを 1473 年に作成しました。パズルの盤は正の整数が書かれた正方形のマスからなる \(n \times n\) の格子であり、駒は赤と青の二種類です。最初二つの駒を左上と右下のマスに置いた状態からスタートし、パズルのゴールは二つの駒の位置を反転させることです。二つの駒が同じマスに止まることはできません。
各ターンにおいて、あなたはどちらかの駒を上下左右に動かすことができ、動かすことができる距離はもう一方の駒がいるマスに書かれている数字によって決まります。例えば赤い駒が 3 と書かれているマスにいる場合、あなたが青い駒を動かすことができるのは 3 マス上、3 マス下、3 マス右、3 マス左のどれかです。ただし駒を盤の外に動かすことはできず、手の終了時に二つの駒が同じマスにいるようにもできません。
与えられた Vidrach Itky Leda パズルを解く最小の手数を計算するか、パズルに答えが無ければ正しくそうだと報告する効率の良いアルゴリズムを説明、解析してください。例えば次の図に示すパズルが与えられたとき、アルゴリズムは \(5\) を返します。
 \(4 \times 4\) の Vidrach Itky Leda パズルに対する解
\(4 \times 4\) の Vidrach Itky Leda パズルに対する解 -
有向グラフ \(G=(V,E)\) と頂点 \(s, t\) が与えられたときに、\(G\) における \(s\) から \(t\) に向かう歩道であって長さが 3 で割り切れるものが存在するかを判定するアルゴリズムを説明、解析してください (同じ辺と頂点を含んでも構いません)。
例えば次のグラフと図中 \(s, t\) で示される頂点が与えられた場合、アルゴリズムの答えは \(\textsc{True}\) です。なぜなら \(s \rightarrow\) \(w \rightarrow\) \(y \rightarrow\) \(x \rightarrow\) \(s \rightarrow\) \(w \rightarrow t\) が \(s\) から \(t\) への長さ 6 の歩道だからです。

-
辺が赤または青に塗られた有向グラフ \(G\) が与えられたとします。\(G\) における頂点 \(s\) から頂点 \(t\) への同じ色の辺が三回以上連続しない歩道の中で最短なものの長さを求めるアルゴリズムを説明してください。つまり、歩道が二回連続して赤い辺を通ったら次の辺は青い必要があり、歩道が二回連続して青い辺を通ったら次の辺は赤い必要があるということです。
例えば次のグラフが入力されたとき、アルゴリズムは \(7\) を返します。なぜなら \(s \color{#B52F1B}{\rightarrow}\) \(a \color{#B52F1B}{\rightarrow}\) \(b \color{#0071BB}{\Rightarrow}\) \(d \color{#B52F1B}{\rightarrow}\) \(c \color{#0071BB}{\Rightarrow}\) \(a \color{#B52F1B}{\rightarrow}\) \(b \color{#B52F1B}{\rightarrow}\) \(t\) が \(s\) から \(t\) への規則を守る最短の歩道だからです。

-
辺が赤、白、青のどれかで塗られた有向グラフ \(G\) が与えられたとします。\(G\) の歩道に含まれる辺の色が赤、白、青、赤、白、青、という順番になっているとき、その歩道をフランス国旗歩道と呼びます。きちんと言うと、歩道 \(v_{0} \rightarrow v_{1} \rightarrow \cdots \rightarrow v_{k}\) がフランス国旗歩道なのは、全ての整数 \(i\) について、辺 \(v_{i} \rightarrow v_{i+1}\) の色が \(i \mod 3 = 0\) ならば赤、\(i \mod 3 = 1\) ならば白、\(i \mod 3 = 2\) ならば青な場合です。
与えられた頂点 \(v\) からフランス国旗歩道で到達可能な \(G\) の頂点を全て求めるアルゴリズムを説明してください。
-
