練習問題
ここにあげられた練習問題を解くときには ――さらに言えば動的計画法を使うアルゴリズムを新しく作るときにはどんなときでも――、 以前に示したステップを踏むことを強く勧めます。特に、準備が完了するまでは表や for ループについて考え始めないでください。ここで言う準備とは、実際に解くことになる再帰的な小問題の英語で書かれた明解な仕様と、それを使った元の問題に対する完全な解のことです1。 まず動くようにせよ。それから速くせよ。
列/配列
-
あなたの前世は南極大陸植民地 Nadiria 州で働くレジ係で、一日の大半を客にお釣りを渡す仕事に費やしていました2。南極では紙がとても貴重で高価なので、レジ係がお釣りを渡すときにはなるべく少ない紙幣を使わなければならないと法律で定められていました。植民地の創立者の一人が数秘術的な嗜好を持っていたおかげで、夢ドル (dream dollar) と呼ばれる Nadira で流通する紙幣は $1, $4, $7, $13, $28, $52, $91, $365 という金額です。
-
♠ この問題に対する貪欲なアルゴリズムは、残りのお釣りの金額を超えない最大の紙幣を返していくというものです。例えば、 $122 に対して貪欲なアルゴリズムを適用すると、$91, $28, $1 とお釣りを渡すことになります。この貪欲なアルゴリズムを使うと理想的な枚数よりも多くの夢ドル紙幣を渡してしまう例を示してください。 [ヒント: 手で解くよりもプログラムを書いた方が早いかもしれません。]
-
整数 \(k\) が与えられたときに、\(k\) 夢ドルのお釣りを返すのに必要となる最小の紙幣の枚数を返す再帰的なアルゴリズムを説明してください (アルゴリズムの実行速度は気にしないでください: まずは正しくしてください)。
-
整数 \(k\) が与えられたときに、\(k\) 夢ドルのお釣りを返すのに必要となる最小の紙幣の枚数を返す動的計画法のアルゴリズムを説明してください (ここでは、アルゴリズムが高速であることが求められます)。
-
-
次にあげる文字列分割問題の変種を解く効率の良いアルゴリズムを説明してください。文字列を受けとってそれが "単語" である場合に限って \(\textsc{True}\) を返すサブルーチン \(\textsc{IsWord}\) が使えると仮定し、アルゴリズムの解析では \(\textsc{IsWord}\) の呼び出し回数の上限を求めてください。
-
文字列 \(A[1..n]\) が与えられたときに、\(A\) を単語の並びに分割する方法の数を求める。例えば、\(\color{maroon}{\texttt{ARTISTOIL}}\) という文字列は \(\color{maroon}{\texttt{ARTIST} \cdot \texttt{OIL}}\) と \(\color{maroon}{\texttt{ART} \cdot \texttt{IS} \cdot \texttt{TOIL}}\) に分割できるので、アルゴリズムはこの文字列に対して \(2\) を返す。
-
二つの文字列 \(A[1..n]\) と \(B[1..n]\) が与えられたときに、同じ添え字を使って \(A\) と \(B\) を単語の列に分割できるかどうかを判定する。例えば \(\color{maroon} \texttt{BOTH} \)\( \color{maroon} \texttt{EART} \)\( \color{maroon} \texttt{HAND} \)\( \color{maroon} \texttt{SATU} \)\( \color{maroon} \texttt{RNSPIN}\) と \(\color{maroon} \texttt{PINS} \)\( \color{maroon} \texttt{TART} \)\( \color{maroon} \texttt{RAPS} \)\( \color{maroon} \texttt{ANDR} \)\( \color{maroon} \texttt{AGSLAP} \) は次のように同じ添え字を使って単語の列に分割できるので、アルゴリズムは \(\textsc{True}\) を返す。 \[ \begin{gathered} \color{maroon}{\texttt{BOT} \cdot \texttt{HEART} \cdot \texttt{HAND} \cdot \texttt{SAT} \cdot \texttt{URNS} \cdot \texttt{PIN}} \\ \color{maroon}{\texttt{PIN} \cdot \texttt{START} \cdot \texttt{RAPS} \cdot \texttt{AND} \cdot \texttt{RAGS} \cdot \texttt{LAP}} \end{gathered} \]
-
二つの文字列 \(A[1..n]\) と \(B[1..n]\) が与えられたときに、同じ添え字を使って \(A\) と \(B\) 両方を単語の列に分割する方法の数を計算する。
-
-
配列 \(A[1..n]\) が与えられたとします。 \(A\) の要素は正、負、またはゼロの数であり、整数であるとは限りません。
-
連続する部分列 \(A[i..j]\) の和の最大値を求めるアルゴリズムを説明、解析してください。
-
連続する部分列 \(A[i..j]\) の積の最大値を求めるアルゴリズムを説明、解析してください。
例えば入力として配列 \([-6, 12, -7, 9, 14, -7, 5]\) が与えられたとき、一つ目の問題に対するアルゴリズムは 19 を返し、二つ目の問題に対するアルゴリズムは 504 を返します。

また、入力として一つの要素からなる配列 \([-374]\) が与えられたとき、一つ目の問題に対する答えのアルゴリズムは \(0\) を返し、二つ目の問題に対する答えのアルゴリズムは \(1\) を返します (空配列も部分列です!)。解析においては比較、加算、乗算演算の実行時間が \(O(1)\) であると仮定して構いません。
[ヒント: (a) は少なくとも 1980 年代中頃から使われている標準的な情報科学の面接試験の問題です。ウェブには回答がたくさん載っていますし、この問題に対する Wikipedia のページだってあります!しかし 2016 年時点では、ウェブで見つかる (b) に対する答えの大部分が、実行時間が最良のものより遅かったり、そもそも正しい答えを計算していなかったりします。]
-
-
この問題では前問の最大部分列問題の変種を考えます。全ての問題で入力は任意の実数の配列 \(A[1..n]\) であり、いくつかの問題では \(X \geq 0\) も入力に含まれます。
-
回り込み: \(A\) が環状 (circular) 配列だとします。この設定では "連続する部分列" が \(A[i..j]\) および \(A[i..n] \cdot A[1..j]\) を意味します。 \(A\) の連続する部分列の和の最大値を求めるアルゴリズムを説明、解析してください。
-
長い部分列だけ: 長さが \(X\) 以上の連続する部分列 \(A[i..j]\) の和の最大値を求めるアルゴリズムを説明、解析してください。
-
短い部分列だけ: 長さが \(X\) 以下の連続する部分列 \(A[i..j]\) の和の最大値を求めるアルゴリズムを説明、解析してください。
-
ザ・プライス・イズ・ライト: 和が \(X\) 以下の連続する部分列 \(A[i..j]\) の和の最大値を求めるアルゴリズムを説明、解析してください。
-
\(A\) の要素が非負であると仮定したときに、前問のアルゴリズムを高速化してください。
-
-
この問題では様々な種類の最適な部分列を見つける効率の良いアルゴリズムを作ってもらいます。部分列とは列からいくつかの要素を削除し、残った要素の順序を保ったまま並べたときに得られる列のことです。部分列の要素は元の列で連続している必要はありません。例えば \(\color{maroon}{\texttt{C}}\), \(\color{maroon}{\texttt{DAMN}}\), \(\color{maroon}{\texttt{YAIOAI}}\), \(\color{maroon}{\texttt{DYNAMICPROGRAMMING}}\) はみな \(\color{maroon}{\texttt{DYNAMICPROGRAMMING}}\) の部分列です。
[ヒント: 貪欲なアルゴリズムを使って \(O(n)\) 時間で解ける問題は一つだけです。]
-
\(A[1..m]\) と \(B[1..n]\) を任意の配列とします。 \(A\) と \(B\) の共通部分列 (common subsequence) とは、\(A\) の部分列でもあり \(B\) の部分列でもあるような配列を言います。 \(A\) と \(B\) の最長共通部分列の長さを計算する効率の良いアルゴリズムを説明してください。
-
\(A[1..m]\) と \(B[1..n]\) を任意の配列とします。 \(A\) と \(B\) の共通超配列 (common supersequence) とは、\(A\) と \(B\) の両方を部分列として含む配列のことを言います。 \(A\) と \(B\) の最短共通超配列の長さを計算する効率の良いアルゴリズムを説明してください。
-
配列 \(X[1..n]\) がバイトニック (bitonic) であるとは、ある添え字 \(i\ (1 < i < n)\) が存在して、接頭部分 \(X[1..i]\) が増加列で接尾部分 \(X[i..n]\) が減少列となること言います。与えられた整数の配列 \(A\) の最長バイトニック部分列の長さを計算する効率の良いアルゴリズムを説明してください。
-
配列 \(X[1..n]\) が振動している (oscillating) とは、全ての偶数 \(i\) について \(X[i] < X[i + 1]\) であり、全ての奇数 \(i\) について \(X[i] > X[i+1]\) であることを言います。与えられた整数の配列 \(A\) の最長振動部分列の長さを計算する効率の良いアルゴリズムを説明してください。
-
与えられた整数の配列 \(A\) の最短振動超配列の長さを計算する効率の良いアルゴリズムを説明してください。
-
配列 \(X[1..n]\) が凸 (convex) であるとは、全ての \(i\) について \(2 \cdot X[i] <\) \(X[i - 1] + X[i + 1]\) が成り立つことを言います。与えられた整数の配列 \(A\) の最長凸部分列の長さを計算する効率の良いアルゴリズムを説明してください。
-
\(X[1..n]\) が弱増加 (weakly increasing) であるとは、全ての要素が前二つの要素の平均よりも大きい、つまり全ての\(i>2\) について \(2 \cdot X[i] > X[i-1] + X[i-2]\) であることを言います。与えられた整数の配列 \(A\) の最長弱増加部分列の長さを計算する効率の良いアルゴリズムを説明してください。
-
\(X[1..n]\) が二重増加 (double increasing) であるとは、全ての \(i > 2\) に対して \(X[i] > X[i-2]\) が成り立つことを言います (言い換えれば、二重増加な配列とは二つの増加列を互い違いに並べたものです)。与えられた整数の配列 \(A\) の最長二重増加部分列の長さを計算する効率の良いアルゴリズムを説明してください。
-
\(X[1..n]\) が増加 (increasing) 列であるとは、全ての \(i\) について \(X[i] < X[i+1]\) であることを言いました。二つの整数配列が与えられたときに、最長共通増加部分列を計算する効率の良いアルゴリズムを説明してください。例えば \(\langle 3,\) \(1, \) \(4, \) \(1, \) \(5, \) \(9, \) \(2, \) \(6, \) \(5, \) \(3, \) \(5, \) \(8, \) \(9, \) \(7, \) \(9, \) \(3 \rangle\) と \(\langle 1, \) \(4, \) \(1, \) \(4, \) \(2, \) \(1, \) \(3, \) \(5, \) \(6, \) \(2, \) \(3, \) \(7, \) \(3, \) \(0, \) \(9, \) \(5 \rangle\) の最長共通増加部分列は \(\langle 1, \) \(4, \) \(5, \) \(6, \) \(7, \) \(9 \rangle\) です。
-
-
二つの文字列 \(X, Y\) のシャッフル (shuffle) とは、それぞれの文字を順番を保ったまま一つの文字列に合成したものを言います。例えば \(\color{maroon}{\texttt{BANANAANANAS}}\) は \(\color{#0071BB}{\texttt{BANANA}}\) と \(\color{maroon}{\texttt{ANANAS}}\) のシャッフルであり、考えられる組み合わせ方は何種類かあります: \[ \color{#0071BB}{\texttt{BANANA}}\color{maroon}{\texttt{ANANAS}} \quad \color{#0071BB}{\texttt{BAN}}\color{maroon}{\texttt{ANA}} \color{#0071BB}{\texttt{ANA}}\color{maroon}{\texttt{NAS}} \quad \color{#0071BB}{\texttt{B}}\color{maroon}{\texttt{AN}} \color{#0071BB}{\texttt{AN}}\color{maroon}{\texttt{A}} \color{#0071BB}{\texttt{A}}\color{maroon}{\texttt{NA}} \color{#0071BB}{\texttt{NA}}\color{maroon}{\texttt{S}} \] 同様に、\(\color{maroon}{\texttt{PRODGYRNAMAMMIINCG}}\) と \(\color{maroon}{\texttt{DYPRONGARMAMMICING}}\) はどちらも \(\color{#0071BB}{\texttt{DYNAMIC}}\) と \(\color{maroon}{\texttt{PROGRAMMING}}\) のシャッフルです: \[ \color{maroon}{\texttt{PRO}} \color{#0071BB}{\texttt{D}} \color{maroon}{\texttt{G}} \color{#0071BB}{\texttt{Y}} \color{maroon}{\texttt{R}} \color{#0071BB}{\texttt{NAM}} \color{maroon}{\texttt{AMMI}} \color{#0071BB}{\texttt{I}} \color{maroon}{\texttt{N}} \color{#0071BB}{\texttt{C}} \color{maroon}{\texttt{G}} \quad \color{#0071BB}{\texttt{DY}} \color{maroon}{\texttt{PRO}} \color{#0071BB}{\texttt{N}} \color{maroon}{\texttt{G}} \color{#0071BB}{\texttt{A}} \color{maroon}{\texttt{R}} \color{#0071BB}{\texttt{M}} \color{maroon}{\texttt{AMM}} \color{#0071BB}{\texttt{IC}} \color{maroon}{\texttt{ING}} \]
-
三つの文字列 \(A[1..m], B[1..n], C[1..m+n]\) が与えられたときに、\(C\) が \(A\) と \(B\) のシャッフルであるかどうかを判定するアルゴリズムを説明、解析してください。
-
\(X\) と \(Y\) の滑らか (smooth) なシャッフルとは、両方の文字列について文字が三つ以上連続して使われることがないシャッフルのことを言います。例えば:
- \(\color{maroon}{\texttt{PR}} \color{#0071BB}{\texttt{D}} \color{maroon}{\texttt{O}} \color{#0071BB}{\texttt{Y}} \color{maroon}{\texttt{G}} \color{#0071BB}{\texttt{NA}} \color{maroon}{\texttt{RA}} \color{#0071BB}{\texttt{M}} \color{maroon}{\texttt{MM}} \color{#0071BB}{\texttt{I}} \color{maroon}{\texttt{I}} \color{#0071BB}{\texttt{C}} \color{maroon}{\texttt{NG}}\) は \(\color{#0071BB}{\texttt{DYNAMIC}}\) と \(\color{maroon}{\texttt{PROGRAMMING}}\) の滑らかなシャッフルです。
- \(\color{#0071BB}{\texttt{DY}} \color{maroon}{\texttt{PR}} \color{#0071BB}{\texttt{N}} \color{maroon}{\texttt{OGR}} \color{#0071BB}{\texttt{A}} \color{maroon}{\texttt{A}} \color{#0071BB}{\texttt{M}} \color{maroon}{\texttt{MM}} \color{#0071BB}{\texttt{IC}} \color{maroon}{\texttt{ING}}\) は \(\color{#0071BB}{\texttt{DYNAMIC}}\) と \(\color{maroon}{\texttt{PROGRAMMING}}\) の滑らかなシャッフルではありません (三文字以上が連続した文字列 \(\color{maroon}{\texttt{OGR}}\) と \(\color{maroon}{\texttt{ING}}\) があるからです)。
- \(\color{#0071BB}{\texttt{XX}} \color{maroon}{\texttt{X}} \color{#0071BB}{\texttt{X}} \color{maroon}{\texttt{X}} \color{#0071BB}{\texttt{X}} \color{maroon}{\texttt{XX}} \color{#0071BB}{\texttt{XX}} \color{maroon}{\texttt{XX}} \color{#0071BB}{\texttt{XX}} \color{maroon}{\texttt{X}} \color{#0071BB}{\texttt{X}} \color{maroon}{\texttt{X}} \color{#0071BB}{\texttt{XX}}\) は \(\color{#0071BB}{\texttt{XXXXXXXXXXX}}\) と \(\color{maroon}{\texttt{XXXXXXXX}}\) の滑らかなシャッフルです。
- \(\color{#0071BB}{\texttt{XXXX}}\) と \(\color{maroon}{\texttt{XXXXXXXXXXXX}}\) の滑らかなシャッフルは存在しません。
三つの文字列 \(X[1..m], Y[1..n], Z[1..m+n]\) が与えられたときに、\(Z\) が \(X\) と \(Y\) の滑らかなシャッフルであるかどうかを判定するアルゴリズムを説明、解析してください。
-
-
この問題では入力を \(X[1..k], Y[i..n]\) (\(k \leq n\)) とします。
