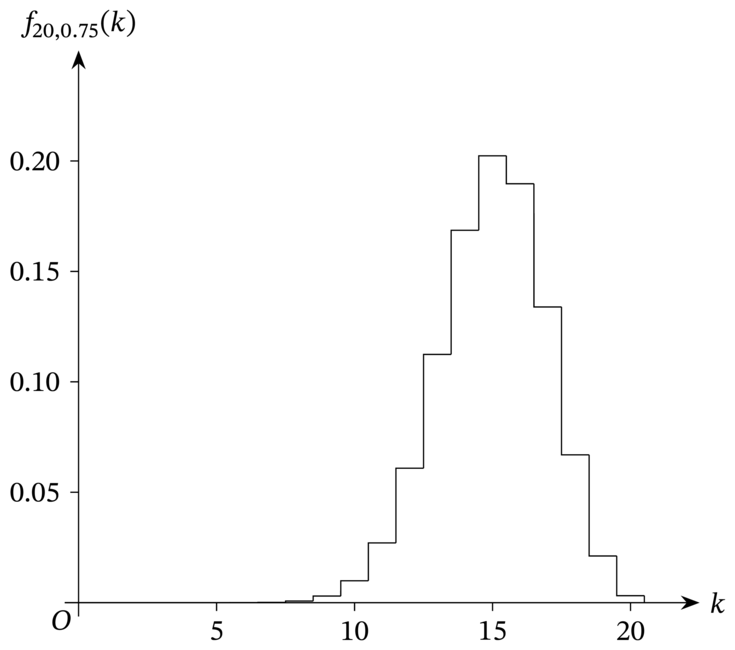19.3 確率の分布を表す関数
確率変数は結果に値を割り当てる。確率変数 \(R\) の確率密度関数 (probability density function, pdf) \(\operatorname{PDF}_{R}(x)\) は \(R\) によって値 \(x\) が割り当てられる結果が起こる確率 (\(R = x\) となる確率) を表現し、pdf と密接な関係を持つ累積分布関数 (cumulative distribution function, cdf) \(\operatorname{CDF}_{R}(x)\) は \(R\) によって \(x\) 以下の値が割り当てられる結果が起こる確率 (\(R \leq x\) となる確率) を表現する。標本空間が異なる確率変数でも、それぞれの値を取る確率が同じなら、それらの確率変数の pdf と cdf は同一になる。
\(R\) を確率変数、\(V\) を \(R\) の終域とする。次の関数 \(\text{PDF}_{R}\colon V \to [0, 1]\) を \(R\) の確率密度関数 (probability density function) と呼ぶ:
\(R\) の終域が実数の集合なら、次の関数 \(\operatorname{CDF}_{R}(x) \colon \mathbb{R} \to [0, 1]\) を \(R\) の累積分布関数 (cumulative distribution function) と呼ぶ:
この定義から、任意の確率変数 \(R\) に対する次の等式が分かる:
\(R\) はそれぞれの結果に値を割り当てるので、\(R\) の値域に含まれる値に割り当てられる結果の確率の和は、全ての結果の確率の和に等しいからである。
例えば、公平かつ独立な六面サイコロを \(2\) 個振る試行において、出た目の和を表す確率変数を \(T\) とする。この確率変数 \(T\) の値域を \(V\) とすれば \(V = \left\{ 2, 3, \ldots, 12 \right\}\) が成り立つ。\(T\) の確率密度関数 \(\operatorname{PDF}_{T}(x)\) を表すグラフを図 \(\text{19.1}\) に示す。グラフの山なりの形からは、目の和が \(7\) になる確率が一番高く、\(7\) から離れるほど確率が低くなることが分かる。\(2\) 個の六面サイコロを振ったときの目の和は \(V = \left\{ 2, 3, \ldots, 12 \right\}\) のちょうど一つの要素に等しいので、グラフに示された長方形の面積の和は \(1\) になる。