\(n\) 個の銀河を結ぶ \(m\) 個の銀河間テレポートウェイがあります。各テレポートウェイは二つの銀河を結んでいて、双方向に使うことができ、テレポートウェイ \(e\) を使うごとに \(c(e)\) ドルの費用が掛かります。ここで \(c(e)\) は正の整数です。テレポートウェイは複数回使っても構いませんが、使うたびに通行料がかかります。
Judy は銀河 \(s\) から銀河 \(t\) に行こうとしています。テレポーテーションはあまり心地良いものではないので、彼女はテレポーテーションの回数を最小にしたいと思っています。また小さな硬貨を持ち歩くのも煩わしいので、合計費用を 5 ドルの倍数にしたいとも彼女は思っています。
-
Judy が費用を 5 ドルの倍数にしつつ銀河 \(s\) から銀河 \(t\) に行くために必要になるテレポーテーションの最小回数を求めるアルゴリズムを説明、解析してください。
-
Judy が一度だけテレポーテーションを無料にできるクーポンを持っているとして (a) を解いてください。
-
-
Three Shea Shells は連結無向グラフ \(G\) を使って遊ぶ一人用ゲームです。最初三つの駒を異なる頂点 \(a, b, c\) に置いた状態からゲームがスタートします。あなたは各ターンで三つの駒全てを辺に沿って隣接する頂点に動かさなければならず、ターンの終了時には三つの駒が異なる頂点にある必要があります。このゲームのゴールは三つの駒をゴール頂点 \(x, y, z\) に動かすことです。どの駒がどのゴール頂点にあっても構いません。
 図 5.17Three Sea Shells パズルの初期状態と解の最初の4手
図 5.17Three Sea Shells パズルの初期状態と解の最初の4手与えられた Three Sea Shells パズルが解けるかどうかを判定するアルゴリズムを説明、解析してください。アルゴリズムへの入力はグラフ \(G\), スタートの頂点 \(a, b, c\), ゴールの頂点 \(x, y, z\) です。アルゴリズムの出力は \(\textsc{True}\) か \(\textsc{False}\) の 1 ビットです。
-
\(G\) を連結無向グラフとします。2 枚のコインを \(G\) の適当な頂点においた状態から始めて、最小のステップで 2 枚のコインが同じ頂点に来るようにしたいとします。各ステップにおいて、コインは必ず隣接する頂点に移動しなくてはいけません。
-
2 枚のコインが同じ頂点にある構成にたどり着くまでの最小ステップ数を計算するか、そのような構成が不可能ならばそうだと正しく報告するアルゴリズムを説明、解析してください。アルゴリズムの入力はグラフ \(G=(V,E)\) と二つの頂点 \(u, v \in V\) です (\(u, v\) が同じこともあり得ます)。
-
コインが 3 枚だとします。3 枚のコインが同じ頂点にある構成にたどり着くまでの最小ステップ数を計算するか、そのような構成が不可能ならばそうだと正しく報告するアルゴリズムを説明、解析してください。
-
コインが 42 枚だとします。42 枚のコインが同じ頂点にある構成にたどり着くまでの最小ステップ数を計算するか、そのような構成が不可能ならばそうだと正しく報告するアルゴリズムを説明、解析してください。もう一度言いますが、42 枚の全てのコインがステップごとに移動する必要があります。満点のためには、アルゴリズムの実行時間が \(O(V + E)\) であることが求められます。
-
-
私の娘が通う小学校で使っている算数の練習帳17には、次のタイプのパズルがいくつか載っています:
鋭角だけが含まれる線で Start と Finish をつなぎましょう。

この鋭角迷路を解くアルゴリズムを説明、解析してください。
アルゴリズムには連結無向グラフ \(G\) が与えられ、頂点が平面上の点に、辺が線分に対応します。辺は端点以外の点で交わりません。例えば X の形をした迷路には 5 個の頂点と 4 個の辺が含まれ、上図左の迷路には 18 個の頂点と 21 個の辺が含まれます。アルゴリズムには二つの頂点 \(\textsc{Start}\) と \(\textsc{Finish}\) も与えられます。