-
\(X\) が \(Y\) の部分列であるかを判定するアルゴリズムを説明、解析してください。例えば文字列 \(\color{maroon}{\texttt{PPAP}}\) は文字列 \(\color{#0071BB}{\texttt{P}} \color{maroon}{\texttt{EN}} \color{#0071BB}{\texttt{P}} \color{maroon}{\texttt{INE}} \color{#0071BB}{\texttt{A}} \color{maroon}{\texttt{PPLEAPPLE}} \color{#0071BB}{\texttt{P}} \color{maroon}{\texttt{EN}}\) の部分列です。
-
\(Y\) から要素を取り除いて \(X\) を \(Y\) の部分列でなくなるようにするとき、取り除かなくてはならない最小の要素数を求めるアルゴリズムを説明、解析してください。同じことですが、\(X\) の超配列でない \(Y\) の部分列のうち最長のものを求めるアルゴリズムを考えても良いです。例えば \(\color{maroon}{\texttt{PENPINE}} \color{#0071BB}{\texttt{A}} \color{maroon}{\texttt{PPLE}} \color{#0071BB}{\texttt{A}} \color{maroon}{\texttt{PPLEPEN}}\) から \(\color{#0071BB}{\texttt{AA}}\)を取り除いた文字列は \(\color{maroon}{\texttt{PPAP}}\) を部分列として持ちません。
-
❤ \(Y\) の互いに重ならない二つの部分列の両方に \(X\) が含まれることがあるかを判定するアルゴリズムを説明、解析してください。例えば \(\color{maroon}{\texttt{PPAP}}\) は \(\color{#0071BB}{\texttt{P}} \color{maroon}{\texttt{EN}} \color{#0071BB}{\texttt{P}} \color{maroon}{\texttt{INE}} \color{#0071BB}{\texttt{A}} \color{green}{\texttt{PP}} \color{maroon}{\texttt{LE}} \color{green}{\texttt{A}} \color{#0071BB}{\texttt{P}} \color{maroon}{\texttt{PLE}} \color{green}{\texttt{P}} \color{maroon}{\texttt{EN}}\) の二つの互いに重ならない部分列に含まれます。
-
追加の入力として実数の配列 \(C[1..n]\) が与えられ、\(C[i]\) が \(Y[i]\) のコストを表すとします。 \(Y\) の部分列 \(X\) のうちコストが最小のものを計算するアルゴリズムを説明、解析してください。つまり、全ての \(j\) に対して \(I[j] < I[j+1]\) かつ \(X[j] = Y[I[j]]\) となるような \(I[1..k]\) のうち、コスト \(\sum_{j=1}^{k}C[I[j]]\) が最小になるものを求めるアルゴリズムです。
-
\(Y\) の部分列に \(X\) がいくつあるか計算するアルゴリズムを説明、解析してください。カウントする部分列どうしは重なっていても構いません。解析をするときには任意の桁の二つの整数の足し算が \(O(1)\) 時間でできると仮定して構いません。例えば \(\color{maroon}{\texttt{PPAP}}\) は \(\color{maroon}{\texttt{PENPINEAPPLEAPPLEPEN}}\) の中にちょうど 23 個あります。また \(X\) と \(Y\) の文字が全て同じ場合、答えは \(\binom{n}{k}\) です。
-
\(l\) 桁の数の加算演算が \(O(l)\) 時間かかるとして、(e) のアルゴリズムの実行時間を求めてください。
-
-
入力された文字列 \(T[1..n]\) の連続する部分文字列で、逆順にしたものもまた \(T\) の連続する部分文字列であるもののうち最長なものの長さを求める効率の良いアルゴリズムを説明、解析してください。正順と逆順の文字列は重なってはいけません。例えば:
-
入力が \(\color{maroon}{\texttt{ALGORITHM}}\) の場合、答えは \(0\) です。
-
入力が \(\color{maroon}{\underline{\texttt{R}} \texttt{ECU} \underline{\texttt{R}} \texttt{SION}}\) の場合、条件を満たす部分文字列 \(\color{maroon}{\texttt{R}}\) があるので、 答えは \(1\) です。
-
入力が \(\color{maroon}{\texttt{R} \underline{\texttt{EDI}} \texttt{V} \underline{\texttt{IDE}}}\) の場合、条件を満たす部分文字列 \(\color{maroon}{\texttt{EDI}}\) があるので、答えは \(3\) です。答えとなる部分文字列とその逆順は重なってはいけないことに注意してください。
-
入力が \(\color{maroon}\texttt{D} \underline{\texttt{YNAM}}\)\(\color{maroon} \texttt{ICPROGRAMMING}\)\(\color{maroon}\underline{\texttt{MANY}} \texttt{TIMES}\) の場合、条件を満たす部分文字列 \(\color{maroon}{\texttt{YNAM}}\) があるので、答えは \(4\) です。文字列 \(\color{maroon}{\texttt{YNAMIR}}\) は連続していないので条件を満たしません。
-
-
回文 (palindrome) とは左から読んでも右から読んでも同じになる文字列のことを言います。例えば \(\color{maroon}{\texttt{I}}\), \(\color{maroon}{\texttt{DEED}}\), \(\color{maroon}\texttt{RACECAR}\), \(\color{maroon}\texttt{AMANAPL}\)\(\color{maroon}\texttt{ANACATACA}\)\(\color{maroon}\texttt{NALPANAMA}\) は全て回文です。
-
与えられた文字列の最長回文部分列の長さを求める効率の良いアルゴリズムを説明、解析してください。例えば文字列 \(\texttt{{\color{#0071BB}M}{\color{maroon}A}{\color{#0071BB}H}{\color{maroon}D}}\)\(\texttt{{\color{#0071BB}Y}{\color{maroon}NA}{\color{#0071BB}M}{\color{maroon}ICP}}\)\(\texttt{{\color{#0071BB}RO}{\color{maroon}G}{\color{#0071BB}R}}\)\(\texttt{{\color{maroon}AMZLET}{\color{#0071BB}M}}\)\(\texttt{{\color{maroon}ESHOW}{\color{#0071BB}Y}{\color{maroon}OUT}}\)\(\texttt{{\color{#0071BB}H}{\color{maroon}E}{\color{#0071BB}M}}\) の最長回文部分列は \({\color{#0071BB}\texttt{MHYMRORMYHM}}\) なので、アルゴリズムの答は \(11\) です。
-
与えられた文字列の最短回文超配列の長さを求める効率の良いアルゴリズムを説明、解析してください。例えば \(\color{#0071BB}{\texttt{TEWNTYONE}}\) の最短回文超配列は \(\texttt{{\color{#0071BB}TWENT}{\color{maroon}O}{\color{#0071BB}YO}{\color{maroon}T}{\color{#0071BB}NE}{\color{maroon}WT}}\) なので、アルゴリズムの答は \(13\) です。
-
任意の文字列は回文の列に分解できます。例えば文字列 \(\color{maroon}{\texttt{BUBB}}\)\(\color{maroon}{\texttt{ASEES}}\)\(\color{maroon}{\texttt{ABANANA}}\) ("Bubba sees a banana") は次のように分解できます (分解の仕方はこの他に \(65\) 通りあります): \[ \begin{gathered} \color{maroon}{\texttt{BUB}} \cdot \color{maroon}{\texttt{BASEESAB}} \cdot \color{maroon}{\texttt{ANANA}} \\ \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{U}} \cdot \color{maroon}{\texttt{BB}} \cdot \color{maroon}{\texttt{ASEESA}} \cdot \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{ANANA}} \\ \color{maroon}{\texttt{BUB}} \cdot \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{A}} \cdot \color{maroon}{\texttt{SEES}} \cdot \color{maroon}{\texttt{ABA}} \cdot \color{maroon}{\texttt{N}} \cdot \color{maroon}{\texttt{ANA}} \\ \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{U}} \cdot \color{maroon}{\texttt{BB}} \cdot \color{maroon}{\texttt{A}} \cdot \color{maroon}{\texttt{S}} \cdot \color{maroon}{\texttt{EE}} \cdot \color{maroon}{\texttt{S}} \cdot \color{maroon}{\texttt{A}} \cdot \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{A}} \cdot \color{maroon}{\texttt{NAN}} \cdot \color{maroon}{\texttt{A}} \\ \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{U}} \cdot \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{A}} \cdot \color{maroon}{\texttt{S}} \cdot \color{maroon}{\texttt{E}} \cdot \color{maroon}{\texttt{E}} \cdot \color{maroon}{\texttt{S}} \cdot \color{maroon}{\texttt{A}} \cdot \color{maroon}{\texttt{B}} \cdot \color{maroon}{\texttt{A}} \cdot \color{maroon}{\texttt{N}} \cdot \color{maroon}{\texttt{A}} \cdot \color{maroon}{\texttt{N}} \cdot \color{maroon}{\texttt{A}} \end{gathered} \] 与えられた文字列を回文に分解するときに、最低でも必要となる回文の数を計算する効率の良いアルゴリズムを説明、解析してください。例えば \(\color{maroon}{\texttt{BUBBASEESABANANA}}\) に対するアルゴリズムの答えは \(3\) です。
-
与えられた文字列をなるべく長い回文を使って分解するときに、使うことになる最短の回文の長さの最大値を求める効率の良いアルゴリズムを説明、解析してください。例えば:
-
入力 \(\color{maroon}{\texttt{PALINDROME}}\) に対する出力は \(1\) です。
-
入力 \(\color{maroon}{\texttt{BUBBASEESABANANA}}\) に対する出力は、\(\color{maroon}{\texttt{BUB}} \cdot \color{maroon}{\texttt{BASEESAB}} \cdot \color{maroon}{\texttt{ANANA}}\) に対応する \(3\) です。
-
同じ文字が \(n\) 個並んだ文字列に対する出力は \(n\) です。
-
-
与えられた文字列を回文に分解する方法が何通りあるかを計算する効率の良いアルゴリズムを説明、解析してください。例えば:
-
入力 \(\color{maroon}{\texttt{PALINDROME}}\) に対する出力は \(1\) です。
-
入力 \(\color{maroon}{\texttt{BUBBASEESABANANA}}\) に対する出力は \(70\) です。
-
同じ文字が \(n\) 個並んだ文字列に対する出力は \(2^{n-1}\) です。
-
-
❤ ある文字列に対するメタ回文 (metapalindrome) とは、その文字列の回文への分解であって、分解した回文の長さからなる列も回文になっているものを言います。例えば \[ \color{maroon}{\texttt{BOB}} \cdot \color{maroon}{\texttt{S}} \cdot \color{maroon}{\texttt{MAM}} \cdot \color{maroon}{\texttt{ASEESA}} \cdot \color{maroon}{\texttt{UKU}} \cdot \color{maroon}{\texttt{L}} \cdot \color{maroon}{\texttt{ELE}} \] はメタ回文です。なぜなら \(\color{maroon}{\texttt{BOBSMAMASEESAUKULELE}}\) の回文への分解であり、回文の長さからなる列 \((3,1,3,6,3,1,3)\) が回文だからです。与えられた文字列に対する最短のメタ回文の長さを求める効率の良いアルゴリズムを説明、解析してください。例えば入力 \(\color{maroon}{\texttt{BOBSMAMASEESAUKULELE}}\) に対するアルゴリズムの出力は \(7\) です。
-
-
正の整数の配列 \(A[1..n]\) が与えられたとします。 \(A\) の前後増加部分列 (increasing back-and-forth subsequence) とは、添え字の配列 \(I[1..l]\) であって次の条件を満たすものを言います:
- 任意の \(j\) について \(1 \leq I[j] \leq n\)
- 任意の \(j\) について \(A[I[j]] < A[I[j+1]]\)
- \(I[j]\) が偶数ならば \(I[j+1] > I[j]\)
- \(I[j]\) が奇数ならば \(I[j+1] < I[j]\)
もう少し崩して言うと、次のようになります: 正の整数が入った \(n\) 個の箱が一列に並んでいるとします。一つの箱を選び、それが奇数番目の箱なら今の箱より左にある箱のなかで今よりも大きい数の入ったものに移動し、偶数番目の箱なら今の箱より右にある箱のなかで今よりも大きい数の入ったものに移動します。この移動を繰り返したときの添え字の列が前後増加部分列です。
与えられた \(n\) 要素の配列の最長前後増加部分列の長さを求める効率の良いアルゴリズムを説明、解析してください。例えば

という配列が入力されたとき、アルゴリズムは次の前後増加部分列に対応する \(9\) を答えます:

-
一段落の英語の文章を紙上に (どうしてもと言うなら、コンピューターのスクリーン上に) 組版したいとします。段落には \(n\) 個の単語が含まれ、\(i\) 番目の単語の長さは \(l[i]\) だとします。この単語列を長さがちょうど \(L\) の行に分割することが目標です。
段落がどのように行に分割されるかに応じて、単語間の空白の幅を調整しなければなりません。なぜなら段落は両端揃えである、つまり各行の右端の余白と段落の最初を除いた各行の左端の余白が揃っている必要があるからです。また同じ行にある単語の間には一単位以上の空白が必要です。
段落のレイアウトのあふれ (slop) を次のように定義します: 最後の行を除く各行について、その行に含まれる "追加の" 空白の数、つまり実際に含まれる空白の数からその行にある単語の間の数を引いたもの、の三乗を求め、その和を段落のレイアウトのあふれとします。式で書くと、\(i\) 番目の単語から \(j\) 番目の単語が含まれる行のあふれは \((L - j + i - \sum_{k=i}^{j} l[k])^{3}\) と定義されます。あふれが最小となるように段落を印刷する動的計画法のアルゴリズムを説明してください。
-
あなたは 8 才の甥 Elmo と単純なゲームを遊ぶことになりました。このゲームはカードを一列に並べた状態から始まり、あなたと Elmo は順番に左端または右端からカードを取っていきます。カードがなくなった時点でゲームは終了で、持っているカードのポイントの和が大きい方が勝ちです。
Elmo はアルゴリズムの講義を取ったことがないので、常に選択できる二枚のカードのうち大きな方を選択するという、単純な貪欲戦術を使います。この問題の目標は可能な場合には必ず Elmo に勝利する戦略を見つけることです (子供をこんな風に負かすのは大人げないかもしれませんが、 Elmo は手を抜いた大人に勝たせてもらうのが大嫌いです) 。
-
あなたは貪欲な戦略を使うべきでないことを示してください。つまり、貪欲な戦略に従わなかった場合にのみ勝てるゲームがあることを示してください。
-
与えられたカードの初期状態について、Elmo を相手に勝負をしたときに集められる最高得点を計算するアルゴリズムを説明、解析してください。
-
♣ Elmo が 4 才のときに使っていた戦略はもっと単純で、両端のカードのどちらかを一様ランダムに選ぶというものでした。つまり、彼のターンが回ってきたときに二つのカードが残っているならば、左端のカードを \(\frac{1}{2}\) の確率で、右端のカードを \(\frac{1}{2}\) の確率で選ぶということです。与えられたカードの初期状態について、4 才の Elmo を相手に勝負したときに集められる得点の期待値の最大値を計算するアルゴリズムを説明してください。
-
5 年後、 13 才になった Elmo は格段に強い完璧なプレイヤーになりました。与えられたカードの初期状態について、完璧な相手と勝負したときに集められる最高得点を計算するアルゴリズムを説明、解析してください。
-
-
あなたの flippin' sweet なダンスのスキルを見せつけるときが迫ってきました!明日大きなダンス大会があり、あなたはその大会のために人生をかけて準備をしてきました (アラスカで伯父とクズリ狩りをしていた時間は除く)。あなたは \(n\) 人の審査員それぞれがコンテストでかける \(n\) 曲を時系列順に並べたリストを前もって手に入れることに成功しました。 Yesssssssssss!