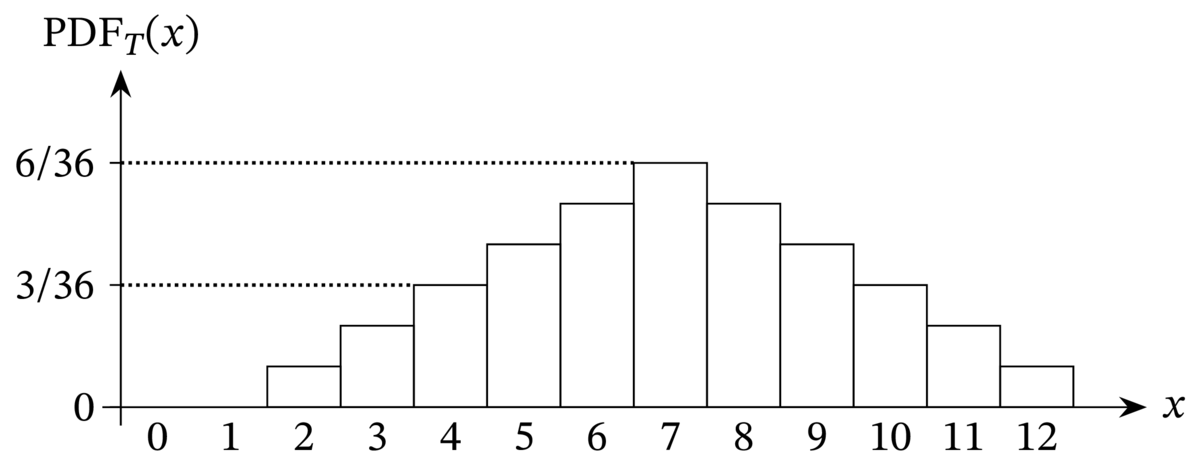
\(T\) の累積分布関数 \(\operatorname{CDF}_{T}(x)\) のグラフを図 \(\text{19.2}\) に示す。\(\operatorname{CDF}_{T}(x)\) は \(x\) 以下の全ての \(i\) に対する \(\operatorname{PDF}_{T}(i)\) の和に等しいので、確率密度関数のグラフにおける長方形の面積を左から足していけば計算できる。この事実は定義からも分かる:
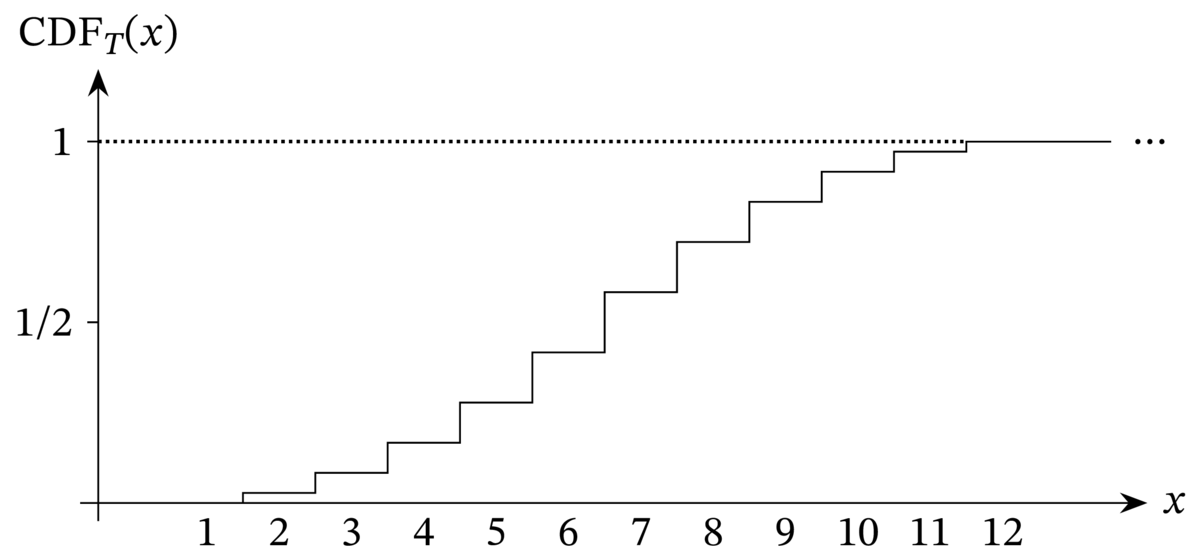
定義からは次の関係も分かる:
\(\operatorname{PDF}_{R}\) と \(\operatorname{CDF}_{R}\) から得られる \(R\) に関する情報は同じであり、一方が分かれば他方も分かる。そのため、どちらを使っても構わない。
非常に興味深い事実として、多くの確率変数が同一の確率密度関数と累積分布関数を持つことがある。言い換えれば、\(R\) と \(S\) が異なる確率空間上の確率変数だったとしても、次の等式が成り立つケースがよくある:
また、次の点も重要である: 確率密度関数と累積分布関数はいずれも試行の標本空間と直接の関係を持たない。そのため、標本空間を明示せずとも確率変数が取る値とその確率の関係を考えることができる。この値と確率の関係を確率分布 (probability distribution) と呼ぶ。確率密度関数と累積分布関数はいずれも確率分布の表現である。特定の確率空間上の確率変数 \(X\) が定める確率分布を \(P\) と表すとき、その確率空間において確率変数 \(X\) は確率分布 \(P\) に従う (follow) と言う。考えている確率分布は文脈から明らかなことが多いので、よく省略される。
非常によく現れるために特別な名前を与えられた確率分布がいくつかある。例えば、情報科学で間違いなく最も重要な分布は Bernoulli 分布、一様分布、二項分布、幾何分布である。以降では、これらの頻繁に登場する確率分布を詳しく見ていく。なお、これらの「〇〇分布」の多くは単一の確率分布ではなく、パラメータを持った確率空間の族 (集まり) である。しかし確率分布の族とその要素をはっきりと区別しない場合も多い。例えば「確率分布 \(X\) が確率分布の族 \(\mathcal{P}\) に従う」は「確率変数 \(X\) が従う確率分布 \(P \in \mathcal{P}\) が存在する」を意味する。