アルゴリズムが \(\textsc{True}\) を返すのは \(G\) に含まれる \(\textsc{Start}\) から \(\textsc{Finish}\) への歩道で鋭角だけを含む物が存在するときで、それ以外の場合は \(\textsc{False}\) を返します。きちんと言うと、\(G\) に含まれる歩道が条件を満たすのは、歩道に含まれる任意の連続する二辺 \(u \rightarrow v \rightarrow w\) について \(\angle uvw = \pi\) または \(\angle uvw < \pi / 2\) なときです。辺を二つ受け取ってそれらが直線か、鈍角か、鋭角かを \(O(1)\) 時間で判定するサブルーチンを使えると仮定してください。
-
平面上の \(n\) 個の垂直および水平な線分と二つの点 \(s, t\) が与えられたときに、線分に触れることなく \(s\) から \(t\) まで移動できるかを判定する効率の良いアルゴリズムを説明してください。
水平な線分は左右の \(x\) 座標と共通の \(y\) 座標で与えられ、どの水平な線分も異なる \(y\) 座標を持ちます。同様に垂直な線分は上下の \(y\) 座標と共通の \(x\) 座標で与えられ、どの垂直な線分も異なる \(x\) 座標を持ちます。そして点 \(s, t\) は \(x, y\) 座標で与えられます。
 図 5.18水平および垂直な線分からなる迷路内の二点を結ぶパス
図 5.18水平および垂直な線分からなる迷路内の二点を結ぶパス -
安っぽいロマンス映画にはこんなシーンがあります: 長い間引き離されていたロマンチックなカップルが突然遠くにいるお互いを見つけ、目線を離すことなくゆっくりと歩み寄り、音楽が始まり、雨はやみ、太陽が雲の間から差し込み、音楽が盛り上がり、みんなが踊り始め、虹も子猫もチョコレートのユニコーンも加わって、そして...18
ロマンチックなカップルのことを情報科学の偉大な伝統に従って Alice と Bob と呼ぶことにします。二人はお気に入りの公園に東西の入口から入ってきて、すぐにお互いを視認しました。しかし二人は一直線に近づくことができず、公園の東西の入口から延びるジグザグな歩道を通って近づかなければなりません。加えてドラマチックな緊張感を保つために、Alice と Bob が歩道を歩いている間、二人は常に東西方向の同一直線上にいなければなりません。
ジグザグな歩道の曲がり角の \(x, y\) 座標が \(X[0..n]\) と \(Y[0..n]\) で表されていて、南西から北東に向かう方向が正方向とします。配列 \(X\) は昇順にソートされていて、\(Y[0] = Y[n]\) であり、歩道の曲がり角同士は直線で結ばれているとします。
-
\(Y[0] = Y[n] = 0\) かつ他の全ての添え字 \(i\) について \(Y[i] > 0\) と仮定します。つまり、歩道の端点が他の部分よりも厳密に下にあるということです。この条件が成り立つ歩道では Alice と Bob が必ず会えるということを示してください。 [ヒント: 歩道の上を歩くカップルが存在できる場所をモデル化するグラフを作ってください。このグラフの頂点は何ですか? 辺は? 証明には次の握手補題を使ってください: 「任意のグラフにおいて、次数が奇数である頂点は偶数個ある」]
 図 5.19Alice と Bob が出会う様子 (Alice はステップ 2 で後ろに下がり、Bob は ステップ 5 と 6 で後ろに下がっている)
図 5.19Alice と Bob が出会う様子 (Alice はステップ 2 で後ろに下がり、Bob は ステップ 5 と 6 で後ろに下がっている) -
歩道の端点が他の曲がり角よりも下にないときでも Alice と Bob が会えることがありますが、会えないこともあります。与えられた配列 \(X[0..n]\) と \(Y[0..n]\) で表される歩道において、Alice と Bob が互いに東西方向の目線を逸らすことなく、歩道の上を通って会えるかどうかを判定するアルゴリズムを説明してください。
-
❤ (b) に対するアルゴリズムで実行時間が \(O(n)\) なものを説明してください。
-
-