あなたは全ての曲と審査員と自分のダンスの上手さについてとてもよく理解しているので、 任意の \(k\) について \(k\) 番目の曲を踊った場合の点数が \(\mathit{Score}[k]\) であることを知っています。また \(\mathit{Score}[k]\) 点を獲得するために \(k\) 番目の曲を踊った場合、疲れてしまうので次の \(\mathit{Wait}[k]\) 曲では踊ることができません (\(k+1\) 番目の曲から \(k+\mathit{Wait}[k]\) 番目までの曲で踊れないということです)。合計点数が一番大きいダンサーがコンテストで優勝するので、あなたは合計点数はなるべく高くしたいと思っています。
取得できる最高得点を計算する効率の良いアルゴリズムを説明、解析してください。あなたの sweet なアルゴリズムに対する入力は配列の組 \(\mathit{Score}[1..n]\), \(\mathit{Wait}[1..n]\) です。
-
新作のスワップパズルゲーム Candy Swap Saga XIII には \(1\) から \(n\) までの数字がついた \(n\) 匹のかわいい動物が出てきます。この動物達は circus peanuts, Heath bars, Cioccolateria Gardini chocolate truffles という三つのアメのうちどれか一つを持っています。あなたは最初 circus peanut を持っている状態でゲームが始まります。
あなたは動物を \(1\) から \(n\) まで順番に訪ね、動物とアメを交換することでポイントを獲得していきます:
-
自分の持っているアメと同じ種類のアメと交換したとき、ポイントを獲得する。
-
自分の持っているアメと違う種類のアメと交換したとき、ポイントを失う (ポイントは負になりうる)。
-
交換をしなかった場合、ポイントは変わらない。
あなたは \(n\) 匹の動物を順番通りに訪れなくてはならず、一度訪れた動物を再び訪れることはできません。
獲得可能な最高得点を計算する効率の良いアルゴリズムを説明、解析してください。アルゴリズムに対する入力は \(C[1..n]\) であり、\(C[i]\) が \(i\) 番目の動物が持っているアメの種類を表します。
-
-
新設される Maksymilian R. Levchin 情報科学大学に学部長として着任することになっている Lenny Rutenbar は、 Orchard Donws そりゲレンデの南コースに3小さな雪のジャンプ台をいくつか作らせ、電子計算工学科の学科長 Bill Kudeki にそり対決を申し入れました。Bill と Lenny はコースをそりで滑り降り、滞空距離を競います。勝者は Siebel Center と新設の ECE 棟を学部/学科のものにできますが、敗者は学部/学科全体を Loomis Lab の隣にある Boneyard 排水渠に移動させなければなりません。
Lenny および Bill がジャンプ台に差し掛かったときに地上にいるなら、ジャンプ台を使ってジャンプをするか通り過ぎるかを選択できます。当然ジャンプ台は滞空時には使えないので、ジャンプをした場合には以降のジャンプ台をいくつか見逃す可能性があります。
-
配列の組 \(\mathit{Ramp}[1..n]\) と \(\mathit{Length}[1..n]\) が与えられ、\(\mathit{Ramp}[i]\) が頂上から \(i\) 番目のジャンプ台までの距離を表し、\(\mathit{Length}[i]\) が \(i\) 番目のジャンプ台でジャンプしたそりが滞空する距離を表すとします。Lenny または Bill の最大滞空距離を計算するアルゴリズムを説明、解析してください。
-
Lenny と Bill の小さな賭け事について耳にした大学の弁護士はこの対決について異議を唱えました。とどまることを知らない保険料率と訴訟から大学を守るために、弁護士は二人がジャンプできる回数に上限を設けました。前問の \(\mathit{Ramp}[1..n]\) と \(\mathit{Length}[1..n]\) に加えて \(k\) が与えられ、ジャンプが最大 \(k\) 回しか許されていない場合に、Lenny または Bill の最大滞空距離を計算するアルゴリズムを説明、解析してください。
-
❤ ジャンプの回数に上限を設けても対決が取りやめにならなかったのを見て、弁護士はさらなる制限を加えました: どのジャンプ台も一度しか使われてはいけないというのです!法律の干渉にうんざりした Lenny と Bill は賭けを諦め、その代わり協力して観客が楽しめる滑りをすることを決めました。前問の設定に加えて二人が同じジャンプ台を使えないとしたときに、二人の滞空距離の和の最大値を求めるアルゴリズムを説明、解析してください。
-
-
農家の Boggis, Bunce, Bean は Mr. Fox のために障害物コースをこしらえました。コースは一列に並んだブースでできており、各ブースには明るい赤で番号が書いてあります。きちんと言うと、Mr. Fox には実数の配列 \(A[1..n]\) が与えられ、\(A[i]\) が \(i\) 個目のブースに書かれた番号を表します。 三人の農家と Mr. Fox は次のルールに従います:
-
Mr. Fox はブースに入るたびに "Ring!" と "Ding!" のどちらかを必ず言う。
-
\(i\) 番目のブースで "Ring!" と言った場合、\(A[i]\) 個のチキンを得る ( \(A[i] < 0\) のときは \(-\ A[i]\) 個のチキンを失う)。
-
\(i\) 番目のブースで "Ding!" と言った場合、\(A[i]\) 個のチキンを失う ( \(A[i] < 0\) のときは \(-\ A[i]\) 個のチキンを得る)。
-
Mr. Fox は四つのブース連続で同じ単語を言うことはできない。例えば 6, 7, 8 番目のブースで "Ring!" と言ったなら、9 番目のブースでは "Ding!" と言わなければならない。
-
獲得したチキンの清算は全てのブースを訪れ、審判が "Hot box!" と言った後に行われる。Mr. Fox は障害物コースをチキンをもって回る必要はない。
-
Mr. Fox がルールを破った場合、あるいは障害物コースを完走した時点で農家にチキンの貸しがある場合、農家は Mr. Fox を銃で撃つ。
与えられる配列 \(A[1..n]\) で表される障害物コースを走ったときに Mr. Fox が獲得できるチキンの数の最大値を計算するアルゴリズムを説明、解析してください。 [ヒント: 燃えた松ぼっくりに注意!]
-
-
ダンスダンスレボリューション (Dance Dance Revolution) は日本のゲーム会社コナミによって 1998 年に制作されたダンスゲームです。プレイヤーは上下左右の矢印が足元に書かれた舞台に立ち、ゲーム画面下から上に流れる矢印 (\(\leftarrow, \uparrow, \downarrow, \rightarrow\)) が画面の一番上に来た時にタイミングよくステップを踏むというゲームです (矢印は画面の一番上に来たときにちょうど曲の拍に合うように流れてきます)。
このゲームの変種 "Vogue Vogue Revolution" の目標は、動きを最小限にしつつ完璧にプレイすることです。矢印が画面の一番上に来たときに足が元々その矢印の上にあるなら、体を動かさずに済むことに対して \(1\) スタイルポイントが与えられます。もし踏まなければならない矢印に両方の足が無い場合は、ちょうど一つの足をその矢印の場所に移動させます。間違った矢印に足を動かした場合、正しい矢印を踏めなかった場合、足が正しい位置にあるのに足を動かした場合にはスタイルポイントを全て失ってゲームオーバーとなります。
どうすればスタイルポイントを最大化できるでしょうか? この問題ではスタート時点で左足は \(\leftarrow\) に、右足は \(\rightarrow\) にあり、 プレイヤーは流れてくる矢印を完全に記憶しているとします。例えば \(\uparrow \uparrow \downarrow \downarrow \leftarrow \rightarrow \leftarrow \rightarrow\) に対しては、次のようなステップで \(5\) スタイルポイントを獲得できます。

-
任意の \(n\) 個の矢印の列に対して、 少なくとも \(n/4 - 1\) スタイルポイントを獲得できることを示してください。
-
VVR の譜面に対して獲得可能な最大のスタイルポイントを計算する効率の良いアルゴリズムを説明してください。入力は矢印の向きの配列 \(\mathit{Arrow}[1..n]\) です。
-
-
次の一人遊びのスクラブルを考えます。ゲームはアルファベットと数字が書かれたタイルの有限列をテーブルの上に置いた状態で始まり、ゲームの開始とともにプレイヤーはタイル列から最初の七つのタイルを手札に加えます。各ターンで、プレイヤーは手札のタイルの一部もしくは全部を使って英単語を作り、そのタイルに書かれている数字だけ点数を獲得します (手札から英単語を作れないならそこでゲーム終了です)。英単語を作った後は次の条件のいずれかが成り立つまでタイルをタイル列から手札に加えます (a) 手札が七枚になる (b) タイル列が空になる (ダブル/トリプルワードやビンゴ、ブランク、パスはありません)。目標はなるべく多くの得点を獲得することです。
例えば、次の 20 個のタイルからなるタイル列を考えます: \[ | {\color{maroon}{\texttt{I}}_{2}} | {\color{maroon}{\texttt{N}}_{2}} | {\color{maroon}{\texttt{X}}_{8}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{N}}_{2}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{D}}_{3}} | {\color{maroon}{\texttt{U}}_{5}} | {\color{maroon}{\texttt{D}}_{3}} | {\color{maroon}{\texttt{I}}_{2}} | {\color{maroon}{\texttt{D}}_{3}} | {\color{maroon}{\texttt{K}}_{8}} | {\color{maroon}{\texttt{U}}_{5}} | {\color{maroon}{\texttt{B}}_{4}} | {\color{maroon}{\texttt{L}}_{2}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{K}}_{8}} | {\color{maroon}{\texttt{H}}_{5}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{N}}_{2}} | \] このタイル列からゲームを開始した場合、次のようにすると 68 点を獲得できます。
- 手札が \(|{\color{maroon}{\texttt{I}}_{2}} | {\color{maroon}{\texttt{N}}_{2}} | {\color{maroon}{\texttt{X}}_{8}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{N}}_{2}} | {\color{maroon}{\texttt{A}}_{1}} | \color{maroon}{\texttt{D}}_{3} |\) と初期化される。
- \(|{\color{maroon}{\texttt{N}}_{2}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{I}}_{2}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{D}}_{3}} |\) を出して 9 点を得る。手札には \(|{\color{maroon}{\texttt{N}}_{2}} | {\color{maroon}{\texttt{X}}_{8}} |\) が残る。
- 次の 5 枚のタイル \(|{\color{maroon}{\texttt{U}}_{5}} | {\color{maroon}{\texttt{D}}_{3}} | {\color{maroon}{\texttt{I}}_{2}} | {\color{maroon}{\texttt{D}}_{3}} | {\color{maroon}{\texttt{K}}_{8}} |\) を手札に加える。
- \(|{\color{maroon}{\texttt{U}}_{5}} | {\color{maroon}{\texttt{N}}_{2}} | {\color{maroon}{\texttt{D}}_{3}} | {\color{maroon}{\texttt{I}}_{2}} | {\color{maroon}{\texttt{D}}_{3}} |\) を出して 15 点を得る。手札には \(|{\color{maroon}{\texttt{K}}_{8}} | {\color{maroon}{\texttt{X}}_{8}} |\) が残る。
- 次の 5 枚のタイル \(|{\color{maroon}{\texttt{U}}_{5}} | {\color{maroon}{\texttt{B}}_{4}} | {\color{maroon}{\texttt{L}}_{2}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{K}}_{8}} |\) を手札に加える。
- \(|{\color{maroon}{\texttt{B}}_{4}} | {\color{maroon}{\texttt{U}}_{5}} | {\color{maroon}{\texttt{L}}_{2}} | {\color{maroon}{\texttt{K}}_{8}} |\) を出して 19 点を得る。手札には \(|{\color{maroon}{\texttt{K}}_{8}} | {\color{maroon}{\texttt{X}}_{8}} | {\color{maroon}{\texttt{A}}_{1}} |\) が残る。
- 次の三枚のタイル \(|{\color{maroon}{\texttt{H}}_{5}} | {\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{N}}_{2}} |\) を手札に加える。
- \(|{\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{N}}_{2}} | {\color{maroon}{\texttt{K}}_{8}} | {\color{maroon}{\texttt{H}}_{5}} |\) を出して 16 点を得る。
- \(|{\color{maroon}{\texttt{A}}_{1}} | {\color{maroon}{\texttt{X}}_{8}} |\) を出して 9 点を得る。手札が空になったのでゲーム終了。
このゲームについて、次の問題に答えてください。
-
タイル列が \(\mathit{Letter}[1..n]\) と \(\mathit{Value}[\texttt{A}..\texttt{Z}]\) で定義されるとします。ここで \(\mathit{Letter}[1..n]\) には \(\texttt{A}\) から \(\texttt{Z}\) までの文字が格納され、\(\mathit{Value}[l]\) は文字 \(l\) の点数を表します (この問題では同じ文字は全て同じ点数を持つとします)。与えられたタイル列における最高得点を計算する効率の良いアルゴリズムを説明、解析してください。
-
同じ文字でも異なる点数を持つことを許すことにします。このとき入力は \(\mathit{Letter}[1..n]\) と \(\mathit{Value}[1..n]\) であり、\(\mathit{Value}[i]\) が \(i\) 番目のタイルの点数を表します。与えられたタイル列における最高得点を計算する効率の良いアルゴリズムを説明、解析してください。
両方の問題において、アルゴリズムの出力は可能な最高得点を表す数字です。また手札にある七枚のタイルから作れる全ての英単語とその点数を \(O(1)\) 時間で計算できるとして構いません (実際できるので)。
-