19.3.1 Bernoulli 分布
Bernoulli 分布 (Bernoulli distribution) は Bernoulli 変数が従う確率分布である。つまり、Bernoulli 分布の確率密度関数は \(f_{p} \colon \{0,1\} \to [0,1]\) の形をしており、次の規則を満たす:
ここで \(p \in [0, 1]\) および \(q ::= 1 - p\) である。対応する累積分布関数 \(F_{p} \colon \mathbb{R} \to [0, 1]\) は次の関係を満たす:
19.3.2 一様分布
終域に属する全ての値が同じ確率を持つ確率変数を一様 (uniform) と呼び、一様確率変数が従う確率分布を一様分布 (uniform distribution) と呼ぶ。一様確率変数の終域が \(n\) 要素集合 \(V\) なら、対応する一様分布は次の形をした確率密度関数を持つ:
そして、全ての \(v \in V\) が次の等式を満たす:
さらに \(V\) の要素が全て実数なら、それらを昇順に並べたものを \(a_{1}\), \(a_{2}\), \(\ldots\), \(a_{n}\) とするとき、累積分布関数は次の関数 \(F \colon \mathbb{R} \to [0, 1]\) である:
一様分布は様々な問題で登場する。例えば、公平なサイコロを振って出た目を表す確率変数は \(\left\{ 1, 2, \ldots, 6 \right\}\) 上の一様分布に従う。また、指示確率変数は確率密度関数が \(f_{1/2}\) のとき一様となる。
19.3.3 大きい数当てゲーム
定義が続いてうんざりしてきたと思うので、一休みしてゲームをしよう! 机の上に封筒が二つ置いてある。封筒の中には \(0\), \(1\), \(\ldots\), \(99\) のいずれかの数字が一つ書かれた紙が入っており、それぞれの封筒に含まれる紙に書かれた数字は異なる。このゲームの勝利条件は大きな数字が含まれる封筒を言い当てることである。ただし、解答する前に片方の封筒に含まれる数字を確認できるとする。
例えば「封筒をランダムに選択する」という戦略だと \(50\%\) の確率で大きな数字が含まれる封筒を選択できる。これより優れた、\(50\%\) より高い勝率が保証される戦略は存在するだろうか?