有名なパズル作成者 Kaniel the Dane は二つの駒と \(n \times n\) の正方形のマスからなる格子を使って遊ぶ一人用ゲームを発明しました。\(n^{2}\) 個のマスのうちいくつかのマスは障害物マスで、ちょうど一つのマスがゴールマスです。各ターンでプレイヤーは一つの駒を上下左右に動かしますが、そのときにはできる限り遠くまで動かします。つまり、(1) 盤の端にぶつかる (2) 障害物マスにぶつかる (3) もう一方の駒にぶつかる まで進むということです。二つの駒のどちらかをゴールマスまで移動させるのがゲームの目標です。
 図 5.206 手で解くことができる Kaniel the Dane のパズル (円が駒の初期位置を、黒いマスが障害物マスを、中央のマスがゴールマスを表す)
図 5.206 手で解くことができる Kaniel the Dane のパズル (円が駒の初期位置を、黒いマスが障害物マスを、中央のマスがゴールマスを表す)例えば、上図のパズルを解くにはまず赤い駒を下に障害物マスにぶつかるまで動かし、その次に緑色の駒を左に赤い駒にぶつかるまで動かし、その後赤い駒を左、下、右、上と動かします。緑色の駒がゴールのすぐ上にあるので、この動きによって赤い駒はゴールマスに止まり、ゲームクリアとなります。
パズルのインスタンスが解けるかどうかを判定するアルゴリズムを説明、解析してください。アルゴリズムの入力は整数 \(n\) と障害物マスの座標のリストと二つの駒の初期位置です。出力は一つの真偽値です: 与えられたパズルが解を持つなら \(\textsc{True}\) で、そうでないなら \(\textsc{False}\) です。 [ヒント: 問題を解くグラフを構築するのに必要な時間を忘れないでください。]
-
❤長方形歩 (rectangle walk) は新作の抽象的パズルゲームであり、たった 99 セント購入できます。対応プラットフォームは Steam, iOS, Android, Xbox One, Playstation 5, Nintendo Wii U, Atari 2600, Palm Pilot, Commodore 64, TRS-80, Sinclair ZX-1, DEC PDP-8, PLATO, Zuse Z3, Duramesc, Odhner Arithmometer, Analytical Engine, Jacquard Loom, Horologium Mirabile Lundense, Leibniz Stepped Reckoner, Al-Jazari's Robot Band, Yan Shi's Automaton, Antikythera Mechanism, Knotted Rope, Ishango Bone, Pile of Rocks です。
このゲームは \(n \times n\) の黒と白のマスからなる格子を使って遊びます。プレイヤーは次のルールに従ってこの格子の上で長方形を動かします:
- 長方形は格子とアラインされる。つまり、長方形の上下左右の座標は整数でなければならない。
- 長方形は \(n \times n\) よりも小さく、かつ一つ以上のマスを含まなければならない。
- 長方形は黒いマスを含んではならない。
-
プレイヤーの持っている長方形を \(r\) としたときに、プレイヤーは一回の手で \(r\) を \(r\) に含まれる長方形または \(r\) を含む長方形に変えることができる。
初期状態において、プレイヤーは盤の左上隅に大きさが \(1 \times 1\) の長方形を持っています。プレイヤーの目標はなるべく少ない手で持っている長方形を右下の隅の \(1 \times 1\) の長方形に変えることです。
 図 5.21長方形歩の最初の 5 手
図 5.21長方形歩の最初の 5 手与えられたビットマップにおける長方形歩の最小解の長さを計算するアルゴリズムを説明、解析してください。アルゴリズムの入力は配列 \(M[1..n, 1..n]\) であり、\(M[i,j] = 1\) が黒いマスを、\(M[i,j] = 0\) が白いマスを表します。合法な長方形歩の存在、および \(M[1,1] = M[n,n] = 0\) を仮定して構いません。例えば上図のビットマップに対するアルゴリズムの答えは整数 18 です。 [ヒント: 問題を解くグラフを構築するのにかかる時間を忘れないこと!]