平面上の \(n\) 個の線分の集合 \(L\) を考えます。全ての線分は \(y=0\) 上の点と \(y=1\) 上の点を結んでいて、\(2n\) 個の端点は重ならないとします。
-
どの線分も交わらない \(L\) の部分集合で最大のものを計算するアルゴリズムを説明、解析してください。
-
全ての線分の組が交わるような \(L\) の部分集合で最大のものを計算するアルゴリズムを説明、解析してください。
今度は平面上の \(n\) 個の線分の集合 \(L\) で、全ての線分の端点が単位円 \(x^{2} + y^{2} = 1\) 上にあり、\(2n\) 個の端点が重ならないものを考えます。
-
どの線分も交わらない \(L\) の部分集合で最大のものを計算するアルゴリズムを説明、解析してください。
-
全ての線分の組が交わるような \(L\) の部分集合で最大のものを計算するアルゴリズムを説明、解析してください。
-
-
\(P\) を単位円周上に均等に分布した \(n\) 個の点、\(S\) を両端点が \(P\) に含まれる \(m\) 個の線分の集合とします。 \(S\) に含まれる \(m\) 個の線分の両端点は重ならないとは限りません。また \(n\) は \(2m\) より極端に小さい可能性があります。
-
含まれるどの線分の組も共通元を持たない \(S\) の部分集合のうち最大のものを計算するアルゴリズムを説明、解析してください。線分の組が共通元を持たない (disjoint である) とは、共通の点が端点を含めて無いことを言います。
-
含まれるどの線分の組も内部に共通元を持たない \(S\) の部分集合のうち最大のものを計算するアルゴリズムを説明、解析してください。線分の組が内部に共通元を持たない (interior-disjoint である) とは、共通の点が全く無いか、あっても端点一つだけであることを言います。
-
含まれるどの線分の組も交わる \(S\) の部分集合のうち最大のものを計算するアルゴリズムを説明、解析してください。交点が端点であっても構いません。
-
含まれるどの線分の組も交差する \(S\) の部分集合のうち最大のものを計算するアルゴリズムを説明、解析してください。線分の組が交差 (cross) するとは、交わってかつ交点が端点でないことを言います。
満点のためには、四つのアルゴリズムは全て \(O(mn)\) 時間で実行されることが求められます。
-
-
あなたは高速道路を走るバスを運転しています。バスは興奮しきったやんちゃな生徒でいっぱいであり、みな喉を乾かしています。バスにはソーダのドリンクバーが付いていて、バスに乗っている生徒は一分ごとに 1 オンスのソーダを飲みます。あなたの目標は生徒が飲むソーダの量を最小にしながら生徒を早く送り届けることです。
どのバス停で何人の生徒が降りるかをあなたは把握しています。バスは高速道路の (おそらくは端ではない) どこかから出発し、一定の速度毎時 37.4 マイルで進みます。バスは高速道路だけを使って移動しますが、あるバス停についた後に元来た方向に出発することは許されています (バスを止めて、生徒を下ろして、方向を変えて出発することは瞬時に行えます)。
ソーダの消費量を最小にするように生徒の降ろす効率の良いアルゴリズムを説明してください。入力はバスのルート (バス停の名前とバス停の間の距離) と各バス停で降りる生徒の人数、バスの初期位置 (バス停のうちどれか) からなります。
-
文字列 \(A, B\) の要約 (summary) を、次の形をした部分文字列を結合したものと定義します:
-
\(\color{maroon}{\blacktriangle\texttt{SNA}}\) は最初の文字列 \(A\) にだけ含まれる \(\color{maroon}{\texttt{SNA}}\) という部分文字列を表す。
-
\(\blacklozenge\texttt{FOO}\) は \(A, B\) 両方に含まれる部分文字列 \(\texttt{FOO}\) を表す。
-
\(\color{#0071BB}{\blacktriangledown\texttt{BAR}}\) は二番目の文字列 \(B\) にだけ含まれる \(\color{#0071BB}{\texttt{BAR}}\) という部分文字列を表す。
要約が有効 (valid) であるとは、要約をこのルールに沿って (分割記号を無視しながら) 結合したときに \(A, B\) が復元できることを言います。通常の文字は \(1\) の長さを持ち、分割文字 \({\color{maroon}\blacktriangle}, \blacklozenge, {\color{#0071BB}\blacktriangledown}\) は非負の長さ \(\Delta\) を持つとします。要約の長さは文字と分割記号の長さの和です。例として、\(\color{maroon}{\texttt{KITTEN}}\) と \(\color{#0071BB}{\texttt{KNITTING}}\) の有効な要約とその長さを示します:
-
\(\blacklozenge\texttt{K}{\color{#0071BB}{\blacktriangledown\texttt{N}}}\blacklozenge\texttt{ITT}{\color{maroon}\blacktriangle\texttt{E}}{\color{#0071BB}{\blacktriangledown\texttt{I}}}\blacklozenge\texttt{N}{\color{#0071BB}\blacktriangledown\texttt{G}}\) の長さは \(9 + 7 \Delta\) です。
-
\(\blacklozenge\texttt{K}{\color{#0071BB}\blacktriangledown\texttt{N}}\blacklozenge\texttt{ITT}{\color{maroon}\blacktriangle\texttt{EN}}{\color{#0071BB}\blacktriangledown\texttt{ING}}\) の長さは \(10 + 5 \Delta\) です。
-
\(\blacklozenge\texttt{K}{\color{maroon}\blacktriangle\texttt{ITTEN}}{\color{#0071BB}\blacktriangledown\texttt{NITTING}}\) の長さは \(13 + 3 \Delta\) です。
-
\({\color{maroon}\blacktriangle\texttt{KITTEN}}{\color{#0071BB}\blacktriangledown\texttt{KNITTING}}\) の長さは \(14 + 2 \Delta\) です。
与えられた二つの文字列 \(A[1..m]\) と \(B[1..n]\) の最短の要約の長さを求めるアルゴリズムを説明、解析してください。入力には \(\Delta\) の長さも含まれます。例えば:
-
\(\color{maroon}{\texttt{KITTEN}}\) と \(\color{#0071BB}{\texttt{KNITTING}}\) と \(\Delta = 0\) が入力のとき、答えは \(9\) です。
-
\(\color{maroon}{\texttt{KITTEN}}\) と \(\color{#0071BB}{\texttt{KNITTING}}\) と \(\Delta = 1\) が入力のとき、答えは \(15\) です。
-
\(\color{maroon}{\texttt{KITTEN}}\) と \(\color{#0071BB}{\texttt{KNITTING}}\) と \(\Delta = 2\) が入力のとき、答えは \(18\) です。
-
-
Vankin's Mile は \(n \times n\) の格子状の盤を使って遊ぶ一人用ゲームです。プレイヤーは好きなところに駒を置いてからゲームを始め、ターンごとに駒を右または下に動かし、駒が盤の端についたらゲーム終了です。盤のマスには実数が書かれていて、プレイヤーのスコアはゲームが終わるまでに通ったマスに書かれている数字の和です。ゲームの目標はなるべく多くのポイントを集めることです。
例えば次の盤が与えられたとき、二行目の \(8\) からゲームを始めて下、下、右、下、下と進むことで \(8 - 6 + 7 - 3\)\({} + 4 = 10\) 点を獲得できます (この点数はこの盤に対する最高得点ではありません)。
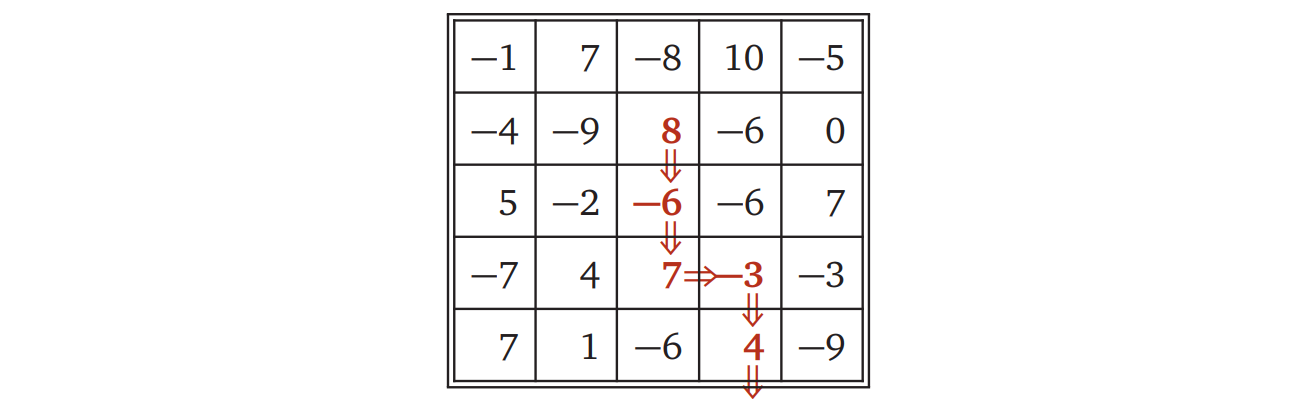
-
盤を表す \(n \times n\) の二次元配列が与えられたときに、Vankin's Mile で獲得できる最高得点を計算する効率の良いアルゴリズムを説明、解析してください。
-
このゲームのヨーロッパ版は Vankin's Kilometer というヨーロッパらしい名前をしています。このゲームはルールが少し違っていて、プレイヤーは右、下だけでなく左にも移動できます。ただし無限ループを避けるために一度通ったマスは以降通れないものとします。盤を表す \(n \times n\) の二次元配列が与えられたときに、Vankin's Kilometer で獲得できる最高得点を計算する効率の良いアルゴリズムを説明、解析してください4。
-
-
要素が \(0\) と \(1\) からなる \(n \times n\) のビットマップ \(M[1..n, 1..n]\) が与えられたとします。\(M[i..i^{\prime}, j..j^{\prime}]\) という形をした部分が全て同じ要素を持っているとき、それを \(M\) の一様区画 (solid block) と言います。一様区画の行の数と列の数が等しいとき、正方 (square) であると言います。
-
\(M\) に含まれる最大の正方一様区画の大きさを \(O(n^{2})\) 時間で求めるアルゴリズムを説明してください。
-
\(M\) に含まれる最大の一様区画の大きさを \(O(n^{3})\) 時間で求めるアルゴリズムを説明してください。
-
\(M\) に含まれる最大の一様区画の大きさを \(O(n^{2} \log n)\) 時間で求めるアルゴリズムを説明してください。 [ヒント: 分割統治]
-
❤ \(M\) に含まれる最大の一様区画の大きさを \(O(n^{2})\) 時間で求めるアルゴリズムを説明してください。
-
-
\(M[1..n, 1..n]\) の形をした実数配列が与えられたときに、長方形の部分列 \(M[i..i^{\prime}, j..j^{\prime}]\) で要素の和が最大のものを求めるアルゴリズムを説明してください。満点のためには実行時間が \(O(n^{3})\) であることが求められます。 [ヒント: 練習問題 3.2]
-
与えられたビットマップに二回以上出現する最大の長方形パターンを見つけるアルゴリズムを説明、解析してください。つまり二次元配列 \(M[1..n, 1..n]\) が与えられたときに、\(M\) に繰り返し現れる最大の長方形パターンの面積を計算してください。例えば次の図の左に示すビットマップが入力されたとき、条件を満たす最大の長方形パターンは 15 \(\times\) 13 のワン公なので、アルゴリズムの出力は 195 です (この例では二つのパターンは重なっていませんが、重なっていても構いません)。

-
満点のためには、\(O(n^{5})\) 時間で実行されるアルゴリズムを説明してください。
-
❤ ボーナス点のためには、\(O(n^{4})\) 時間で実行されるアルゴリズムを説明してください。
-
♣ ❤ さらなるボーナス点のためには、\(O(n^{3} \text{ polylog } n)\) 時間で実行されるアルゴリズムを説明してください。
-
-
\(P\) を平面上の凸 (convex) な点集合とします。直感的に言うと、\(P\) に含まれる点の周りに輪ゴムを張ると全ての点が輪ゴムと接します。きちんと言うと、 任意の \(p \in P\) について \(p\) と他の全ての点を分ける直線が存在します。この点集合に対して、 一番左にある点 \(P[1]\) から始めて "輪ゴム" を反時計回りにたどることで \(P[1], P[2], \ldots, P[n]\) と名前を付けます。
この問題で解くのは巡回セールスマン問題の特別の場合です。つまりセールスマンは通常通り \(P\) の全ての点を訪れますが、\(p \in P\) から \(q \in P\) に移動するに移動するときのコストはユークリッド距離 \(|pq|\) とします。
-
\(P\) の最短の環状な周遊 (tour)を求める単純なアルゴリズムを説明してください。
-
周遊が単純 (simple) であるとは自分自身と交差しないことを言います。今考えている \(P\) の最短の周遊は単純でなければならないことを証明してください。
-
左端の点 \(P[1]\) から始まって右端の点 \(P[r]\) で終わる最短の周遊を計算する効率の良いアルゴリズムを説明、解析してください。
-
終点に制限のない \(P\) の最短の周遊を計算する効率の良いアルゴリズムを説明、解析してください。
-
-
❤ 巡回セールスマン問題を \(O(2^{n} \text{poly}(n))\) 時間で解くアルゴリズムを説明、解析してください。アルゴリズムには辺に重みの付いた \(n\) 頂点の無向グラフ \(G\) が与えられ、アルゴリズムが返すのは全ての頂点をちょうど一回ずつ通る一番軽い巡回路の重さ、あるいはそのような巡回路が存在しない場合には \(\infty\) です。 [ヒント: バックトラッキングを使った自明な再帰的アルゴリズムの実行時間は \(O(n!)\) です。]
-
\(W=\lbrace w_{1}, w_{2}, \ldots, w_{n} \rbrace\) を固定されたアルファベット \(\Sigma\) に対する文字列の有限集合とします。 \(W\) の編集中心 (edit center) とは文字列 \(C \in \Sigma^{\ast}\) であって \(W\) に属する文字列との編集距離の最大値が最小になるものを言います。編集半径 (edit radius) とは編集中心と \(W\) に属する文字列との編集距離の最大値のことです。文字列の集合は複数の編集中心を持つことがありますが、編集半径は一つしか持ちません。 \[ \begin{aligned} \mathit{EditRadius}(W) & := \min\limits_{C \in \Sigma^{\ast}} \max\limits_{w \in W} \mathit{Edit}(w, C) \\ \mathit{EditCenter}(W) & := \underset{C \in \Sigma^{\ast}}{\textrm{\footnotesize argmin}} \max\limits_{w \in W} \mathit{Edit}(w, C) \end{aligned} \]
-
与えられた三つの文字列の編集中心を計算するアルゴリズムを説明、解析してください。
-
♣ ❤ 任意の文字列集合の編集半径を最悪でも真の値から \(2\) 倍の範囲で近似する効率の良いアルゴリズムを説明、解析してください (文字列の数が固定されていない場合、編集距離の真の値を求めるのは NP 困難です)。
-
-
❤ \(0\) から \(9\) の一桁の整数からなる配列 \(D[1..n]\) について、\(D\) のデジタル部分列 (digital subsequence) とは \(D\) の互いに重ならない部分文字列を元の配列と同じ順番に並べたものを、通常の数字の列として読んだときの列です。例えば 3, 4, 5, 6, 8, 9, 32, 38, 46, 64, 83 は、円周率の最初の部分の数列としたときのデジタル部分配列です: \[ |3|, 1, |4|, 1, |5|, 9, 2, |6|, 5, 3, 5, |8|, |9|, 7, 9, |3, 2|, |3, 8|, |4, 6|, 2, |6, 4|, 3, 3, |8, 3| \]
デジタル部分配列の長さを含まれる数字の数として定義します (含まれる数字の桁数の和ではありません)。この例では長さは 12 です。通常の配列と同じように、全ての数が一つ前の数よりも大きい場合デジタル部分配列を増加 (increasing) であると言うことにします。
\(D\) の最長増加デジタル部分配列を計算する効率の良いアルゴリズムを説明、解析してください。 [ヒント: 計算量に関する仮定に注意! \(k\) 桁の数の比較演算の実行時間はいくつですか?]