確認した数字を利用する次の戦略を考えるかもしれない: 例えば、確認した封筒に含まれる数字が \(12\) だったとする。\(12\) は \(0\), \(1\), \(\ldots\), \(99\) の中では小さい数字だから、もう一方の封筒に含まれる数字は \(12\) より大きい可能性が高い。しかし、出題者はそのことを読んで両方の封筒に小さな数字を入れる可能性がある。そのとき、この戦略は上手く機能しない!
言及していなかった重要な仮定が一つある: 封筒に含まれる数字はランダムでない可能性がある。出題者はプレイヤーの戦略を知っていて、その上で封筒に入れる数字を選択する。封筒に含まれる数字がランダムに選ばれるのは、そうしたときプレイヤーが勝利する確率が低くなるときだけである。
平均的に勝利可能な戦略
驚くべきことに、この出題者に有利な条件の下でも \(50\%\) より高い確率で勝利できる戦略が存在する。
二つの封筒に含まれる数字の間にある実数 \(x\) を知っていると仮定しよう。このとき、確認した封筒に含まれる数字が \(x\) より大きいなら、その確認した封筒を解答すべきだと分かる。逆に確認した封筒に含まれる \(x\) より小さいなら、確認していない方の封筒を解答すべきだと分かる。つまり \(x\) が分かっていれば必ずゲームに勝利できる。
この素晴らしい戦略の欠点は、存在の仮定されている \(x\) が実際には分からないことである。なら使えないのかと思うかもしれないが、この難局を打破する方法がある: \(x\) を推測すればいい! \(x\) を正しく推測できた場合は必ず勝利できる。さらに、推測が間違っていても失うものはない: その場合でも勝率は \(50\%\) で、ランダムに選択する戦略と変わらない。二つの場合を合わせた平均の勝率は \(50\%\) を超える。
確率に関する「直感的」な議論は明らかに思えても間違っていることが多い。上記の議論は逆である: いまひとつ納得できないかもしれないが、実際には正しい。この戦略の有効性を示すために、厳密な方法で議論を定式化してみよう ── その中で、あなたが取るべき具体的な手順も明らかになる。
解析
問題を一般化して、出題者は \([0..n]\) に含まれる整数を二つ選んで封筒に入れると仮定する。小さい方の整数を \(L\) として、大きい方の整数を \(H\) とする。
\(L\) と \(H\) の間にある実数 \(x\) を推測したい。\(x\) が \(L\) または \(H\) に等しい可能性があると議論が複雑になるので、\(x\) の選択肢は整数を \(1/2\) だけずらした次の値とする:
これらの値の中から \(x\) を選ぶとき、どのような確率分布を使うべきだろうか?