-
Racetrack (またの名を Graph Racers, Vector Rally) は紙とペンがあれば遊べる二人対戦のゲームで、Jeff は五年生の時にスクールバスの中で遊びました19。このゲームでは方眼紙の上に書いたコースに沿って二人のプレイヤーが順番に車を動かします。このときのルールは以下の通りです。
方眼紙の一部にスタートエリアとフィニッシュエリアが設定されており、二人のプレイヤーはスタートエリアの好きな場所に車を置いた状態でゲームを始めます。車には \(x\) 座標と \(y\) 座標で表される位置 (position) と速度 (velocity) があり、ゲームの開始したときの速度は \((0,0)\) です。各ステップにおいて、プレイヤーは速度の片方または両方の成分を \(1\) 増やすか減らすことができます。つまり、速度の各成分を最大 \(1\) だけ変えられるということです。車の位置はこの新しい速度を現在の位置に足すことで計算されます。新しい位置はコースの内側でなければなりません。もしコースの外側に行ってしまった場合、車はクラッシュしてそのプレイヤーの負けです。どちらかの車がフィニッシュエリアのどこかについたらゲームは終了で、その車を操るプレイヤーの勝ちです。
 図 5.22\(25 \times 25\) の Racetrack コースに対する 16 ステップの走行 (これはこのコースに対する最小ステップの走行ではない)
図 5.22\(25 \times 25\) の Racetrack コースに対する 16 ステップの走行 (これはこのコースに対する最小ステップの走行ではない)Racetrack のコースが \(n \times n\) のビットの配列で、0 がコースを、1 がコース外を表し、スタートエリアは最初の列、フィニッシュエリアは最後の列であるとします。与えられたコースに対して、スタートエリアからフィニッシュエリアまで行くための最小ステップ数を計算するアルゴリズムを説明、解析してください。
-
サイコロ転がし迷路 (rolling die maze) は通常の六面サイコロ (各面に数字の書かれた立方体) と正方形のマスからなるグリッドを使うパズルです。サイコロは必ず一つのマスの上にあり、あなたは各ステップにおいてサイコロを底面の辺に沿って 90 度回転できます。これによってサイコロは隣接する東西南北のマスのどれかに移動します。
マスの中にはブロックされたマスが存在し、サイコロはブロックされたマスの上に乗ることができません。また数字の書かれたマスもあり、サイコロがこのマスに乗るにはサイコロの一番上の数字がマスに書かれた数字と同じである必要があります。ブロックされておらず数字も書かれていないマスのことをフリーであると言います。またグリッドの外側にサイコロを転がすことはできません。サイコロ転がし迷路が解を持つとは、左下にサイコロを置いた状態からルールに従ってサイコロを転がしていってサイコロを右上のマスに乗せることができることを言います。
 図 5.23サイコロ転がし迷路
図 5.23サイコロ転がし迷路次の図に四つのサイコロ転がし迷路を示します。1 と 6 が反対側にある標準的なサイコロを使った場合、解があるのは左の二つだけです。
 図 5.24四つのサイコロ転がし迷路 (左の二つだけが解を持つ)
図 5.24四つのサイコロ転がし迷路 (左の二つだけが解を持つ)-
二次元配列 \(L[1..n, 1..n]\) が与えられ、各要素 \(L[i,j]\) が \(i\) 行 \(j\) 列のマスのラベル (0 ならフリー、-1 ならブロックされている、正の整数ならその数字が書いてある) を表しているとします。サイコロ転がし迷路が解を持つかどうかを多項式時間で判定するアルゴリズムを説明、解析してください。
-