満点のためには、アルゴリズムの実行時間が \(O(n^{4})\) であることが求められます。これよりも速いアルゴリズムにはボーナス点が付きます。私が知っている範囲で最速のアルゴリズムの実行時間は \(O(n^{3 / 2} \log n)\) です。この実行時間を達成するにはアルゴリズムの設計と解析にいくつかのトリックが必要ですが、全てこの講義の範囲に収まっています 5。
-
❤ 古典的な Hanoi の塔問題を次のように改変したものを考えます。通常の問題と同じように \(n\) 枚の異なる大きさの円盤と \(0, 1, 2\) と番号のついた \(3\) つの杭があり、最初 \(n\) 枚の円盤は全て杭 \(0\) に置かれ、大きいものが一番下で、上に行くほど小さくなるようになっています。目標は全ての円盤を杭 \(2\) に移動させることです。行うことができる操作はある杭の一番上に載っている円盤一つを別の杭に移動させることだけであり、この操作には従わなければならないルールがあります。まず、円盤をそれよりも小さな円盤の上に置くことはできません。次に、これが標準の問題との唯一の違いなのですが、杭 \(0\) から杭 \(2\) に円盤を直接移動させることはできません。
このルールの下で、\(n\) 枚の円盤全てを杭 \(0\) から杭 \(2\) に移動させるための最小の操作数を求めるアルゴリズムを説明、解析してください。満点を得るためには、最悪ケースでも \(O(\log n)\) 回の算術演算を使うことが求められます。解析のときには、\(k\) 桁の数の加算と乗算命令の実行時間が \(O(k)\) であるとしてください。 [ヒント: 行列!]
\({}\)
列/配列の分割
-
基本算術式 (basic arithmetic expression) は \(\lbrace 1, +, \times \rbrace\) と括弧から構成されます。ほぼ全ての整数について、その数を表す基本算術式は複数あります。 例えば次の基本算術式は全て 14 を表します: \[ \begin{gathered} 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 \\ ((1 + 1) × (1 + 1 + 1 + 1 + 1)) + ((1 + 1) × (1 + 1)) \\ (1 + 1) × (1 + 1 + 1 + 1 + 1 + 1 + 1) \\ (1 + 1) × (((1 + 1 + 1) × (1 + 1)) + 1) \end{gathered} \]
\(n\) が与えられたときに、\(n\) を基本算術式で表すために必要になる \(1\) の数の最小値を求めるアルゴリズムを説明、解析してください。括弧の数は関係なく、1 の数だけを考えます。先ほどの \(n = 14\) の例では、最後の基本算術式に対応する \(8\) が答えです。アルゴリズムの実行時間は次数の小さい多項式で抑えられるはずです。
-
\(+\) と \(-\) で区切られた整数列を与えられたとします。例えば次のような列です: \[ \begin{gathered} 1 + 3 - 2 - 5 + 1 - 6 + 7 \end{gathered} \] これを式とみなした上で括弧を付けると、式が表す値が変化します: \[ \begin{gathered} 1 + 3 - 2 - 5 + 1 - 6 + 7 = -1 \\ (1 + 3 - (2 - 5)) + (1 - 6) + 7 = 9 \\ (1 + (3 - 2)) - (5 + 1) - (6 + 7) = -17 \end{gathered} \]
\(+\) と \(-\) で区切られた整数列を受け取って、それを式とみなしたときに括弧を付けることで表すことができる値の最大値を求めるアルゴリズムを説明、解析してください。括弧は加算と減算をまとめるために使うことだけが許されています。 \(1 + 3(-2)(-5) + 1 - 6 + 7 = 33\) のように括弧を続けて書いて乗算を表すことはできません。
-
\(+\) と \(\times\) で区切られた整数列を与えられたとします。例えば次のような列です: \[ 1 + 3 \times 2 \times 0 + 1 \times 6 + 7 \] これを式とみなした上で括弧を付けると、式が表す値が変化します: \[ \begin{gathered} (1 + (3 \times 2)) \times 0 + (1 \times 6) + 7 = 13 \\ ((1 + (3 \times 2 \times 0) + 1) \times 6) + 7 = 19 \\ (1 + 3) \times 2 \times (0 + 1) \times (6 + 7) = 104 \end{gathered} \]
-
入力の整数が全て正だと仮定したときに、括弧を付けることで表すことができる値の最大値を求めるアルゴリズムを説明、解析してください。 [ヒント: この問題は簡単です。]
-
入力の整数が全て非負だと仮定したときに、括弧を付けることで表すことができる値の最大値を求めるアルゴリズムを説明、解析してください。
-
入力の整数に制約がない場合に、括弧を付けることで表すことができる値の最大値を求めるアルゴリズムを説明、解析してください。
算術演算は \(O(1)\) で実行できるとしてください。
-
-
あなたは Shampoo-Banana 大学を卒業し、ウォールストリートの Long Live Boole 銀行の就職面接を受けることに決めました。銀行のマネージャー Eloob Egroeg は新入りの従業員に対して制限時間が 24 時間の "解答か死か" 形式の問題を出して、この問題が解けなければその時点で首を切ると言います!
あなたが銀行に初めて入ると、従業員のオフィスは一列に並んでいて、それぞれのドアには "\(T\)" あるいは "\(F\)" と大きく印が付いていました。さらに隣り合うオフィスの間には \(\land, \lor, \oplus\) の記号のどれか一つが書かれたボードがあります。この難解な記号について Eloob に尋ねたところ、\(T, F\) はブール値 \(\textsc{True}\) と \(\textsc{False}\) を表し、ボードに書いてある記号はブール演算の \(\textsc{And}, \textsc{Or}, \textsc{Xor}\) を表すと教えてくれました。また文字と記号は特定の従業員の組み合わせが一緒に上手く働けるかどうかを表しているとのことです。新しいプロジェクトを始めるとき、 Eloob は記号列の間に括弧を入れて曖昧性の無いブール式にすることで従業員をグループに分け、括弧を入れたブール式が \(T\) に評価されるならばそのプロジェクトは成功するそうです。
例えば銀行に三人の従業員がいて、オフィスのドアとオフィスの間のボードに書かれている記号が \(T \land F \oplus T\) だとすると、括弧をつけて全体を \(T\) にする方法は \((T \land (F \oplus T))\) の一つです。しかし記号列が \(F \land T \oplus F\) だった場合、どう括弧を入れてもプロジェクトは失敗します。
そして Eloob が出した "解答か死か" の面接問題はこれです: 与えられた記号列に括弧を入れることで全体の式が \(T\) に評価されるようにできるかどうかを判定するアルゴリズムを説明してください。アルゴリズムの入力は配列 \(S[0..2n]\) であり、\(i\) が偶数のとき \(S[i] \in \lbrace T, F \rbrace\) 、\(i\) が奇数のとき \(S[i] \in \lbrace \land, \lor, \oplus \rbrace\) です。
-
南極カタツムリ同好会 Upper Glacierville 支部 (Antarctican Snail Lovers of Upper Glacierville) は毎年の会合で "円卓の友レース" を開催しています。 \(1\) から \(n\) までの番号がつけられた育ちの良いカタツムリが円卓の端に置かれた状態からスタートし、合図と共にねばねばした跡を残しながら卓上を動き回ります。カタツムリたちは自分と他のカタツムリの残した跡を横切らないように訓練されており、卓から落ちることもありません。二匹のカタツムリが出会うとそのカタツムリのペアは繁殖の準備ができたとみなされ、卓から取り除かれて子供を作るためのロマンチックな部屋に放り込まれます。このレースでは制限時間がなかったとしても相手を見つけられないカタツムリが出る場合があることに注意してください。
![レースの終了の一例を図示したもの。カタツムリ 6 と 8 は相手を見つけられない。主催者は \(M[3,4] + M[2,5] + M[1,7]\) を払う。](/algorithms/AlgorithmFigure_3-6.png) 図 3.6レースの終了の一例を図示したもの。カタツムリ 6 と 8 は相手を見つけられない。主催者は \(M[3,4] + M[2,5] + M[1,7]\) を払う。
図 3.6レースの終了の一例を図示したもの。カタツムリ 6 と 8 は相手を見つけられない。主催者は \(M[3,4] + M[2,5] + M[1,7]\) を払う。円卓の友レース中に成立した全てのカタツムリのカップルに対して、Antarctican SLUG のレース主催者は祝い金を支払います。二次元配列 \(M[1..n, 1..n]\) が円卓の後ろの壁に貼られており、カタツムリ \(i\) と \(j\) が出会ったときには \(M[i,j] = M[j,i]\) が双方のカタツムリの飼い主に支払われます。
入力として \(M\) が与えられたときに、主催者が払う必要が生じうる最高金額を計算するアルゴリズムを説明、解析してください。
-
あなたは採石場から大理石の大きな板を採掘しました。簡単のため、大理石の板は横 \(n\) インチ、縦 \(m\) インチの長方形だとします。キッチンカウンター、彫刻、墓石などで使うために、この大理石から様々な形の小さな長方形を切り出したいとします。
あなたは任意の大きさの長方形の大理石を水平あるいは垂直にカットできる大理石カッターを持っています。また横 \(x\) インチ、縦 \(y\) インチの大理石の板の値段を表す配列 \(P[x, y]\) があり、いつでも参照できます。この値段は客の需要によって決まっていますが、キッチンカウンターで使う大理石を買いに来るお客というのは少し変わっているので、彼らについて常識的な仮定を置かないでください。つまり、大きい板が小さい板よりも極端に低い値段で売れることもあります。
横 \(x\) インチ、縦 \(y\) インチの板の値段を表す配列と板のサイズ \(m, n\) を入力として受け取って、売り上げを最大化する \(m \times n\) インチの板の分割方法を計算するアルゴリズムを説明してください。
-
この問題では特定の制約を満たす最適二分探索木を構築する効率の良いアルゴリズムを設計してもらいます。入力はソート済みの鍵配列 \(A[1..n]\) と頻度数配列 \(f[1..n]\) であり、\(f[i]\) が \(A[i]\) に対する探索の回数を表します。問題は基本的に以前に示したものと同じですが、ここでは追加の制約があります。
-
AVL 木 (AVL tree) は自動的にバランスが保たれる二分探索木のうち最初に発見されたものであり、1962 年に Georgy Adelson-Velsky (ゲオルギー・アデルソン・ヴェルスキー) と Evgenii Landis (エフゲニー・ランディス) によって提案されました。AVL 木では任意の頂点 \(v\) について、\(v\) の左右の部分木の高さは最大でも \(1\) しか違いません。
鍵と頻度を表す配列を受け取って最適な AVL 木を返すアルゴリズムを説明、解析してください。
-