最良の結果は一様分布を採用する ── 全ての値に等しい確率を割り当てる ── とき得られる。厳密でない説明は次の通りである: もし確率が少しでも偏っていたら、封筒に入れる二つの値の間に \(x\) として選ばれにくい値があるときプレイヤーの勝率が低下する。例えば \(50 \frac{1}{2}\) が選ばれる確率が低いなら、出題者は常に \(50\) と \(51\) を封筒に入れるだろう。
\(x\) の値を選択したら、一方の封筒を開けて整数 \(T\) を確認する。もし \(T > x\) なら開けた方の封筒を解答し、\(T < x\) なら開けていない方の封筒を解答する。
最後に、この戦略を使ったとき勝利する確率を計算しよう。お馴染みの四ステップ法と樹形図が利用できる。

ステップ 1: 標本空間を見つける
プレイヤーが選択する \(x\) の値は「小さすぎる (\(x < L\))」「大きすぎる (\(H < x\))」「正しい (\(L < x < H\))」のいずれか、確認する封筒は「小さい数字が含まれる (\(T = L\))」「大きい数字が含まれる (\(T = H\))」のいずれかなので、図 \(\text{19.3}\) に示すように全部で \(6\) 通りの結果が考えられる。
ステップ 2: 注目する事象を定義する
注目しているのは樹形図で「勝利」と書かれた \(4\) 個の結果からなる事象である。
ステップ 3: 結果の確率を計算する
まず、辺の確率を計算する。\(x\) の全ての選択肢には等しい確率が割り当てられるので、\(L/n\) の確率で \(x < L\) が成り立ち、\((n - H)/n\) の確率で \(H < x\) となり、\((H - L)/n\) の確率で \(L < x < H\) となる。続いて、二つの封筒は等しい確率で選択される。根から葉への路に含まれる辺の確率を乗じると図 \(\text{19.3}\) にある結果の確率が計算できる。
ステップ 4: 事象の確率を計算する
プレイヤーが勝利する事象の確率は、その事象に含まれる \(4\) 個の結果の確率の和に等しい:
最後の変形では、\(L\) と \(H\) は \(L < H\) を満たす異なる整数なので \(1 \leq H - L\) が成り立つことを用いた。
以上で次の事実が明らかになった: 封筒にどんな数字が入っていたとしても、この戦略を使うとき勝率は \(50\%\) を超える! 封筒に入れる数字の選択肢が \(0\), \(1\), \(\ldots\), \(99\) のとき、勝率は \(1/2 + 1/200 = 50.5\%\) 以上となる。もし選択肢が \(0\), \(1\), \(\ldots\), \(9\) なら、勝率は \(55\%\) まで上昇する。これはラスベガスの基準では非常に優れた値である。
乱択アルゴリズム
以上の戦略は乱択アルゴリズム (randomized algorithm) の例である ── 乱数 (ランダムに選択される数字) が処理の流れを決定する。乱数を活用するプロトコルやアルゴリズムは情報科学で非常に重要であり、知られている最良の解法が乱数生成器を利用する問題は数多く存在する。
例えば、共有バスやイーサネットにブロードキャストを送信するタイミングを決定する最も一般的なプロトコルでは、指数バックオフ (exponential backoff) と呼ばれる乱択アルゴリズムが利用される。また、現実のプログラムで最もよく利用されるソートアルゴリズムであるクイックソート (quicksort) も乱数を利用する。アルゴリズムの講義を取れば他にも多くの例を見つけられるだろう。それぞれのケースで、ランダム性はアルゴリズムが高速に実行される確率 (あるいは望ましい結果が得られる確率) を大きくするために利用される。