❤ 迷路がマスのラベルのリストで陰に定義されるとします。つまり、入力は迷路の大きさを表す整数 \(M\) とマスのラベルを表す \(S[i..n]\) であり、\(S[i] = (x, y, L)\) が \((x, y)\) のマスのラベルが \(L\) であることを表すとします。前問と同様に、マスのラベルが -1 ならばそのマスはブロックされています。ただし、フリーのマスが \(S\) に含まれない点が前問と異なります。与えられたサイコロ転がし迷路が解を持つかどうかを判定するアルゴリズムを説明、解析してください。満点のためには、アルゴリズムは入力サイズ \(n\) の多項式時間で実行できる必要があります。
[ヒント: サイコロの初期状態には自由度がありますが、初期状態を正しく選んだ場合にのみ解けるサイコロ転がしパズルが存在します。]
-
-
❤ 辺が赤または青に塗られた有向グラフ \(G\) と二つの頂点 \(s, t\) が与えられたとします。
-
\(s\) から \(t\) への路であって赤い辺と青い辺のパターンが回文になっているものを計算するか、そのような路が無ければそうだと正しく報告するアルゴリズムを説明してください。
-
\(s\) から \(t\) への赤い辺と青い辺のパターンが回文になっている路の中で最短のものを計算するか、そのような路が無ければそうだと正しく報告するアルゴリズムを説明してください。
[ヒント: 最後に回文が出てきたのはどこでしたか? ]
-
-
♠ ❤ ドラフツ (draughts) は明るい色と暗い色で交互に塗られた \(m \times m\) の格子盤20を使って遊ぶゲームで、米国では「チェッカー (checkers)」という名前で知られています。通常は \(8 \times 8\) または \(10 \times 10\) の盤を使いますが、ゲームのルールは他の大きさの盤にも簡単に一般化できます。黒いマスには (米国ではチェッカーと呼ばれる) 駒が最大一つ置かれ、白いマスには何も置かれません。駒は黒と白があります。一人のプレイヤーは白い駒を動かし、もう一方のプレイヤーは黒い駒を動かします。自分の色の駒が全て盤から取り除かれたらそのプレイヤーの負けです。
米国のチェッカー、英国のドラフツをもとにした次のゲームを考えます。このゲームでは全ての駒がキング21であり、四つある対角線方向の任意の方向に駒を進めることができます。各ターンで、プレイヤーは一つの駒を対角線に沿って一つ離れた空のマスに動かすか、あるいは一つの駒で連続ジャンプを行います。一回のジャンプを行うと、駒は対角線方向に二つ離れたマスに移動します。ただしジャンプが行えるのは飛び越える途中のマスに他の色の駒があるときだけです。そしてこの相手の駒は倒され、すぐにゲームから取り除かれます。一ターンで行う連続ジャンプは全て同じ駒が行わなければいけません。
白い駒のプレイヤーが一ターンで黒い駒を全て取って勝利できるかどうかを判定するアルゴリズムを説明してください。アルゴリズムの入力は盤の幅 \(m\) と白い駒の位置のリスト、黒い駒の位置のリストです。満点のためには、 \(n\) を全体の駒の数としたときアルゴリズムの実行時間が \(O(n)\) であることが求められます。
[ヒント: 貪欲な戦術 ――何もできなくなるまで適当なジャンプを繰り返す―― は相手の駒を全て取る連続ジャンプが存在する場合にもそれを見つけられないことがあります。練習問題 5.5 を見てください。パリティ、パリティ、パリティ。]
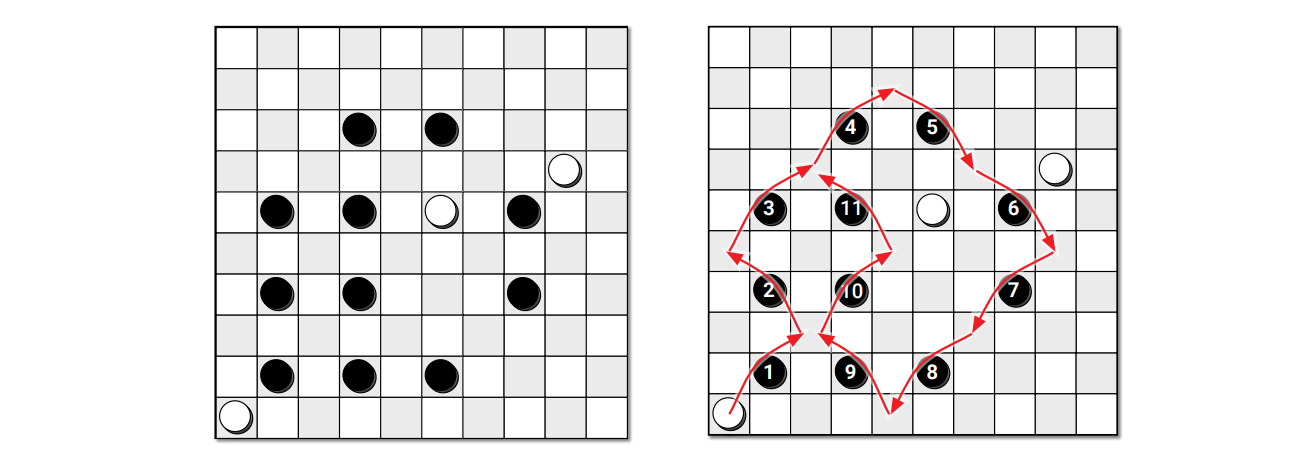 図 5.25白が一ターンで勝つ
図 5.25白が一ターンで勝つ 図 5.26両方の状態において、白は一ターンで勝てない
図 5.26両方の状態において、白は一ターンで勝てない
-
ソース: https://commons.wikimedia.org/wiki/File:Tabula_Peutingeriana_-_Miller.jpg (CC0)[return]
-