対称二分 B 木 (symmetric binary B-tree) も自動的にバランスが保たれる二分木であり、1972 年にRudolf Bayer (ルドルフ・ベイヤー) によって提案されました。1978 年に Robert Sedgewick (ロバート・セッジウィック) と Leonidas Guibas (レオニダス・ギバス) によって単純な形に変形され、現在では赤黒木 (red-black tree)という名前で知られています。
赤黒木は次の制約を持つ二分探索木です:
- 全ての頂点は赤または黒である。
- 赤い頂点の親は黒い。
- 根から葉への任意の道は同じ数の黒い頂点を含む。
鍵と頻度を表す配列を受け取って最適な赤黒木を返すアルゴリズムを説明、解析してください。
-
AA 木 (AA tree) は 1993 年に Arne Andersson (アルネ・アンデルソン) によって提案され、2000 年に Mark Allen Weiss (マーク・アレン・ウェイス) によって単純化され (そして名前を付けられ) ました。2006 年には Robert Sedgewick によって鏡写しの (バランスを保つためのアルゴリズムが異なる) データ構造が提案されていますが、このデータ構造は "AA 木" ではなく "左に傾いた赤黒木" と呼ばれました。
AA 木は次の追加の制約を持つ赤黒木です:
- 左の子は赤くない6。
鍵と頻度を表す配列を受け取って最適な AA 木を返すアルゴリズムを説明、解析してください。
-
-
\(0\) と \(1\) からなる \(n \times n\) のビットマップ \(M[1..n, 1..n]\) が与えられたとします。\(M[i..i^{\prime}, j..j^{\prime}]\) という形をした部分が全て同じ要素を持っているとき、それを \(M\) の一様区画 (solid block) と言います。\(M\) をなるべく少ない数の互いに重ならない一様区画に分割したいとします。
この問題に対する単純な再帰的戦略の一つに、ギロチン分割と呼ばれるものがあります。ギロチン分割は \(M\) が一様区画であれば何もせず、そうでなければ水平または垂直に \(M\) を分割して両方の部分を再帰的に一様区画に分割するというものです。
任意のギロチン分割は二分木で表せます。この二分木の頂点は分割の場所と方向を保持し、葉は対応する一様区画の要素 \(0\) または \(1\) を保持します。ギロチン分割のサイズとは対応する二分木の葉の数 (つまり、最終的に残る一様区画の数) であり、ギロチン分割の深さとは対応する二分木の深さです。
-
\(M\) のギロチン分割でサイズが最小なものを計算するアルゴリズムを説明、解析してください。
-
ギロチン分割を使った分割をしても常に一様区画の数が最小になるわけではないことを示してください。
-
\(M\) のギロチン分割で深さが最小なものを計算するアルゴリズムを説明、解析してください。
-
\(M\) のギロチン分割を表す二分木と添え字 \(i, j\) から \(M[i,j]\) を計算するアルゴリズムを説明、解析してください。
-
ギロチン分割におけるピクセル \(M[i,j]\) の深さを、ギロチン分割を表す二分木におけるそのピクセルが含まれる葉の深さとして定義します。 \(M\) のギロチン分割でピクセルの深さの和が最小なものを計算するアルゴリズムを説明、解析してください。
-
\(M\) のギロチン分割で黒いピクセルの深さの和が最小なものを計算するアルゴリズムを説明、解析してください。
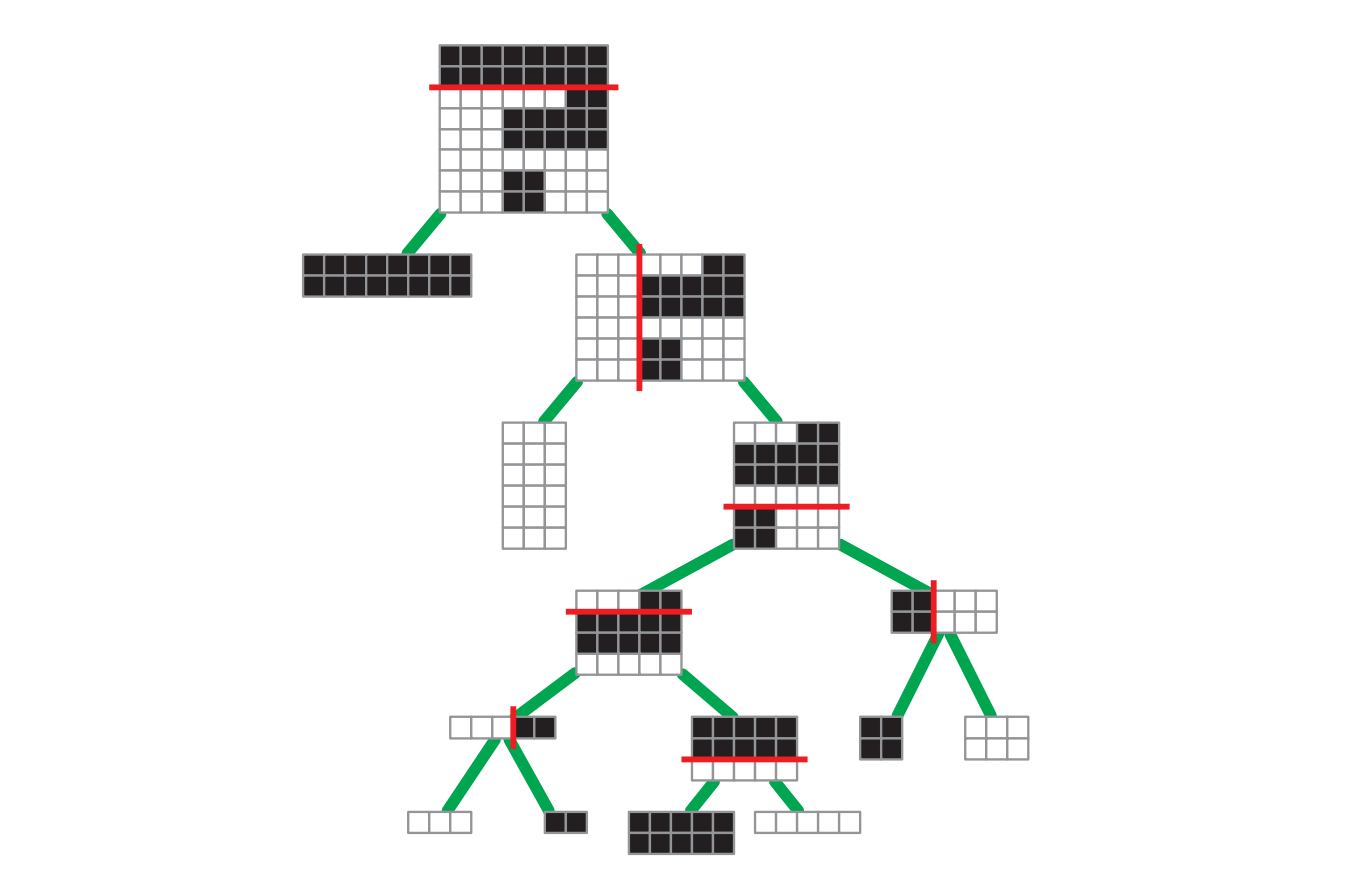 図 3.7サイズ \(8\)、深さ \(5\) のギロチン分割
図 3.7サイズ \(8\)、深さ \(5\) のギロチン分割 -
-
♠ おめでとうございます!あなたは巨大オンライン書店 DeNile ("Not just a river in Egypt!") に雇われ、倉庫ロボットを最適化する仕事をすることになりました。DeNile が販売する全ての本には ISBN (Internatinal Standard Book Number) というユニークな数字が付いています。DeNile の倉庫には箱が一列に並んでおり、それぞれの箱には一種類の本が何冊か入っています。この箱は ISBN によってソートされており、ISBN は箱の表面に機械が読める形式で書かれています。書店が注文を受けると、箱の列に沿って移動できるロボットが本を取りに行きます。
DeNile にはどの箱にどの ISBN が入っているかのリストを持っていません (問題が簡単になりすぎます!)。その代わり、ロボットは本を取りに行くたびに二分探索を行います。探索にはロボットの物理的な動作が関わるために、探索の各ステップが \(O(1)\) 時間で終わるという仮定は成り立たなくなります。つまり:
-
ロボットは常に 0 番目の箱から探索を始める (配送用の箱がここにある)。
-
\(i\) 番目の箱から \(j\) 番目の箱に移動するには \(\alpha |i - j|\) 秒かかる ( \(\alpha\) は定数)。
-
箱の ISBN を読み取るためには箱の真正面にいなければならない。ISBN の読み取りには \(\beta\) 秒かかる ( \(\beta\) は定数 )。
-
ロボットの方向を変えるには \(\gamma\) 秒かかる ( \(\gamma\) は定数 )。
-
ロボットが目的の箱を見つけたら、箱から本を取り出して 0 番目の箱の場所に戻る。
ロボットによる箱の探索を最短にする二分探索木を計算するアルゴリズムを説明、解析してください。アルゴリズムの入力は整数配列 \(f[1..n]\) であり、\(f[i]\) が \(i\) 番目の箱にある本を取りに行く回数を表します。 \(\alpha, \beta, \gamma\) も入力として与えられます。
-
-
♠ 探索木のキャッシュパフォーマンスを向上させるためによく使われる方法の一つに、鍵と部分木を通常よりも多く頂点に格納するというものがあります。B-木 (B-tree) とは、葉でない頂点が最大 \(B\) 個の鍵と最大 \(B+1\) 個のより小さい B-木 (子) へのポインタを格納している根付き木です。具体的に言うと、B-木の頂点 \(v\) は三つのフィールドを持ちます:
- 正の整数 \(\mathit{v.d} \leq B\)
- ソート済みの配列 \(\mathit{v.key}[1..v.d]\)
- 子へのポインタの配列 \(\mathit{v.child}[0..v.d]\)
この制約は頂点の子の数が鍵の数よりちょうど一つ多くなることを表しています7。
ポインタ \(\mathit{v.child}[i]\) は \(\textsc{Null}\) または他の B-木の根へのポインタです。 \(\mathit{v.child}[i]\) が木の根を指す場合、その木は \(\mathit{v.key}[i]\) より大きく \(\mathit{v.key}[i+1]\) よりも小さい鍵を保持します。また左端の部分木 \(\mathit{v.child}[0]\) は \(\mathit{v.key}[1]\) よりも小さい鍵を、右端の部分木 \(\mathit{v.child}[v.d]\) は \(\mathit{v.key}[v.d]\) よりも大きい鍵をそれぞれ保持します。
直感的には、次のような図を思い浮かべることができるはずです:
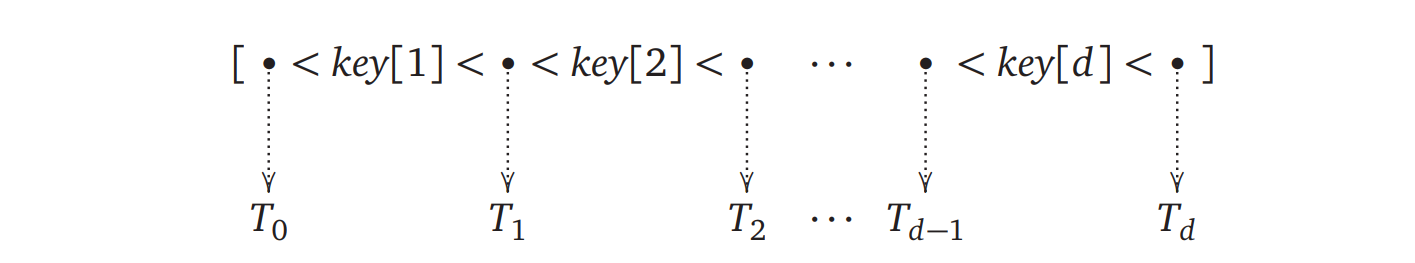
図中の \(T_{i}\) は \(\mathit{child}[i]\) によって指される部分木です。
B-木の鍵 \(x\) に対する探索コストとは根から \(x\) を含む頂点への道の長さです。また 1-木は二分探索木です。
整数 \(B > 0\) を固定します (実際のコードでは \(B = 8\) が推奨されます)。ソート済みの鍵配列 \(A[1..n]\) と頻度を表す配列 \(F[1..n]\) が与えられ、\(F[i]\) が \(A[i]\) の探索される回数を表すとします。この問題の目標は合計探索時間が最小となる B-木を構築する効率の良いアルゴリズムを説明、解析することです。
-
特殊ケース \(B=2\) に対する多項式時間アルゴリズムを説明してください。
-
任意の \(B\) に対して、実行時間が整数定数 \(c\) を使って \(O(n^{B+c})\) と表されるアルゴリズムを説明してください。
-
❤ 任意の \(B\) に対して、実行時間が整数定数 \(c\) を使って \(O(n^{c})\) と表される (\(\pmb{B}\) に依存しない) アルゴリズムを説明してください。
-
丸括弧 \(\color{green}{()}\) と鍵括弧 \(\color{#B52F1B}{[]}\) からなる文字列 \(w\) のバランスが取れている (balanced) とは、次の条件のうちどれかを満たすことを言います:
- \(w\) は空文字列である。
- バランスの取れた文字列 \(x\) を使って \(w = {\color{green}{(}} x {\color{green}{)}}\) と表せる。
- バランスの取れた文字列 \(x\) を使って \(w = {\color{#B52F1B}{[}} x {\color{#B52F1B}{]}}\) と表せる。
- バランスの取れた文字列 \(x,y\) を使って \(w = xy\) と表せる。
例えば \[ w = {\color{green}{(}} {\color{#B52F1B}{[}} {\color{green}{(}} {\color{green}{)}} {\color{#B52F1B}{]}} {\color{#B52F1B}{[}} {\color{#B52F1B}{]}} {\color{green}{(}} {\color{green}{)}} {\color{green}{)}} {\color{#B52F1B}{[}} {\color{green}{(}} {\color{green}{)}} {\color{green}{(}} {\color{green}{)}} {\color{#B52F1B}{]}} {\color{green}{(}} {\color{green}{)}} \] はバランスの取れた文字列です。なぜなら次のように \(x,y\) を定義すると \(w = xy\) であり、 \(x\) と \(y\) がバランスの取れた文字列だからです: \[ x = {\color{green}{(}} {\color{#B52F1B}{[}} {\color{green}{(}} {\color{green}{)}} {\color{#B52F1B}{]}} {\color{#B52F1B}{[}} {\color{#B52F1B}{]}} {\color{green}{(}} {\color{green}{)}} {\color{green}{)}}, \quad y = {\color{#B52F1B}{[}} {\color{green}{(}} {\color{green}{)}} {\color{green}{(}} {\color{green}{)}} {\color{#B52F1B}{]}} {\color{green}{(}} {\color{green}{)}} \]
-
入力として丸括弧と鍵括弧からなる文字列が与えられます。この文字列のバランスがとれているかどうかを判定するアルゴリズムを説明、解析してください。
-
入力として丸括弧と鍵括弧からなる文字列が与えられます。この文字列のバランスがとれている部分列で最長のものの長さを計算するアルゴリズムを説明、解析してください。
-
入力として丸括弧と鍵括弧からなる文字列が与えられます。この文字列のバランスがとれている超配列で最短のものの長さを計算するアルゴリズムを説明、解析してください。
-
入力として丸括弧と鍵括弧からなる文字列が与えられます。丸括弧と鍵括弧のバランスがとれている文字列とこの文字列との間の編集距離の最小値を計算するアルゴリズムを説明、解析してください。
-
❤ 入力として丸括弧と鍵括弧からなる二つの文字列が与えられます。二つの文字列のバランスの取れた最長共通部分列を計算するアルゴリズムを説明、解析してください。
-