19.3.4 二項分布
情報科学で頻繁に利用される三つ目の確率分布は二項分布 (binomial distribution) である。二項分布に従う確率変数の標準的な例として「コインを独立に \(n\) 回投げたとき、表が出る回数」がある。投げるコインが公平なら、この確率変数が従う確率分布は不偏二項分布 (unbiased binomial distribution) と呼ばれる。その確率密度関数 \(f_{n} \colon [0..n] \to [0, 1]\) は次の等式を満たす:
この等式は、\(k\) 個の「表」と \(n - k\) 個の「裏」を並べた \(n\) 回のコイン投げの結果を表す長さ \(n\) の列が \(\binom{n}{k}\) 個あり、それぞれの確率が \(2^{-n}\) である事実から分かる。
\(f_{20}(k)\) のグラフを図 \(\text{19.4}\) に示す。最も確率が高いのは表が出る回数 \(k\) が \(10\) のときであり、そこから離れると確率は急激に小さくなる。中央と比べて確率が小さい左右の端の部分を分布の裾 (tail) と呼ぶ。
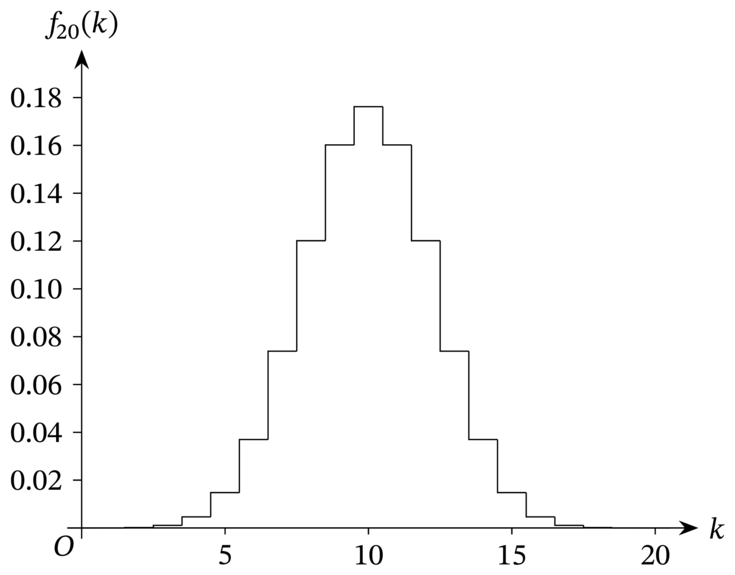
情報科学を含む多くの分野では、確率の解析が最終的に二項分布の裾の高さに小さな上界を与える問題になることが多い。より具体的に言えば、何か悪い事態が起きる確率が非常に小さいことの確認が確率の解析によって示される。例えばサーバーや通信リンクで過負荷が起きる確率や、乱択アルゴリズムの実行時間が極端に長くなる (あるいは間違った値を答える) 確率は小さいと示せることが望ましい。
二項分布では裾の高さが非常に速く小さくなる。例えば、公平なコインを \(100\) 回投げたとき表が出る回数が \(25\) 以下となる確率は \(1/3{,}000{,}000\) より小さい。さらに、表がちょうど \(25\) 回出る確率は「表がちょうど \(24\) 回出る確率、表がちょうど \(23\) 回出る確率、 \(\cdots\) 、表が一度も出ない確率」の和を倍にした値にほぼ等しい。
一般二項分布
表が出る確率が \(p\) で裏が出る確率が \(q ::= 1 - p\) の公平とは限らないコインを \(n\) 回投げたときに表が出る回数を表す確率変数が従う確率分布は一般二項分布 (general binomial distribution) と呼ばれる。この確率分布の確率密度関数 \(f_{n,p} \colon [0,n] \to [0,1]\) は次の等式を満たす:
ここで \(n \in \mathbb{N}^{+}\) および \(p \in [0, 1]\) である。この等式の成立は、\(k\) 個の「表」と \(n - k\) 個の「裏」を並べた \(n\) 回のコイン投げの結果を表す長さ \(n\) の列が \(\binom{n}{k}\) 個あり、それぞれの確率がここでは \(p^{k}q^{n-k}\) である事実から分かる。
例えば、\(n = 20,\ p = 0.75\) とした \(f_{n,p} (k)\) のグラフを図 \(\text{19.5}\) に示す。このグラフを見ると、表が出る回数 \(k\) は \(15\) となる確率が最も高いと分かる。意外な結果ではないだろう。ここでも、\(k\) が \(15\) から離れると確率はすぐに小さくなる。