十一世紀と十二世紀にかけて、結婚の制限は姻戚関係を通じて適用されるようになりました。最初は結婚による姻戚関係だけが考慮されましたが、後になって婚外性交渉や婚約、そして名づけ親関係さえも考慮されるようになりました。例えばある男とその姉妹の夫の姉妹の夫の姉妹との結婚は正式に禁止されていました。また男やもめとその息子の妻の親である未亡人との結婚も同じく禁止でした。1215 年の改定でこの姻戚関係に関する制限は大きく緩和されましたが、削除はされませんでした。教会が姻戚関係 ex copula illicita という概念を捨て去ったのはようやく 1917 年のことです。[return]
-
ソース: https://www.flickr.com/photos/yalelawlibrary/sets/72157621954683764 (© Yale Law Library, CC BY 2.0)[return]
-
ソース: https://archive.org/details/A077240124/page/n261 (Biblioteca de la Universidad de Sevilla, パブリックドメイン)[return]
-
Euler は議論の最後のステップ ――全ての頂点の次数が偶数であるグラフのオイラー路を実際に求めること―― を明らかだとして省略しています。またグラフがオイラー路を持つにはグラフが連結である必要があることにも Euler は気付いていませんでした。グラフがオイラー路を持つこととグラフが連結で全ての頂点が偶数であることが同値である証明を最初にきちんと示したのは Carl Hierholzer であり、1873 年のことです。[return]
-
頂点を表す英単語の複数系は "vertices" であり、その単数形が "vertex" です。同様に "martices" の単数形は "matrix"、"indices" の単数形は "index" です。イタリア語を使っていない限り、次の単語は存在しません: vertice, matrice, indice, appendice, helice, apice, vortice, radice, simplice, codice, directrice, dominatrice, Unice, Kleenice, Asterice, Obelice, Dogmatice, Getafice, Cacofonice, Vitalstatistice, Geriatrice, Jimi Hendrice! もしこの規則を覚えられないなら、常に "node" を使ってください。[return]
-
成分のことを連結成分 (connected component) と呼ぶことがありますが、これは冗長です。定義により成分は連結だからです。[return]
-
紛らわしいことに、埋め込み (embedding) という言葉が辺が交わる埋め込みに対して、描画と同じ意味で使われることがあります。あなたはこのようなことをしないでください。[return]
-
細かいことに目が行く学生は、隣接リストが本当はリストでないことに気が付くかもしれません。この命名は薫製ニシンの虚偽の例といえます: 情報科学では、数学と同じように、赤いニシン (red herring) が赤い必要はありませんし、魚である必要もありません。[return]
-
これを実際に行うには想像よりもはるかに微妙な技法が必要になります。よく知られたハッシュ技法のほとんどは高速なクエリ時間を保証しておらず、良いとされるハッシュ法でも \(O(1)\) 時間の期待値を持つにすぎないものが多くあるからです。ハッシュに関する議論は http://algorithms.wtf/ を参照してください。[return]
-
"expected amortized" の意味が分からなくても気にしないでください。[return]
-
この言葉 ("just") はほとんど常に、あなたが何か重要なことを見落としていることを示します。[return]