❤ 入力として丸括弧と鍵括弧からなる文字列が与えられます。この文字列のバランスが取れていてかつ回文である部分列で最長のものを計算するアルゴリズムを説明、解析してください。
-
❤ 入力として丸括弧と鍵括弧からなる二つ文字列が与えられます。二つの文字列のバランスが取れていてかつ回文である共通部分列で最長のもの (!!!) を計算するアルゴリズムを説明、解析してください。
いずれの問題でも、入力は \(w[1..n]\) \((w[i] \in \lbrace {\color{green}{(}}, {\color{green}{)}}, {\color{#B52F1B}[}, {\color{#B52F1B}]} \rbrace)\) です。
-
おめでとうございます!あなたは DARPA, Google, McDonald が出資する 5000 万ドルのプロジェクトを勝ち取りました。このプロジェクトでは、プログラマーの脳を読む世界初のコンパイラ DWIM を作成します!研究提案書と数えきれないプレスリリースで、あなたは DWIM が任意のコード片に含まれるエラーを自動的に修正し、そのときのコードの改変は最小限であると宣伝してきました。そして残念なことに、このブツを実際に作る時間がついにやってきました。
あなたはウォーミングアップとして、次の小さな問題に取り組むことにしました。二つの文字列の間の編集距離とは、一文字の挿入、削除、置換を使って片方の文字列をもう片方の文字列に変形するときに必要になる操作の回数の最小値であることを思い出してください。また \(w\) が算術式であるとは、次の条件を満たすことを言います:
- \(w\) が一つ以上の数字の桁からなる文字列である。
- 算術式 \(x\) を使って \(w = (x)\) と表せる。
- 算術式 \(x, y\) と二項演算子 \(\diamond\) を使って \(w = x \diamond y\) と表せる。
アルファベット \(\lbrace \#, \diamond, (, ) \rbrace\) (\(\#\) は一桁の数、\(\diamond\) は二項演算子 ) からなる文字列が与えられたときに、その文字列から算術式への編集距離の最小値を求めるアルゴリズムを説明、解析してください。
-
リボ核酸 (RNA) 分子はヌクレオチド (基) が数百万個つながった長い鎖であり、基にはアデニン (\(A\))、シトシン (\(C\))、グアニン (\(G\))、ウラシル (\(U\)) の四種類があります。RNA 分子の配列は文字列 \(b[1..n]\) で表され、各 \(b[i] \in \lbrace A, C, G, U \rbrace\) が基に対応します。鎖上で隣り合う分子同士の化学結合に加えて、ある条件を満たす基の間には水素結合が作られます。水素結合で結合した基の組とRNA 配列の全体を指して RNA 分子の二次構造と言います。
二つの基の組 \((i, j)\) と \((i^{\prime}, j^{\prime})\) (\(i < j\) かつ \(i^\prime < j^{\prime}\)) が重なるとは、\(i < i^{\prime} < j < j^{\prime}\) または \(i^{\prime} < i < j^{\prime} < j\) が成り立つことを言います。現実の二次構造はほとんどの組は重なっていません。重なる基の組は二次構造でいわゆる pseudoknots を形成しますが、これは予測が困難です。
与えられた RNA 配列に対する最良の二次構造を予測したいとします。二次構造のモデルとして、次の大胆に単純化したモデルを使います:
- 基は多くとも一つの他の基と結合する。
- A-U と C-G の組だけが結合できる。
- \((i, i+1)\) と \((i, i + 2)\) という形の基は結合できない。
- 結合する基の組同士は重なってはいけない。
最後の (全く現実的でない) 制限があるので、RNA の二次構造を太った木 (fat tree) に近いものを使って可視化できます:
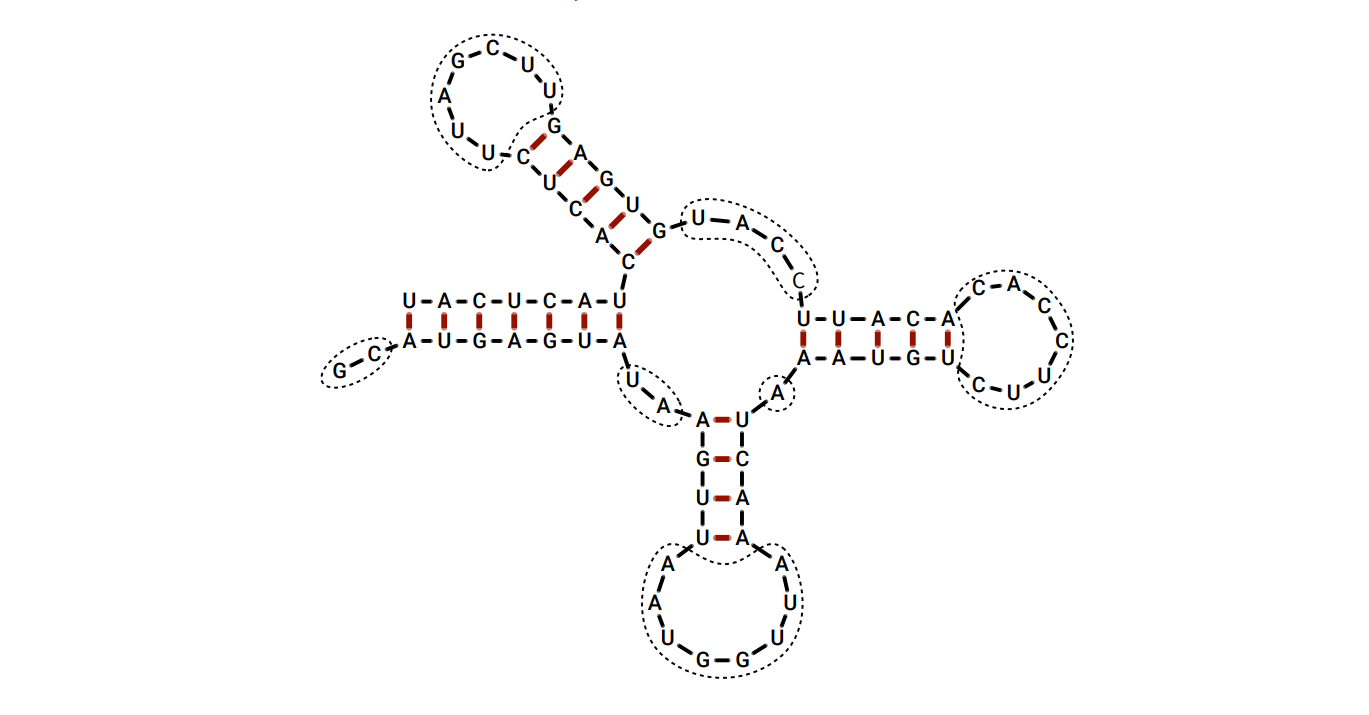 図 3.8. RNA の二次構造の例。赤線で示された 21 個の結合ペアを持つ。ギャップは破線で囲まれている。この構造のスコアは \(2^{2} + 2^{2} + 8^{2} + 1^{2} + 7^{2} + 4^{2} + 7^{2} = 187\) である。
図 3.8. RNA の二次構造の例。赤線で示された 21 個の結合ペアを持つ。ギャップは破線で囲まれている。この構造のスコアは \(2^{2} + 2^{2} + 8^{2} + 1^{2} + 7^{2} + 4^{2} + 7^{2} = 187\) である。-
与えられた RNA 配列が構成できる結合組の数の最大値を求めるアルゴリズムを説明、解析してください。
-
二次構造におけるギャップ (gap) とは組になっていない極大の部分文字列のことを言います。大きなギャップは科学的に不安定なので、小さなギャップを持つ構造が多く出現します。この傾向を取り入れるために、二次構造のスコアをギャップの長さの二乗和として定義します。例としては上図を見てください (このスコア関数は全く人工的なものです。現実の RNA 構造予測にはこれよりずっと複雑なスコア関数が必要になります)。
RNA 配列が与えられたときに、二次構造の最小スコアを計算するアルゴリズムを説明、解析してください。
-
♣ 正規表現の演算は \(\cdot\) (連結)、\(+\) (和集合)、\({}^{\ast}\) (Kleene 閉包) の三つとします。
-
文字列 \(w\) と正規表現 \(R\) が与えられたときに、\(w \in L(R)\) かどうかを判定する効率の良いアルゴリズムを説明、解析してください。
-
一般化された正規表現 (generalized regular expression) とは普通の正規表現に二項演算子 \(\cap\) (共通部分) と単項演算子 \(\lnot\) (補集合) を加えたものです。一般化された正規表現に対応する NFA が構築できることと Kleene の定理から、一般化された正規表現 \(E\) が表す言語 \(L(E)\) が正規であることが言えます。
文字列 \(w\) と一般化された正規表現 \(E\) が与えられたときに、\(w \in L(E)\) かどうかを判定する効率の良いアルゴリズムを説明、解析してください。
\({}\)
木と部分木
-
-
あなたは Abugida の子会社 Giggle, Inc で行われる初めてのホリデーパーティ (強制参加) の幹事となりました。Giggle の従業員の間には社長を根とした木で表される厳格な上下関係があり、人事部にある全能のオラクルは全ての従業員の "面白さ" を知っています。
パーティが社交的になるように、ある従業員がパーティに出席できるのはその直属の上司がパーティに参加するときだけと決まっています。ただし、社長は面白さの評価が負にもかかわらずパーティに必ず参加します (結局、この会社は彼女のものですから)。面白さの評価の和を最大化する出席者のリストを作成するアルゴリズムを示してください。
-
昨年のホリデーパーティの参加者があまりにも少なかったことから、Giggle の社長は今年はパーティの代わりに全ての従業員にプレゼントを渡すことを決めました。具体的には、従業員は次の三つのうち一つを受け取れます: (1) 世界の好きなところで過ごせる六週間の無料休暇 (2) Jumping Jack Flash's Flapjack Stack Shack の朝食パンケーキ食べ放題券ペア (3) 犬の糞が詰まった燃え盛る紙袋。
直属の上司と同じプレゼントを受け取ることはできないことが社則で決まっています。また直属の上司よりも上等なプレゼントを受け取った従業員は、嫉妬した上司によって首を切られてしまうでしょう。
Giggle の公式パーティを統べる者として、どの従業員がどのプレゼントを受け取るかを決めるのはあなたの仕事です。解雇される従業員の数が最小となるようにプレゼントを配るアルゴリズムを説明してください。ええ、社長に燃え盛る犬の糞を送り付けることもできます。
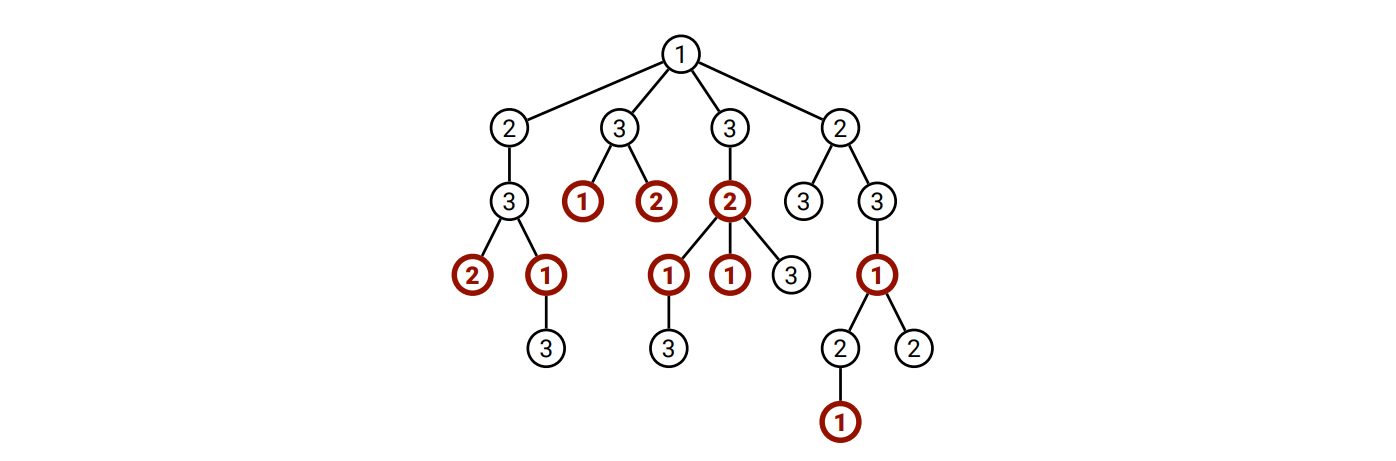 図 3.9コストが \(9\) の割り当て。赤い頂点が親よりも小さい値を割り当てられた頂点を表す。これはこの木に対する最適な割り当てではない。
図 3.9コストが \(9\) の割り当て。赤い頂点が親よりも小さい値を割り当てられた頂点を表す。これはこの木に対する最適な割り当てではない。きちんと問題を定義すると、会社の上下関係を表す根付き木 \(T\) が与えられたときに、各頂点に \(1, 2, 3\) のどれかを割り当てます。割り当てのコストを親よりも小さな値が割り当てられる頂点の数としたときに、コストが最小となる \(T\) への割り当てを求めるアルゴリズムを説明、解析してください。
-
燃え盛る犬の糞の大失敗を見たあなたは大急ぎで他の職を探し、Giggle を離れてそのライバル会社 Twitbook に移りました。不幸なことに、Twitbook の新しい社長は Giggle のホリデーパーティーと同じことをやってみようとちょうど決断したところで、あなたの過去の経験を見た社長はあなたを公式パーティーの幹事に抜擢しました。社長の命によると、社長を含むちょうど \(k\) 人の従業員を招待し、全員の参加を強制しなければならないとのことです。面白いことになってきました。
Giggle と同じように、 Twitbook の従業員の間は社長を根とした木で表される厳格な上下関係があります。また人事部にある全能のオラクルは全ての従業員の "気まずさ" を知っています。この値は従業員が直属の上司と上手く行っているかどうかを表します。例えば気まずさが負ならば、その従業員と直属の上司は上手く行っているということです。あなたの目標は従業員の中から \(k\) 人を選んで、気まずさの和が最小になるようにすることです。例えば招待した従業員の中にある従業員とその直属の上司の組が一つも無いなら、気まずさの和は \(0\) です。アルゴリズムの入力は木 \(T\), 整数 \(k\), 各頂点の気まずさです。
-
従業員の上下関係が二分木である、つまり全ての従業員に部下が最大でも二人しかいない場合に、\(k\) 人の従業員の部分集合で気まずさが最小となるものを計算するアルゴリズムを説明、解析してください。
-
❤ 従業員の上下関係に制約が無い場合に、\(k\) 人の従業員の部分集合で気まずさが最小となるものを計算するアルゴリズムを説明、解析してください。
-
-
根付き木の全ての頂点にメッセージを送りたいとします。最初にメッセージを知っているのは根の頂点だけで、各ラウンドでメッセージを知っている頂点は最大で一つの子にメッセージを送ることができます。例を次に示します:
 図 3.105 ラウンドでメッセージが木の全ての頂点に行き渡る様子
図 3.105 ラウンドでメッセージが木の全ての頂点に行き渡る様子-
メッセージを二分木に含まれる全ての頂点に届けるために必要な最小のラウンド数を計算するアルゴリズムを作ってください。
-
♦ メッセージを任意の根付き木に含まれる全ての頂点に届けるために必要な最小のラウンド数を計算するアルゴリズムを作ってください。 [ヒント: このアルゴリズムは貪欲アルゴリズムではありませんが、正しさの証明には次の章で説明するテクニックが役に立ちます。]
-
-
ある日、ジムの壁を登るのに飽きた Alex は、クライマーの友達を大勢誘って屋外の壁を登りに行きました。彼らが訪れたクライミングエリアはとても横にとても長い岩で、あまり高くはありませんでした。岩には手足を掛ける場所 (ホールド) がたくさんありましたが、それを見た Alex は友達と話し合って "許されている" 動きを設定しました。ホールドの間を移動するときには、このルールに従わなければなりません。
ホールドと許されている動きは \(n\) 頂点の根付き木 \(T\) で表され、頂点がホールドに、辺が許されているホールド間の動きを表します。岩を上る道は上に行くほど小さくなり、最終的にホールド一つになります。このホールドが \(T\) の根に対応します8。