-
一方で、各頂点に印が付いた時刻を記録するようにすれば、"全ての頂点の印を消す" という操作は走査を開始するときに時間を更新することで頂点の数に関係なく \(O(1)\) で行えます。この場合頂点に "印が付いている" ことはその頂点に記録された時刻が走査の開始時間よりも遅いことで表されます。[return]
-
直接引用すれば: "Unlike breadth-first search, whose predecessor subgraph forms a tree, the predecessor subgraph produced by a depth-first search may be composed of several trees, because the search may repeat from multiple sources." (幅優先探索では前者部分グラフが木を形成する。これに対して、深さ優先探索の前者をたどるグラフは複数の木を形成できる。深さ優先探索は複数の異なる成分に属する頂点を始点として行えるからである)[return]
-
1960年代に現代的なラスターディスプレイが発明されるまで、画素は「ピクセル」ではなく「スティッチ (stitche)」あるいは「テッセラ (tessera)」という名前で呼ばれていました。 "pix" という単語が "picture(s)" の短縮系になったのは 20 世紀初頭 ―― "sock" の複数系が "sox" になってから間もないころ―― であり、それまでの口語 "piccy" を置き換えました。このような単語の他の例としては voxel (volume element), texel (texture element), taxel (tactile element / badger) などがあります。[return]
-
これは Lua や Go などのマルチスレッドプログラミング言語で実際に使われている "mark and sweep" ガベージコレクトアルゴリズムを大幅に単純化したものです。マルチスレッドの動的メモリ管理についてのさらに詳細な議論は残念ながらこの本の範囲を超えますが、第一の掟だけは書いておきます: 汝、自分で書いたガベージコレクタを走らせるなかれ。[return]
-
Jason Batterson and Shannon Rogers, Beast Academy Math: Practice 3A, 2012. これ以外の例は https://www.beastacademy.com/resources/printables.php を参照してください。[return]
-
豆知識: Whiplash と La La Land を監督した Damien Chazelle は、プリンストン大学の情報科学の教授で電子ギタリストでもある Bernard Chazelle の息子です。[return]
-
実際のゲームはここに説明したものよりもう少し複雑です。素晴らしいオンラインバージョンが http://harmmade.com/vectorracer/ にあります。[return]
-
中世の英国で政府会計士が計算に使っていたテーブル (counting table) は黒い正方形のチェッカー (chequer) 模様が入った緑色の布で覆われていて、その正方形の上に円形のカウンターをおいて値を表しました。このため、十世紀以降の英国では政府会計士を Exchequer と呼びます。この counting table は徴税計算の道具として Exchequer によって使われ続け、十九世紀になっても使われていました。[return]
-
ドラフツの他の変種のほとんどには "空飛ぶキング" がいます。このキングは英国/米国バージョンのキングと大きく異なった振る舞いをするので、問題がとても難しくなります。この問題は12 章で見ます。[return]