Alex とその友達 (みな優秀なクライマーです) は、なるべく多い人数で岩を同時に上るというゲームをすることになりました。ただしクライマーはちょうど \(k\) 回だけ岩を上に向かって登らないといけません。つまり、クライマーは \(T\) の中で根に向かって長さ \(k\) の道を描きます。加えて、一つのホールドを使えるのは一人のクライマーだけです。つまりクライマーの軌跡が交差してはいけません。
このゲームをプレイできる最大人数を計算する効率の良いアルゴリズムを説明、解析してください。きちんと言うと、根付き木 \(T\) と整数 \(k\) が与えられたときに、\(T\) の根に向かう長さ \(k\) の互いに重ならない \(T\) の路からなる集合の最大の大きさを計算してください。 \(T\) が二分木だと仮定しないでください。次の例では \(k=3\) であり、アルゴリズムの出力は整数 \(8\) です。
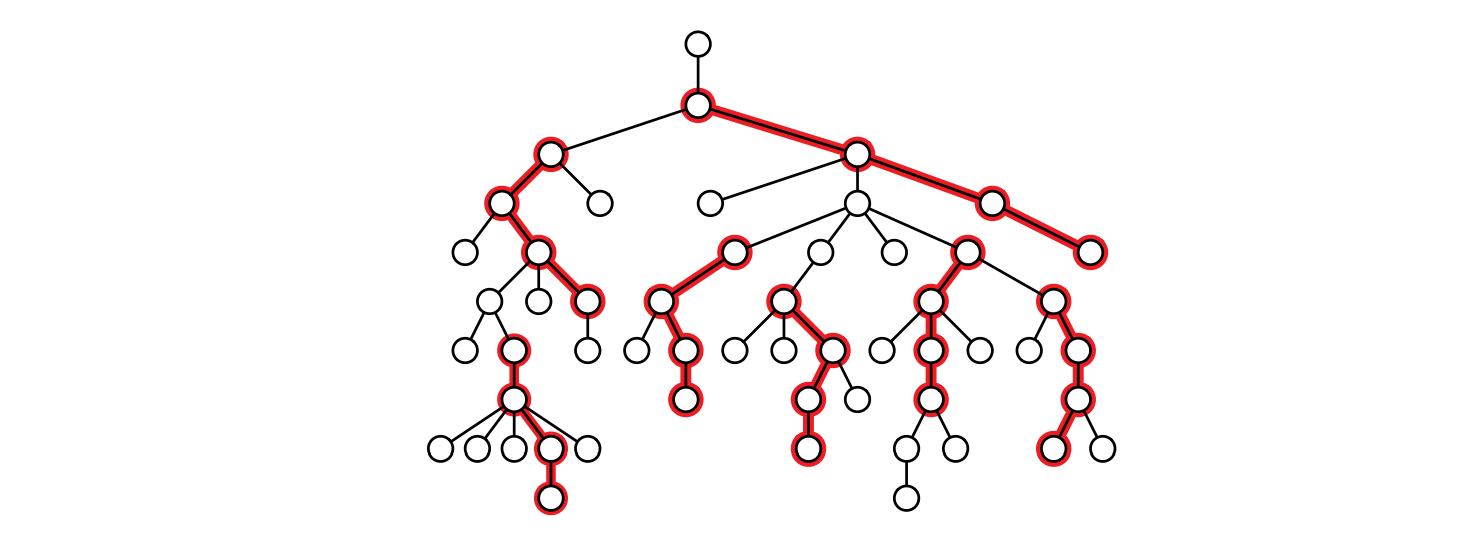 図 3.11長さが \(k=3\) である重ならない 7 つの道 (この集合は条件を満たす最大の集合ではない)
図 3.11長さが \(k=3\) である重ならない 7 つの道 (この集合は条件を満たす最大の集合ではない) -
\(T\) を \(n\) 頂点の根付き二分木、\(k \leq n\) を正の整数とします。 \(T\) の頂点のうち \(k\) 個に印をつけて、全ての頂点のなるべく近い祖先に印をつけた頂点があるようにしたいとします。きちんと言うと、\(T\) の頂点の部分集合 \(K\) に対するクラスタリングコストを次のように定義し、これを最小化します: \[ \mathit{cost}(K) = \max\limits_{v} \mathit{cost}(v, K) \] ここで \(\max\) は木に含まれる全ての頂点に関する最大値を表し、\(\mathit{cost}(v, K)\) は \(v\) から \(K\) に含まれる一番近い \(v\) の先祖までの距離です: \[ \mathit{cost}(v, K) = \begin{cases} 0 & \text{if } v \in K \\ \infty & \text{if } v \text{ が } T \text{ の根でかつ } v \notin K \\ 1 + \mathit{cost}(\mathit{parent}(v)) & \text{それ以外} \end{cases} \] この定義から、\(K\) が \(T\) の根を含まないならば \(\mathit{cost}(K) = \infty\) であることが分かります。
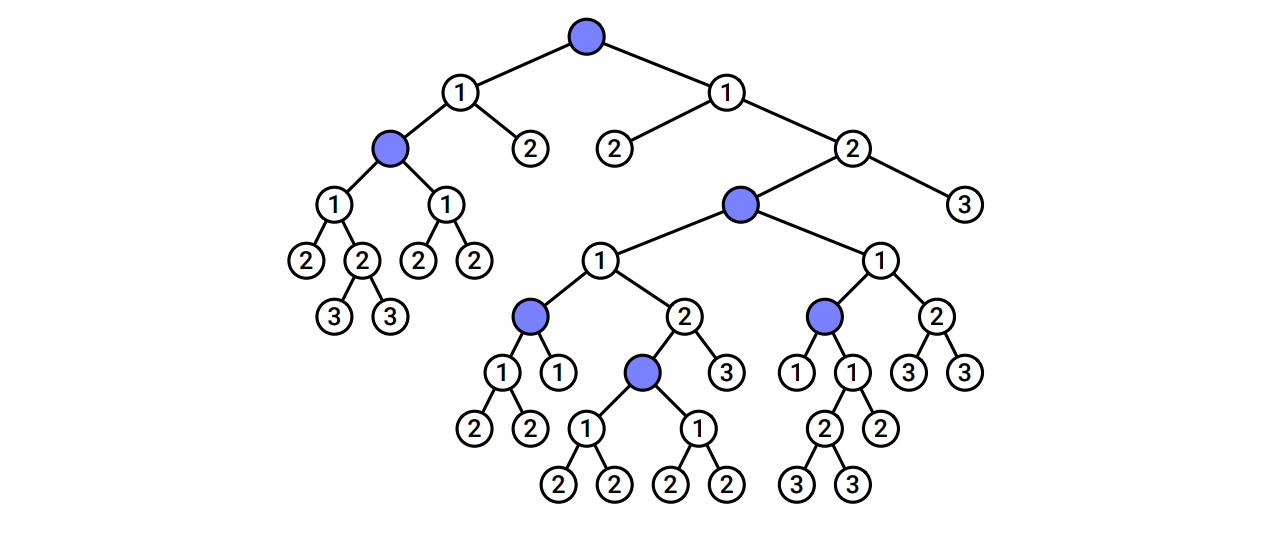 図 3.12二分木の頂点の部分集合 (大きさは \(5\) で、クラスタリングコストは \(3\))
図 3.12二分木の頂点の部分集合 (大きさは \(5\) で、クラスタリングコストは \(3\))-
❤ 木 \(T\) と整数 \(k\) が与えられたときに、\(k\) 頂点からなる \(T\) の頂点の部分集合の中でクラスタリングコストが最小のものを計算する動的計画法のアルゴリズムを説明してください。満点のためには、アルゴリズムの実行時間が \(O(n^{2}k^{2})\) であることが求められます。
-
木 \(T\) と整数 \(r\) が与えられたときに、クラスタリングコストが \(r\) 以下である \(T\) の頂点の部分集合で最小のものを計算する動的計画法のアルゴリズムを説明してください。満点のためには、アルゴリズムの実行時間が \(O(nr)\) であることが求められます。
-
(b) に対する答えを使うと (a) の問題に対する \(O(n^{2} \log n)\) 時間の答えを得られることを示してください。
-
-
この問題では与えられた二つの木に対する共通根付き部分木を求める問題を考えます。根付き木とは根と呼ばれる頂点を持つ連結非巡回グラフであることを思い出してください。根付き部分木とは、ある頂点とその全ての子孫からなる根付き木のことです。 "共通" の意味はどのような根付き木の組を同型 (isomorphic) とみなすかによって異なります。
-
二分木では各頂点が左の部分木と右の部分木を持っており、空の部分木も許されています。二つの二分木が同型とは、どちらも空であるか、そうでなければ左の部分木同士と右の部分木同士がどちらも同型であることを言います。二つの二分木が与えられたときに最大共通部分二分木を計算するアルゴリズムを説明してください。
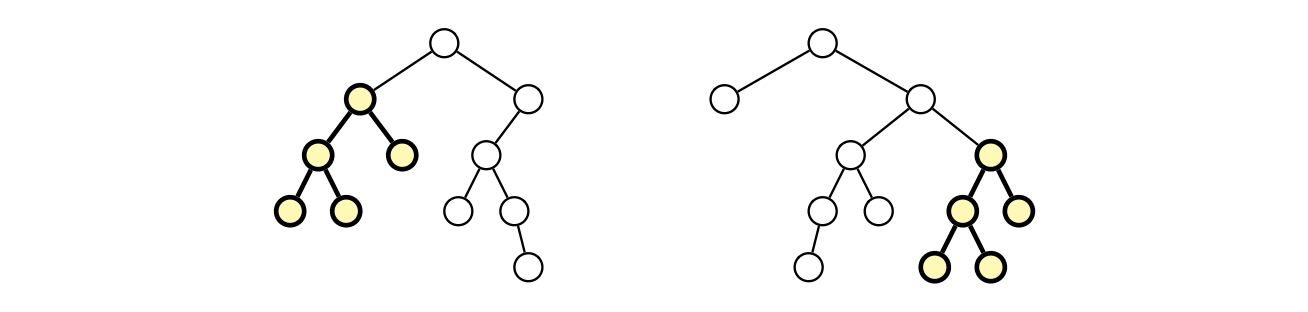 図 3.13二つの二分木 (最大共通部分二分木が強調してある)
図 3.13二つの二分木 (最大共通部分二分木が強調してある) -
順序付き根付き木 (ordered rooted tree) では各頂点が子の列を持っており、それぞれの子は順序付き根付き部分木の根です。二つの順序付き根付き木が同型とは、どちらも空であるか、そうでなければ全ての添え字 \(i\) について \(i\) 番目の部分木同士が同型であることを言います。二つの順序付き根付き木が与えられたときに最大共通順序付き根付き部分木を計算するアルゴリズムを説明してください。
-
♦ ❤ 順序無し根付き木 (unordered rooted tree) では各頂点が子の集合を持っており、それぞれの子は順序無し根付き木の根です。二つの順序無し根付き木が同型とは、どちらも空であるか、そうでなければ全ての添え字 \(i\) について \(i\) 番目の部分木同士が同型であるように二つの木の根の子を順序付けられることを言います。二つの順序無し根付き木が与えられたときに最大共通順序無し根付き部分木を計算するアルゴリズムを説明してください。
-
-
この問題では根無し木 ――連結非巡回無向グラフ―― の最適部分木を効率良く計算するアルゴリズムを考えます。根無し木の部分木とは任意の連結部分グラフのことです。
-
根無し木 \(T\) と辺の重みを与えられたとします。重みは正でもゼロでも負でもあり得るとしたとき、\(T\) 内の道であって最大の重みを持つものを求めるアルゴリズムを説明してください。
-
根無し木 \(T\) と頂点の重みを与えられたとします。重みは正でもゼロでも負でもあり得るとしたとき、\(T\) の部分木であって最大の重みを持つものを求めるアルゴリズムを説明してください。 [この問題は 2016 年の Google の面接試験で出題されました。]
-
\(T_{1}, T_{2}\) を任意の順序付き根無し木とします。つまり、各頂点に隣接する頂点の集合は well-defined な環状の順序を持っているということです。 \(T_{1}\) と \(T_{2}\) の最大共通順序付き部分木を求めるアルゴリズムを説明してください。
-
♦ ❤ \(T_{1}, T_{2}\) を任意の順序無し根無し木とします。 \(T_{1}\) と \(T_{2}\) の最大共通順序無し根無し部分木を求めるアルゴリズムを説明してください。
-
-
根付き木の根付きマイナー (rooted minor) とは部分列の自然な拡張です。根付き木 \(T\) の根付きマイナーとは一つ以上の辺を縮約 (contraction) してできる任意の木のことを言います。頂点 \(v\) とその親 \(u\) を結ぶ辺 \(u \to v\) を縮約すると、\(v\) の子が \(u\) の子となり、\(v\) は削除されます。また \(T\) の根は \(T\) の全ての根付きマイナーの根です。
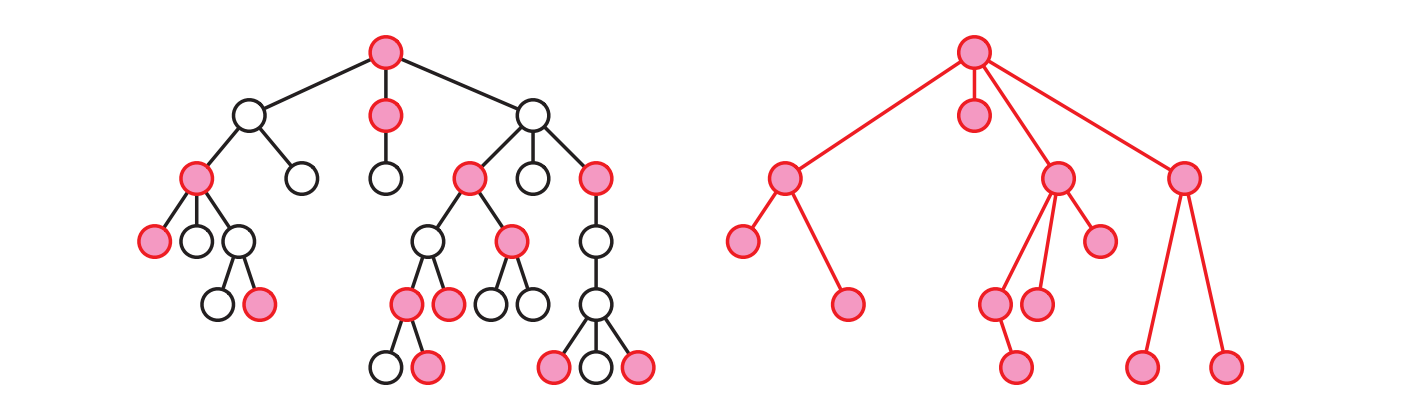 図 3.14根付き木とその根付きマイナーの一つ
図 3.14根付き木とその根付きマイナーの一つ-
\(T\) を頂点にラベルの付いた根付き木とします。 \(T\) の全ての頂点 \(x\) について、\(x\) の子が全て同じラベルを持っているとき、\(T\) は退屈である (boring) と言います (違う頂点の子は違うラベルを持っていて構いません)。与えられたラベル付き根付き木 \(T\) の退屈な根付きマイナーのうち最大のものを計算するアルゴリズムを説明してください。
-
\(T\) を頂点に数字のラベルが付いている根付き木とします。 \(T\) のヒープ順序付き (heap-ordered) 根付きマイナーのうち最大のものを計算するアルゴリズムを説明してください。つまり \(T\) の根付きマイナーを \(M\) とすると、アルゴリズムが返すのは、各頂点のラベルが子のラベルよりも小さいという条件を満たす \(M\) の中で最大のものです。
-
\(T\) を頂点に数字のラベルが付いている二分木とします。 \(T\) の二分探索順序付き (binary-search-ordered) 根付きマイナーのうち最大のものを計算するアルゴリズムを説明してください。つまり \(T\) の根付きマイナーを \(M\) とすると、アルゴリズムが返すのは、各頂点が最大で二つの子を持ち、\(M\) の通り掛け順の走査が (\(T\) の通り掛け順の走査の部分) 増加列となるような \(M\) のうち最大のものです。
-
根付き木が順序付いている (ordered) とは、各頂点の子が well-defined な左から右への順番を持っていることを言います。頂点が数字でラベル付けされた任意の順序付き木 \(T\) に対して、その最大二分探索順序付き根付きマイナーを求めるアルゴリズムを説明してください。アルゴリズムが答える根付きマイナー \(M\) の頂点における左から右への順序は \(T\) のものと一致している必要があります。
-
❤ 二つのラベル付けされた順序付き根付き木に対して、最大共通順序付き根付きマイナーを求めるアルゴリズムを説明してください。
-
♦ ❤ 二つのラベル付けされた順序無し根付き木に対して、最大共通順序無し根付きマイナーを求めるアルゴリズムを説明してください。 [ヒント: 動的計画法と最大フローを組み合わせてください。]
-
-
私のアルゴリズムの講義では、動的計画法の解答にそれが解いている再帰的な小問題に対する英語で書かれた仕様が含まれていない場合、それ以外の答案が完璧であったとしても自動的に点数がゼロになります。このポリシーを導入したところ、生徒が間違った (あるいは支離滅裂な) 動的計画法のアルゴリズムを提出する回数が激減し、成績が劇的に向上しました。[return]
-
Nadiria の歴史と文化および夢ドル紙幣の画像は http://moneyart.biz/dd/ から参照できます。[return]
-
北コースを使えばスピードがもっと出ますが、対決に使うには短すぎます。[return]
-
Vaikin's killometer にさらに上方向の移動を加えた場合、このゲーム (Vankin's Fathom?) は NP 困難となります。[return]
-
もっと洗練されたテクニックを使えば実行時間を \(O(n^{3 / 2} \log \log n)\) にできると私は信じていますが、まだ詳細を詰め切っていません。[return]
-
Sedgewick の提案したデータ構造は右の子が赤くてはいけないという制約を持っていましたが、まぁ、どうでもいいです。奇妙なことに、Andersson と Sedgewick は両人とも角度を測るときに時計周りに測るかそれとも反時計回りに測るか、冥王星が惑星がどうか、"lower rank" が意味するのが良いことなのかそれとも悪いことなのか、アヒルサイズの馬 100 匹と馬サイズのアヒル 1 匹だったらどちらと戦いたいかについては沈黙したままです。[return]
-
最悪探索時間 \(O(\log_{B} n)\) を保証するには、これらの他に二つの制約が必要となります: (1) 全ての葉が同じ深さを持つ (2) 根を除く全ての頂点が \(B / 2\) 個以上の鍵を持つ。しかしこの問題で考えているのは最悪探索時間ではなく合計探索時間なので、追加の制約は課しません。[return]
-
Q: どうしてあなたたち情報科学の教授は木の根が上にあると思っているのですか? A:外に出たことがないから![return]